转自:http://www.cnblogs.com/TracePlus/p/4037165.html
因为,每家芯片的特性不同,根据向framebuffer写法的不同,分为tile-based的mobile cpu,如ImgTec PowerVR,ARM Mali,一部分老版本Qualcomm Adreno。还有标准的direct(immediate)的mobile cpu,如Nvida,Intel,Viante,以及一部分Qualcomm芯片(Qualcomm的Adreno.3xx系列后是可以在这两者之间进行切换的)。对tile-based的GPU来说,一旦使用打开alpha test或者其他discard功能的指令,就意味着这个fragment shader上不再只绘制一次像素了。这样会增加额外的性能消耗,所以一般都是建议用不实用alpha test,或者用alpha blend来代替。
tile-based gpu又分为Tiled Deferred(PowerVR)和Tiled(Adreno,Mali),两者都是在tile里进行渲染,而区别是TBR有自己的预处理,可以只着色可见像素。
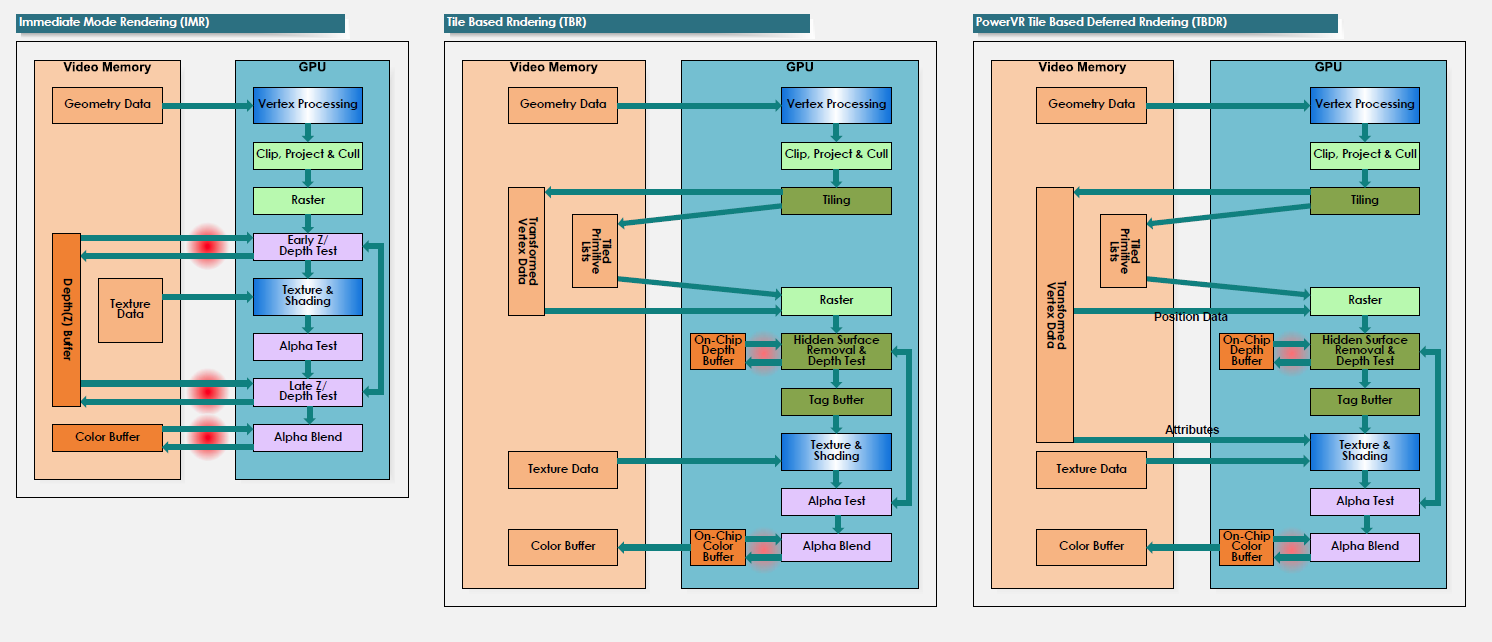
图 1 三种管线。
TBDR,以苹果设备用的ImgTec的PowerVR系列来说,在渲染处理时,会在fragment shading 阶段提供,在每个tile使用Deferred的方法,进行Hidden Surface Removal(HSR)的处理,原理是fs阶段前,对多边形进行预处理,决定它的哪个像素会对最终结果产生贡献,后面就只对这些像素进行着色。