索引是一种加快查询速度的数据结构,常用索引结构有hash、B-Tree和B+Tree。本节通过分析三者的数据结构来说明为啥Mysql选择用B+Tree数据结构。
数据结构
Hash
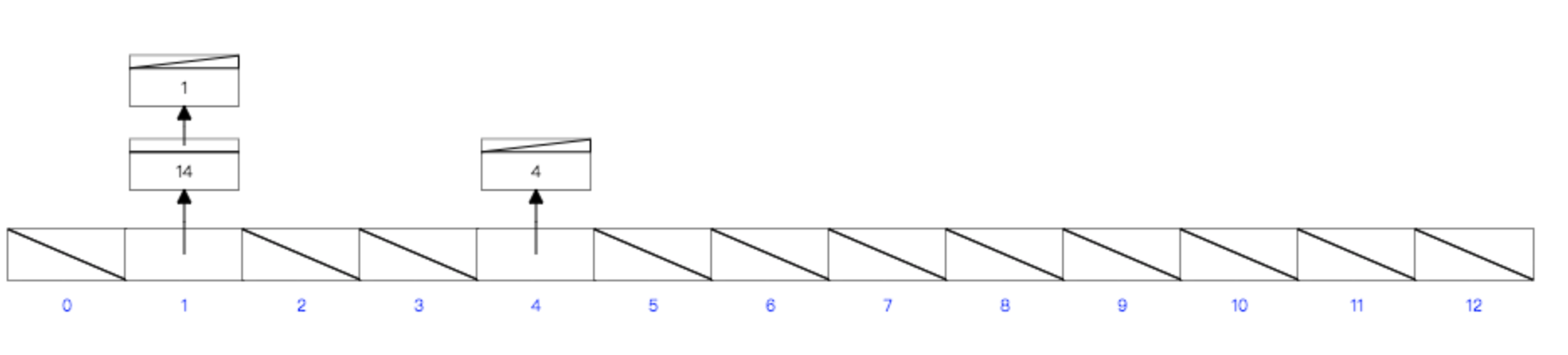
hash是基于哈希表完成索引存储,哈希表特性是数据存放是散列的。
优点:
等值查询快,通过hash值直接定位到具体的数据。
缺点:
- 范围查询效率低(表中的数据是无序数据,在日常开发中通常需要范围查询,该情况下hash需要一个一个查找后合并返回)
- hash表在使用的时会将所有数据加载到内存,比较消耗内存
- hash算法不好会出现hash碰撞的情况
- 哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值来避免读取行
- 哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
B-Tree
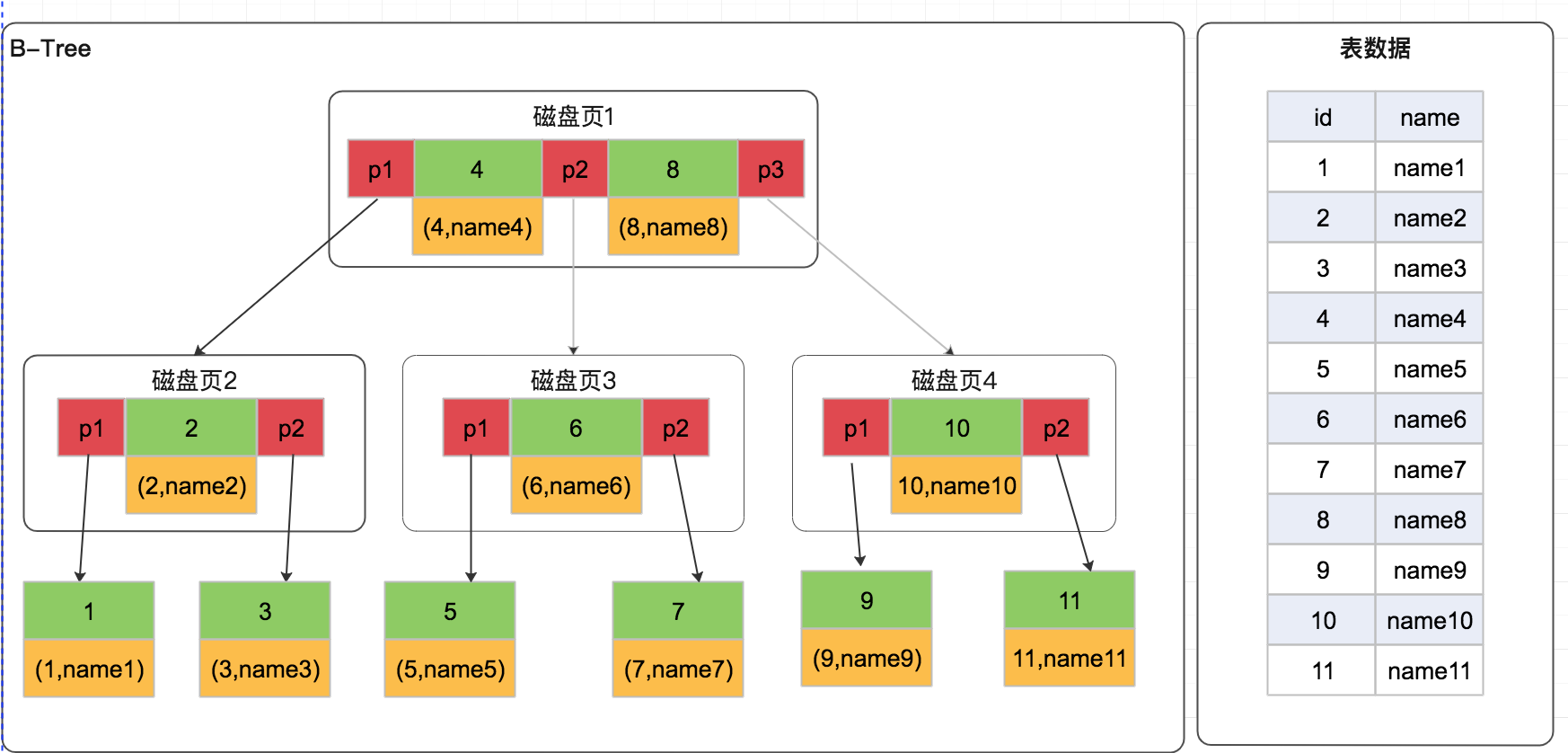
