1.Spark是什么
Spark是一个快速且通用的集群计算平台
2.Spark的特点
1)Spark是快速的
Spark扩充了流行的Mapreduce计算模型
Spark是基于内存的计算
2)Spark是通用的
Spark的设计容纳了其它分布式系统拥有的功能
批处理,迭代式计算,交互查询和流处理等
3)Spark是高度开放的
Spark提供了Python,Java,Scala,SQL的API和丰富的内置库。
Spark和其它的大数据工具整合的很好,包括hadoop,kafka等
3.Spark的组件
Spark包括多个紧密集成的组件

Spark Core:
包含Spark的基本功能,包含任务调度,内存管理,容错机制等
内部定义了RDDs(弹性分布式数据集)
提供了很多APIs来创建和操作这些RDDs
应用场景,为其他组件提供底层的服务
Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样
应用场景,企业中用来做报表统计
Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时流数据
应用场景,企业中用来从Kafka接收数据做实时统计
MLlib:
一个包含通用机器学习功能的包,Machine learning lib
包含分类,聚类,回归等,还包括模型评估和数据导入。
MLlib提供的上面这些方法,都支持集群上的横向扩展。
应用场景,机器学习。
Graphx:
是处理图的库(例如,社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
应用场景,图计算。
Cluster Managers:
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
4.紧密集成的优点
Spark底层优化了,基于Spark底层的组件也得到了相应的优化。
紧密集成,节省了各个组件组合使用时的部署、测试等时间。
向Spark增加新的组件时,其它组件,可立刻享用新组件的功能。
5.Spark与Hadoop的比较
Hadoop应用场景:离线处理、对时效性要求不高
Spark应用场景:时效性要求高的场景、机器学习等领域
Doug Cutting的观点:这是生态系统,每个组件都有其作用,各善其职即可。Spark不具有HDFS的存储能力,要借助HDFS等持久化数据。大数据将会孕育出更多的新技术。
6.Spark运行环境
Spark是Scala写的,运行在JVM上,所以运行环境Java7+
如果使用Python API,需要安装Python2.6+或者Python3.4+
版本对应:Spark1.6.2 - Scala2.10 Spark2.0.0 - Scala2.11