这个功能需要对不透明几何体进行排序。也就是说,要进行这种优化,必须要确保一定有能遮挡的像素,然而使用带有discard的shader指令,例如alpha-test,sample mask,alpha-to-coverage等等,会使得一些本来被遮挡的像素对最终结果产生贡献,所以,这个特性可能只能对一部分物体产生作用,从而产生额外的状态切换消费。以及该fragment额外隐藏像素的处理。
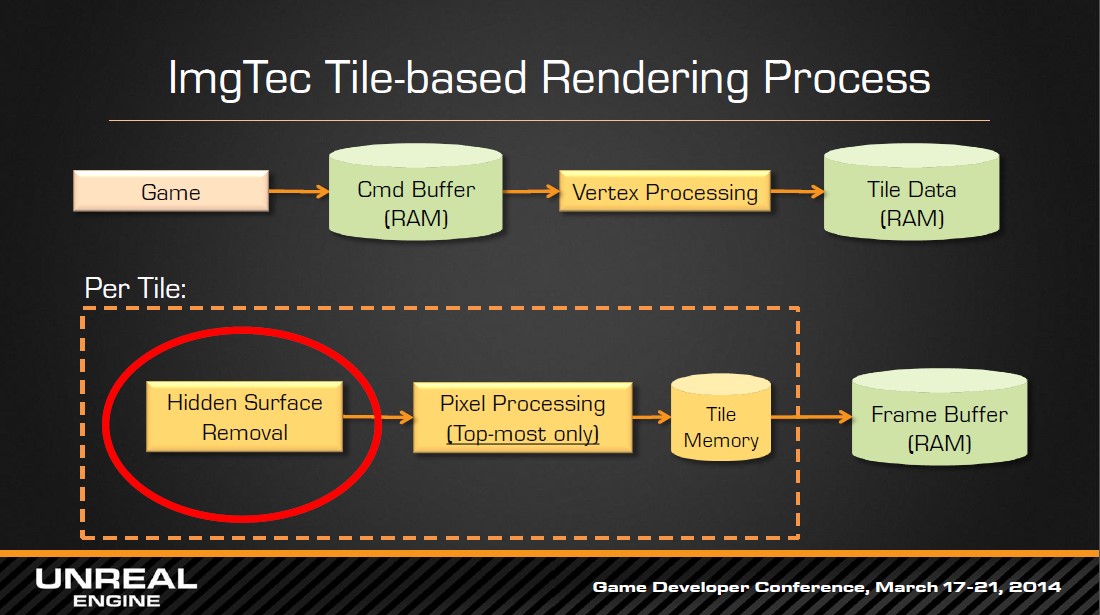
图2 ImgeTec的渲染处理
除此之外,ImgeTec还有另一个depth-only pass功能,生成深度缓冲,再次进行渲染时,就可以获取每个像素的可见深度,只有可见像素才会进行处理。所以,对于苹果设备来说,在CPU阶段对不透明物体的那种从前向后预处理排序是没有必要的。而是应该根据渲染状态来排序。

图3 ImgTec的渲染提示
TBR也上有提供类似的HSR方法,也就是early z-cull,使用粗糙,低精度和分辨率的Zbuffer进行depth-test,测试失败的fragment则不传说给rasterization。如果打开alpha test,后果跟TBDR也是类似的。

图4 TBDR的Deferred vs TBR的 Early z
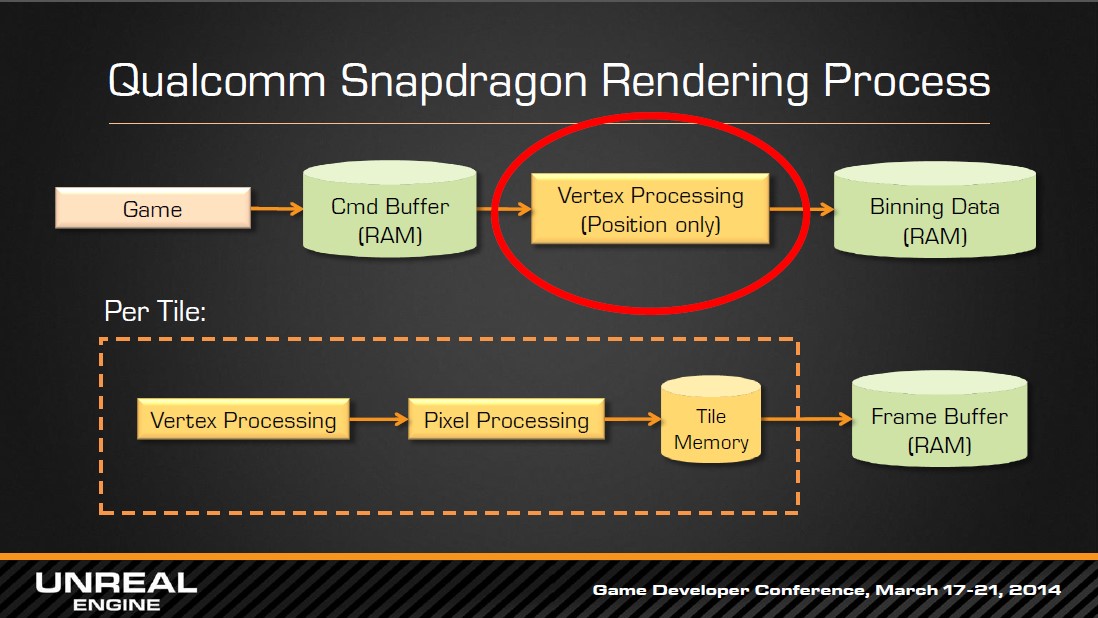
