计划缓存(Plan Cache)
如果SQL Server已经找到一个好的方式去执行一段代码时,应该把它作为随后的请求重用,因为生成执行计划是耗费时间且资源密集的,这样做是有有意义的。
如果没找到被缓存的计划,然后命令分析器(Command Parser)在T-SQL基础上生成一个查询树(query tree)。查询树(query tree)的内部结构是通过树上的每个结点代表查询中需要的执行操作。这个树然后被传给查询优化器(Query Optimizer)去处理。我们的简单查询没有一个存在的计划,因此一个查询树(query tree)会被创建,然后传给查询优化器(Query Optimizer)。
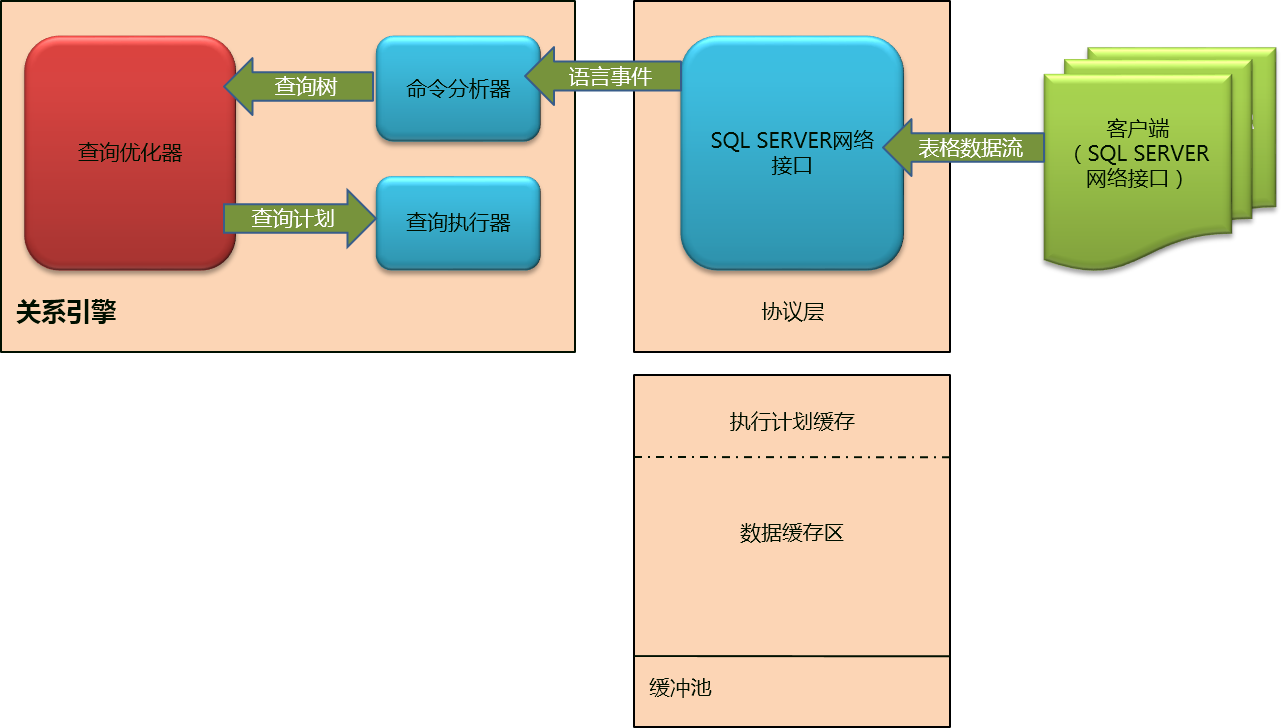
上图展示了命令分析器(Command Parser)是用来检查现存执行计划的计划缓存(plan cache),因为在缓存里没找到我们查询的任何信息,还有从命令分析器(Command Parser)输出传给优化器的查询树(query tree)。
查询优化器(Query Optimizer)是被SQL Server团队视为最有价值的财产,也是产品中最复杂、机密的部分之一。幸运的是,只有底层的算法和源代码被很好保护(即使在微软内部),优化器如何工作才能被研究和监视。
这个所谓的基于成本(cost-based)的优化器,意味要去评估执行查询的各种方式,然后选择被认为拥有最小成本的方式去执行。执行方式以查询计划(query plan)实现并从查询优化器(Query Optimizer)输出。
基于刚才的介绍,你认为优化器的工作是找到最好的查询计划会被原谅的,因为那看起来是很明显的设想。然而它的实际工作是在一段时间内找到好的计划,而不是最佳计划。优化器的目标通常被描述为找最有效率的计划。
如果优化器每次都尝试去找最好的计划,比起执行一个慢的计划,找个最好的计划花费的时间更长(一些内建的试探法实际上在保证优化器从不花更长的时间找到好计划,而是就找一个计划并执行它)。
优化器同样在成本的基础执行多级优化,在每一阶段增加更多可用选择项来找更好的计划。当一个好计划被找到时,优化器就停在那一阶段了。
第1阶段被称之为预优化,当语句是足够简单而只有一个最佳计划时,在第一阶段就退出剩下的步骤,移除额外成本需要。没有join的基本查询被认为简单,计划成本产出为0,然后被提及为普通计划(trivial plans)。
优化实际上开始的下一阶段包含三个查找时期:
- 第0时期——这个时期优化器会找内循环连接(nested loop joins)且不考虑并行运算符(parallel operators)。
如果已经找到的计划成本小于0.2,优化器会停在这里。在这个阶段生成的计划称为事务处理(transaction processing)或简称TP计划。
- 第1时期——第1时期使用可用优化规则的子集来找常用格式(common patterns)的已有计划。
如果已经知道的计划成本小于1.0,优化器会停在这里。这个阶段生成的计划被称为快速计划(quick plans)。
- 第2时期——在这个最后时期优化器全力以赴(pulls out all the stops)使用它所有的优化规则。它同样也会找下并行(parallelism)和索引视图(indexed views)(如果你运行的是企业版(Enterprise Edition))。
第2时期的完成是找到计划的成本对优化需要的时间之间的平衡。在这个时期生成的计划有完全级别(level of "Full")的优化。
它的花费需要多少?