7.Spark安装
Spark下载地址:http://spark.apache.org/downloads.html 注:搭Spark不需要Hadoop,如有hadoop集群,可下载相应的版本。
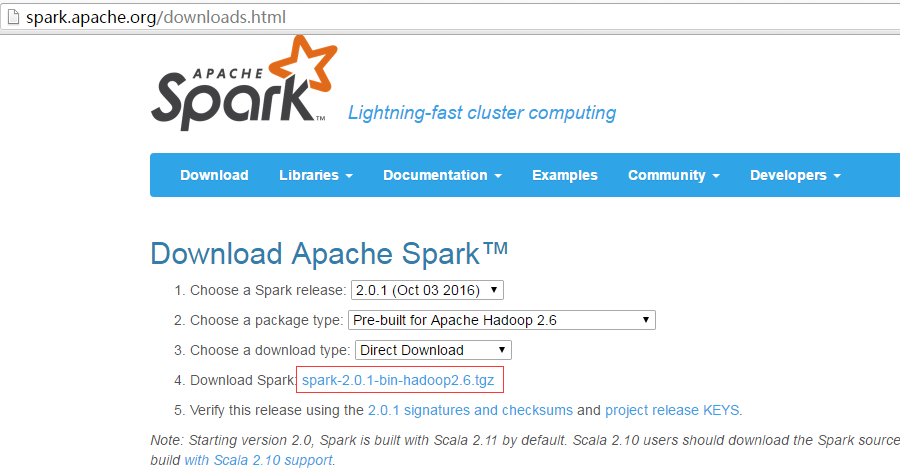
这里安装在CentOS6.5虚拟机上,将下载好的文件上传虚拟机,并执行解压:tar -zxvf spark-2.0.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
这里以Scala shell为例,演示读取本地文件并进行操作:
进入Scala shell:./spark-shell
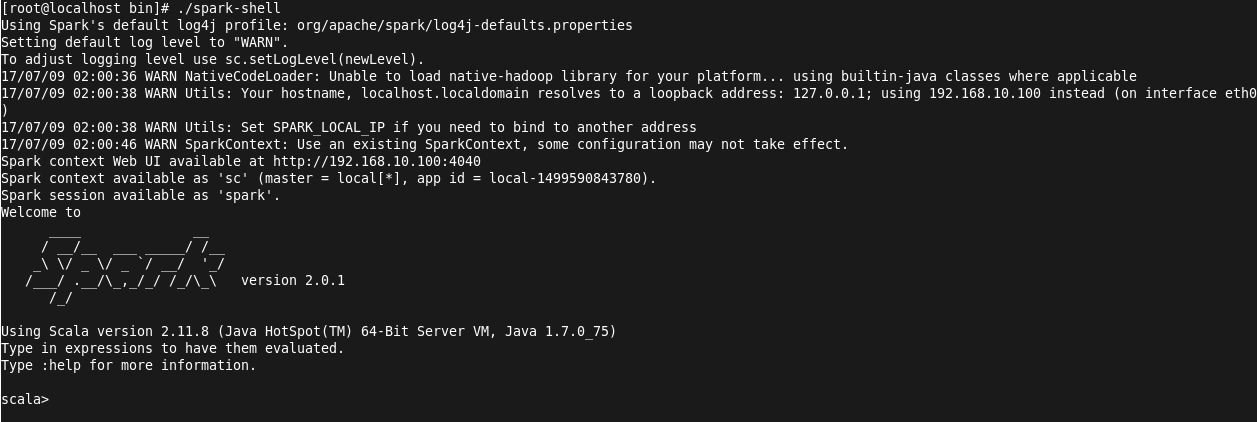
创建测试文件helloSpark并输入内容:
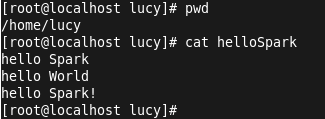
输入val lines=sc.textFile("/home/lucy/hellospark") 加载文件内容,输入lines.count()进行统计行数: ( 注:sc为spark content)
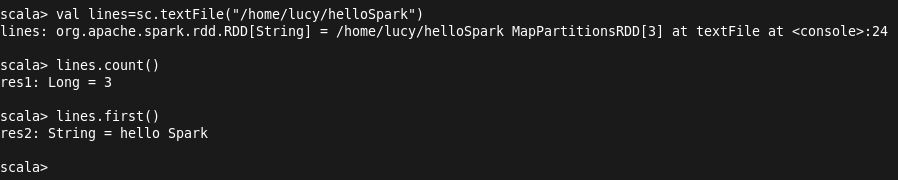
ssh的配置:(ssh localhost需要输入密码,这在运行spark程序时是不可以的)
ssh-keygen (生成秘钥)
.ssh目录下cat xxx_rsa.pub> authorized_keys
chmod 600 authorized_keys
8.Spark开发环境搭建
Scala 下载地址: http://www.scala-lang.org/download/2.11.6.html 注:默认安装选项会自动配置环境变量,安装路径不能有空格。
IntelliJ IDEA 下载地址:https://www.jetbrains.com/idea/
注册码地址:http://idea.lanyus.com
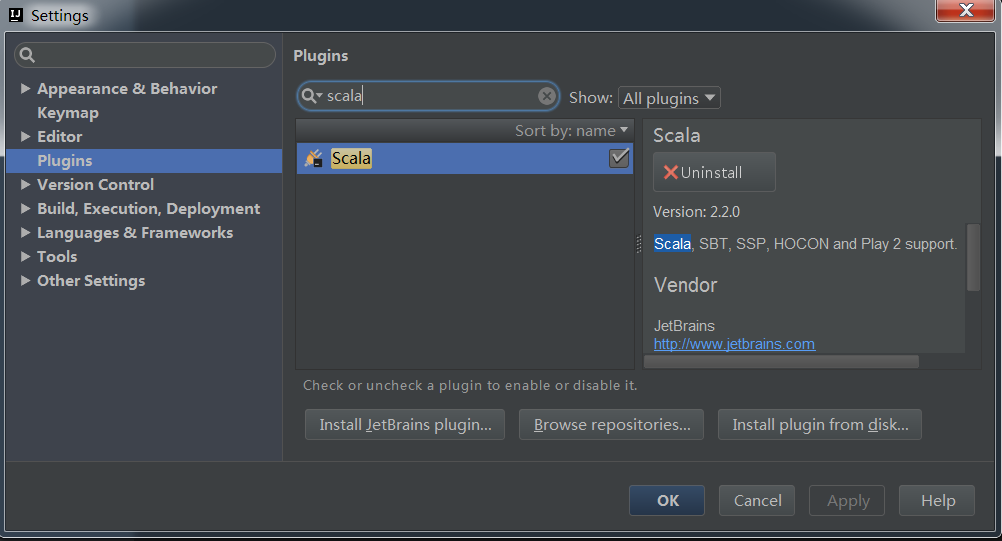
由于这里下载的ideaIU-15.0.2.exe,已经包含有Scala插件,如果不包含需要下载。查看是否已有scala插件可以新建项目,打开Files->settings选择Plugins,输入scala查看:
9.编写第一个Scala程序
依次点击File->New->Project,选择Scala->SBT,下一步,打开如下窗口:
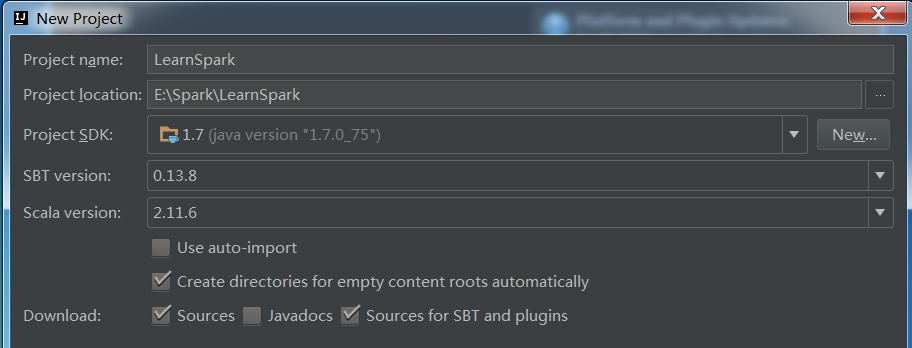
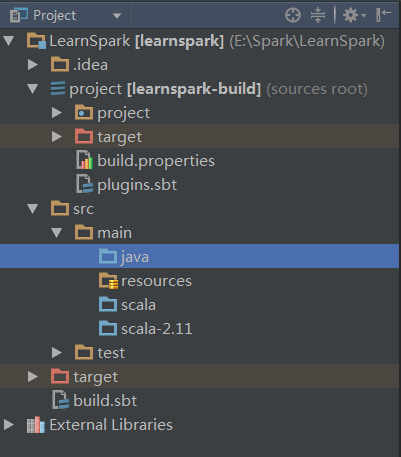
这里Scala选择为2.11.6,创建完成后会进行初始化操作,自动下载jar包等。下载时常看具体网络情况。待所有进度条完成后,项目目录已经出来了,如下:
编辑build.sbt:
name := "LearnSpark"
version := "1.0"
scalaVersion := "2.11.1"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.0.2"
编辑完成后,点击刷新,后台自动下载对应的依赖:

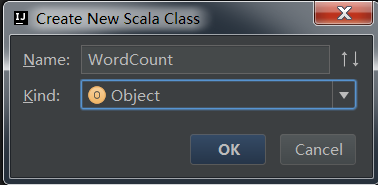
src->scala右击新建scala类WordCount
import org.apache.spark.{SparkContext, SparkConf} /** * Created by Lucy on 2017/7/4. */ object WordCount { def main(args: Array[String]) { val conf=new SparkConf().setAppName("wordcount") val sc=new SparkContext(conf) val input=sc.textFile("/home/lucy/helloSpark") val lines=input.flatMap(line=>line.split(" ")) val count=lines.map(word=>(word,1)).reduceByKey{case (x,y)=>x+y} val output=count.saveAsTextFile("/home/lucy/hellosparkRes") } }
代码编写完成后,进行打包(配置jar包,build):
配置jar包:File->Project Structure,选择Artifacts,点击+号:
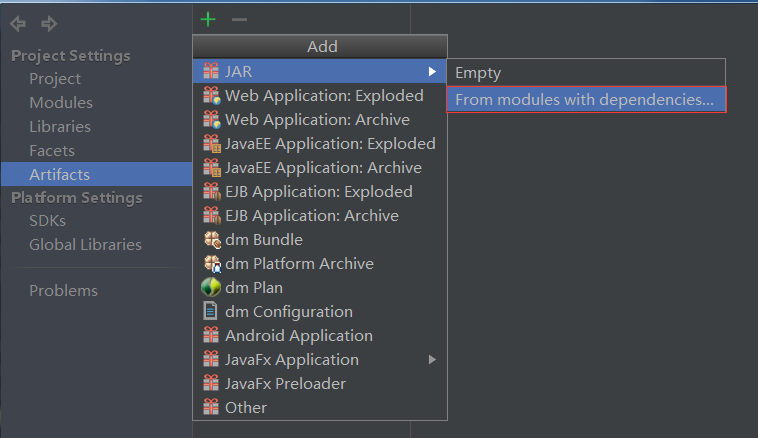

这里不打包依赖。配置jar包完成后,Build->Build Artifacts,等待build完成。
10.运行第一个Spark程序
这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
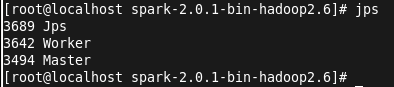
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的outartifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:

查看结果:
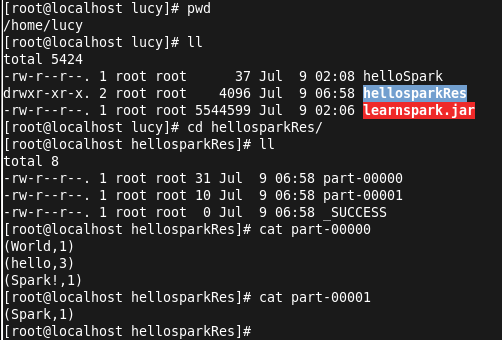
由于按照空格分割字符串,所以这里将Spark! 视为一个单词。至此,任务运行结束!