图5 Qualcomm的TBR
而IMR上,还是按照传统方法,尽可能的在CPU上进行Cull,以及从前向后进行距离排序,也提高erlay-z的效率。

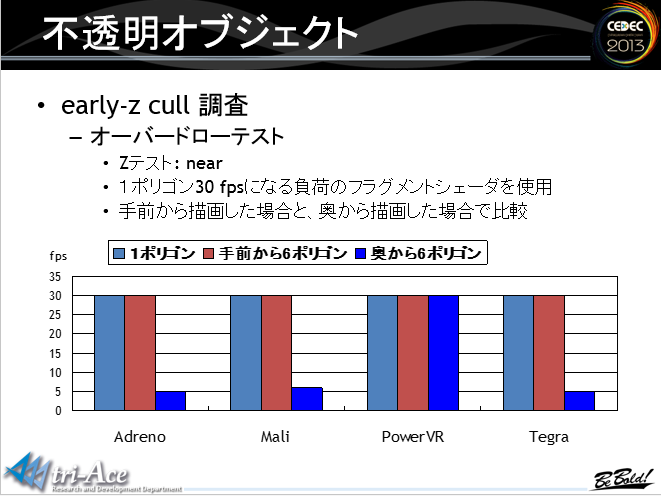 不透明物体,early-z的overdraw测试,只有PowerVR不需要进行预先排序处理。红色是从前向后绘制,蓝色是从后向前绘制
不透明物体,early-z的overdraw测试,只有PowerVR不需要进行预先排序处理。红色是从前向后绘制,蓝色是从后向前绘制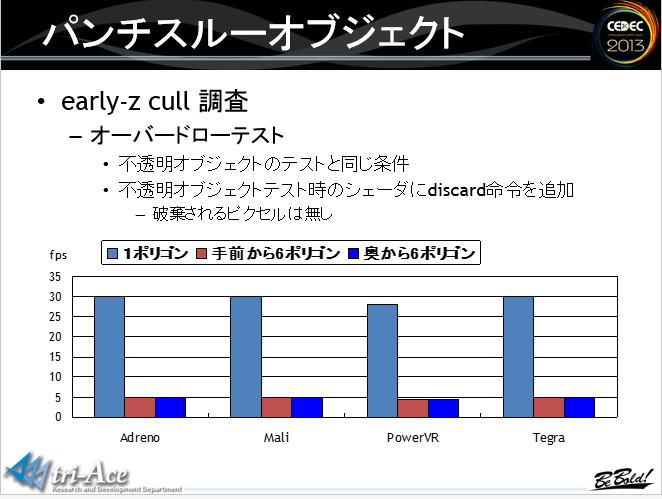 如图,当绘制透明和半透明混合物体时,必须使用discard命令的话,对性能的消耗还是很大的
如图,当绘制透明和半透明混合物体时,必须使用discard命令的话,对性能的消耗还是很大的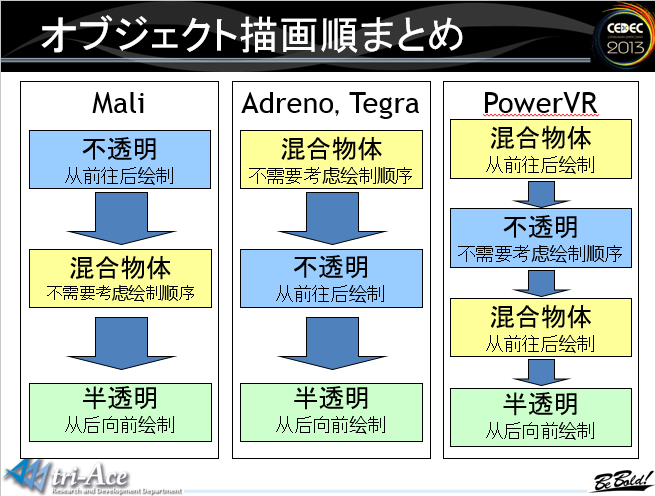
不同芯片上的的推荐绘制顺序
OpenGL Insights Performance Tuning for Tile-Based Architectures
Next-Generation AAA Mobile Rendering
FastMobileShaders
High-End Graphics for Smartphones and Tablets: A Development Case Study" CEDEC 2013