在上一篇文章里,我讨论了INTERSECT设置操作的基础,它和INNER JOIN的区别,还有为什么需要好的索引设计支持。今天我想谈下SQL Server里并未实现的INTERSECT ALL操作。
INTERSECT ALL是SQL特性的一部分,但SQL Server并不考虑它。和INTERSECT操作的区别非常简单:INTERSECT ALL不会剔除重复行。在SQL Server里的好处是你可以模拟INTERSECT ALL。我们来试下,再次创建2个表,并插入一些行。
1 -- Create the 1st table 2 CREATE TABLE t1 3 ( 4 Col1 INT, 5 Col2 INT, 6 Col3 INT 7 ) 8 GO 9 10 -- Create the 2nd table 11 CREATE TABLE t2 12 ( 13 Col1 INT, 14 Col2 INT 15 ) 16 GO 17 18 -- Insert some records into both tables 19 INSERT INTO t1 VALUES (1, 1, 1), (2, 2, 2), (2, 2, 2), (3, 3, 3) 20 INSERT INTO t2 VALUES (2, 2), (2, 2), (3, 3) 21 GO
你会发现,第2个表包含重复记录——在表里值为2的记录出现了2次。现在当你在2个表之间进行INTERSECT,值为2的记录在结果集只出现1次。重复行被剔除了。
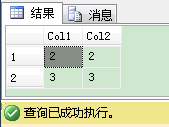
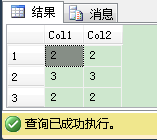
如果你想保留重复行,你必须使它们唯一。这里的一个方法是使用自SQL Server 2005后引入的ROW_NUMBER()窗口函数。使用这个函数你为每个重复记录生成唯一的行号。因此你的重复记录变成了唯一,“重复”行如期望的返回2次。下列代码显示了这个技术:
1 -- You can preserve duplicate rows by making them unique with the ROW_NUNBER() Windowing Function. 2 WITH IntersectAll AS 3 ( 4 SELECT 5 ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY (SELECT 0)) AS RowNumber, 6 Col1, 7 Col2 8 FROM t1 9 10 INTERSECT 11 12 SELECT 13 ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY (SELECT 0)) AS RowNumber, 14 Col1, 15 Col2 16 FROM t2 17 ) 18 SELECT Col1, Col2 FROM IntersectAll 19 GO
小结
SQL Server里INTERSECT操作的一个副作用是重复行会剔除不会在结果集里返回。如果你想保留它们,你需要使它们唯一,例如应用ROW_NUMBER() 计算。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/02/16/intersect-sql-server-2/