准备工作:
1.登录豆瓣网,找到移动迷宫三,获取评论的地址:https://movie.douban.com/subject/26004132/comments?status=P
2.登录账号,打开开发者工具,获取User-Agent
agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36' headers = { "Host": "www.douban.com", "Referer": "https://www.douban.com/", 'User-Agent': agent, }
3.填写个人账号信息,用post把信息发到服务器完成登陆
post_data = { "source": "index_nav", 'form_email': acount, 'form_password': secret }
代码编写:
1.爬取评论
爬取当前页面的所有评论 result = soup.find_all('div', {'class': 'comment'}) # 爬取得所有的短评 pattern4 = r'<p class=""> (.*?)' r'</p>' for item in result: s = str(item) count2 = s.find('<p class="">') count3 = s.find('</p>') s2 = s[count2 + 12:count3] # 抽取字符串中的评论 if 'class' not in s2: f.write(s2) # 获取下一页的链接 next_url = soup.find_all('div', {'id': 'paginator'}) pattern3 = r'href="(.*?)">后页' if (len(next_url) == 0): break next_url = re.findall(pattern3, str(next_url[0])) # 得到后页的链接 if (len(next_url) == 0): # 如果没有后页的链接跳出循环 break next_url = next_url[0]
2.把获取到的评论保存到txt(部分评论)

3.使用jieba进行词汇分割:
with codecs.open(dirs,encoding='utf-8') as f: comment_text=f.read() cut_text=" ".join(jieba.cut(comment_text)) with codecs.open('pjl_jieba.txt','w',encoding='utf-8') as f: f.write(cut_text)
4.对关键词出现次数进行统计:
word_lists=[] with codecs.open(file_name,'r',encoding='utf-8') as f: Lists=f.readlines() for li in Lists: cut_list=list(jieba.cut(li)) for word in cut_list: word_lists.append(word) word_lists_set=set(word_lists) sort_count=[] word_lists_set=list(word_lists_set) length=len(word_lists_set) k = 1 for w in word_lists_set: sort_count.append(w + u':' + str(word_lists.count(w)) + u"次 ") k += 1 with codecs.open('count_word.txt', 'w', encoding='utf-8') as f: f.writelines(sort_count)
部分词汇出现次数如下:
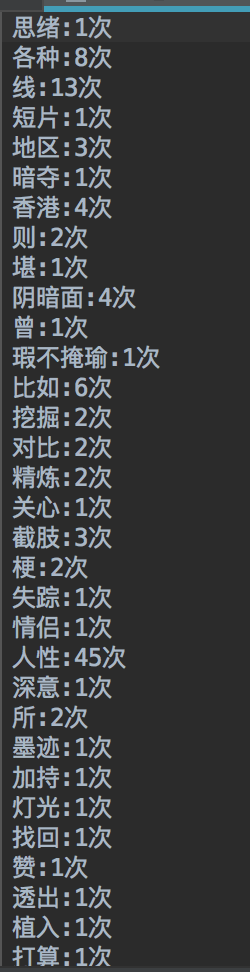
成功使爬虫蠕动的艰难过程:
安装python3.7运行环境,不清楚是macos的问题还是python的问题,在安装scipy时,无法正常安装且报错:
Command "python setup.py egg_info" failed with error code 1 in /...
(重装python3.6版后解决问题)成果展示:
