我们知道Kafka 的消息通过topic进行分类。topic可以被分为若干个partition来存储消息。消息以追加的方式写入partition,然后以先入先出的顺序读取。
下面是topic和partition的关系图:
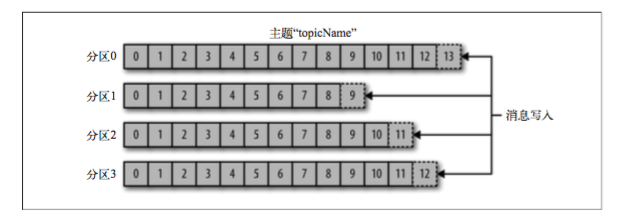
我们一般会在server.conf中通过num.partitions参数指定创建topic时包含多少个partition。默认是num.partitions=1。
既然一个topic有多个partition,那么消息是怎么样分配到partition的呢?
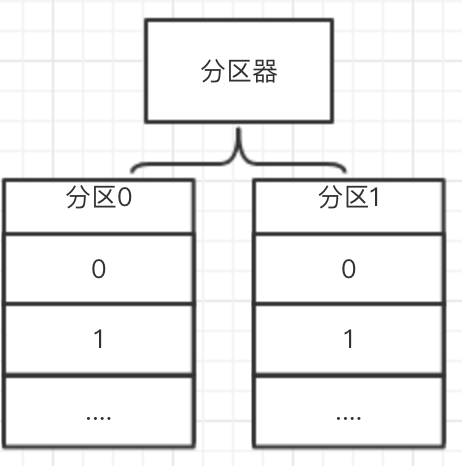
生产者生产一个消息send到topic分区器,分区器会根据消息里面的分区参数key值把消息分到对应的partition。这里就像我们快递代发网点一样,快递代发网点可以代理很多种快递公司,如果要寄快递者P(生产者)指定用什么快递公司,代发网点人员C(分区器)就会把该物品M(消息)归类到指定的快递公司区域存放。如果P不要求具体的快递公司寄件,那么就由C随意分配快递公司(哈哈,那就要看这个家伙的心情了,心情好点给你一个顺丰比较快到达,心情不好时就GG吧)。
下面是Kafka对消息分配分区 DefaultPartitioner.java 类的核心代码:
1 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { 2 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); 3 int numPartitions = partitions.size(); 4 if (keyBytes == null) { 5 int nextValue = counter.getAndIncrement(); 6 List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); 7 if (availablePartitions.size() > 0) { 8 int part = Utils.toPositive(nextValue) % availablePartitions.size(); 9 return availablePartitions.get(part).partition(); 10 } else { 11 // no partitions are available, give a non-available partition 12 return Utils.toPositive(nextValue) % numPartitions; 13 } 14 } else { 15 // hash the keyBytes to choose a partition 16 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; 17 } 18 }
第4、7行:如果没有指定key值并且可用分区个数大于0时,在就可用分区中做轮询决定改消息分配到哪个partition。
第4、10行:如果没有指定key值并且没有可用分区时,在所有分区中轮询决定改消息分配到哪个partition。
第14行:如果指定key值,对key做hash分配到指定的partition。
所以当同一个key的消息会被分配到同一个partition中。消息在同一个partition处理的顺序是FIFO,这就保证了消息的顺序性。