这里提及的花费不能用多少秒或其他有意义的表达来衡量;它只是标记代表计划资源消耗值的一个任意数。然而,在早期的微软SQL Server世界里,它的起源是在桌面电脑上的基准检查程序(benchmark)(跑分)。
在计划里,每个运算符都有一个底线成本,然后用它来乘以行的大小和预计行数来获得那个运算符的成本,计划成本就是这些所有运算符的成本。
因为成本来自于底线值且与你的硬件速度无关,在每个SQL Server装置(同比版本 like-for-like version。博主注:与版本无关。)里生成每个计划的成本是一样的。
因为我们的SELECT查询非常简单,它退出在预优化时期的操作,因为这个计划对优化器非常明显(一个普通计划)。现在已经有查询计划了,它向查询执行器(Query Executor)去执行。
查询执行器(Query Executor)
查询执行器的工作是不释自明的,它执行查询。更准确的说,它通过干完包含与存储引擎相互作用的检索或修改数据的每一步来执行查询。
(此处有信息需要完善…………)
这个SELECT查询需要检索数据,因此请求传给存储引擎(Storage Engine)通过OLE DB接口传给存取方法(Access Methods)。
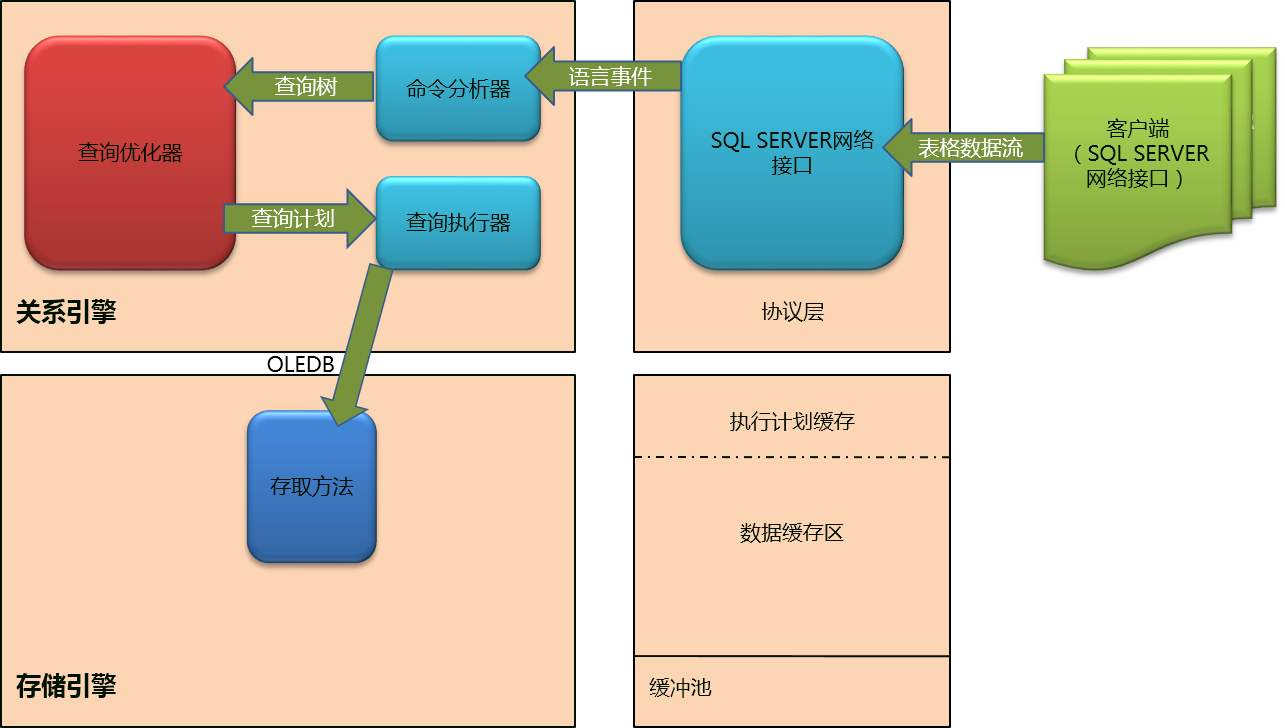
上图展示了作为优化器的输出的执行计划(query plan)正传给查询执行器(Query Executor),同时引入了存储引擎(Storage Engine),它被查询执行器(Query Executor)通过OLE作为接口给存取方法(Access Methods)。
存取方法(Access Methods)
存取方法是为你数据和索引提供存储结构,还有通过数据检索或数据修改接口的一批代码。它包含检索数据的所有代码单本身不执行操作,它向缓存区管理器(Buffer Manager)传递请求。
假设我们的SELECT语句需要读取一些记录行的数据刚好在一页。存取方法(Access Methods)的代码会让缓存区管理器(Buffer Manager)检索页,因此它可以准备一个OLE DB的记录集传回给关系引擎(Relational Engine)。
缓存区管理器(Buffer Manager)
缓存区管理器(Buffer Manager),如名所示,管理缓冲池(buffer pool),它代表着SQL Server的主要内存使用。如果你需要从页读一些记录行(当我们谈论UPDATE查询时会提及修改数据),缓存区管理器(Buffer Manager)在缓冲池(buffer pool)检查数据缓存看看在内存里是否有被缓存的这页。如果这页已被缓存了,结果就会传回给存取方法(Access Methods)。
如果这页没被缓存,然后缓存区管理器(Buffer Manager)从磁盘里拿这页,把它放入数据缓存(Data Cache),然后把结果传回给存取方法(Access Methods)。
你这里要记住的要点是你永远只和内存中的数据打交道。在作为记录集返回前,你请求的每个新的数据读取,首先从磁盘读取,然后写回内存(数据缓存(the data cache))。
这就是为什么SQL Server需要在内存里保持最小级别的可用页面;如果第一时间在缓存里没有空间来放数据,你就不能读取任何新数据。
存取方法(Access Methods)代码决定SELECT查询需要一个新页,因此它向缓存区管理器(Buffer Manager)拿。缓存区管理器(Buffer Manager)检查它是否已在数据缓存(data cache),如果没找到的话就从磁盘加载到缓存。
数据缓存(Data Cache)
数据缓存一直是缓冲池(buffer pool)最大一部分;因此也是在SQL Server最大内存用户。这里每个从磁盘读取的数据页在被用之前都会被写回。
这个sys.dm_os_buffer_descriptors动态管理视图(DMV)每一行代表当前内存持有的每个数据页,你可以用这个脚本看看在数据缓存区(Data Cache)每个数据库占用多少空间:
1 SELECT count(*)*8/1024 AS 'Cached Size (MB)' 2 ,CASE database_id 3 WHEN 32767 THEN 'ResourceDb' 4 ELSE db_name(database_id) 5 END AS 'Database' 6 FROM sys.dm_os_buffer_descriptors 7 GROUP BY db_name(database_id),database_id 8 ORDER BY 'Cached Size (MB)' DESC
输出结果看起来会类似如下:
Cached Size (MB) Database
3287 People
34 tempdb
12 ResourceDb
4 msdb
这个例子里,People数据库在数据缓存(Data Cache)里有3287 MB数据页。
页在缓存里停留时间量由最近最少使用(least recently used:LRU)策略决定。
(此处有信息待完善………………)
一个简单SELECT语句(查询)生命周期总结

SELECT查询的整个生命周期在这里被介绍:
- 在客户端的SQL Server网络接口(SNI)与在SQL Server使用例如TCP/IP的网络协议的网络接口(SNI)建立连接。然后在TCP/IP连接上建立与TDS终结点的联系并发送SELECT语句作为TDS消息发送给SQL Server。
- 在SQL Server上的SNI把TDS消息拆包,读取SELECT语句,传送一个“SQL命令”给命令分析器。
- 命令分析器在缓冲池检查计划缓存是否存在,与语句匹配的可用查询计划被命令分析器接收。如果没有找到它,基于SELECT语句创建查询树传给优化器来生成查询计划。
- 优化器在预编译生成零成本计划或普通计划,因为这个语句太简单了。生成的查询计划然后传给查询执行器去执行。
- 在执行时,查询执行器决定读取需要的数据来完整这个查询计划,因此通过OLE DB接口把请求传给在存储引擎里的存取方法。
- 存取方法需要从数据库里读一个页来完成来自查询执行器的请求,它让缓存区管理器来提供这个页。
- 缓存区管理器检查数据缓存看看它在缓存里是否已有。它不在缓存,因此从磁盘里拿这个页,放入缓存,传回给存取方法。
- 最后,存取方法把结果集送回给关系引擎发回给客户端。