B-Tree特点:
- 所有键值数据分布在整棵树各个节点中
- 搜索有可能在非节点结束,在关键字全集内查找,类似二分查找
- 所有叶子节点都在同一层,并且以升序排列
B+Tree
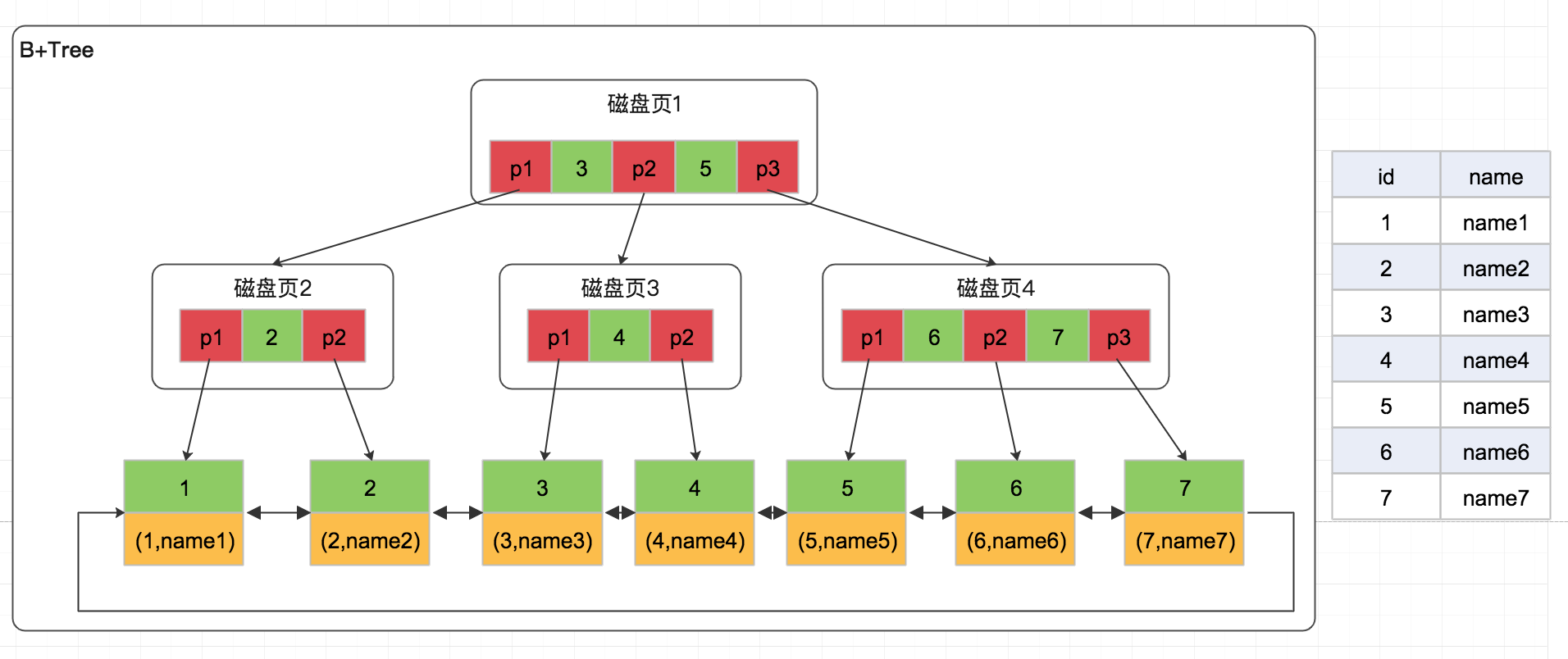
B+Tree 是在B-Tree的基础之上做的一种优化,变化如下:
- B+Tree 非叶子节点不存放数据
- 叶子节点存储关键字和数据,非叶子节点的关键字也会沉到叶子节点,并且排序
- 叶子节点两两指针相互连接,形成一个双向环形链表(符合磁盘的预读特性),顺序查询性能更高
Mysql为什么选择B+Tree

Mysql官网文档中写到InnoDB索引用的是 B-tree,但是底层用的是B+Tree。Mysql存储数据是以页为单位,默认一个页可以存放16K数据。假设B-Tree和B+Tree都是3层深度,表中每个记录为1K(假设的,一般不会这么大,别较真),那么三层深度的B-Tree存储 16 x 16 x 16 = 4096(比这个数还要少,因为每个页中还要存放指针和其它的数据)。B+Tree第一、二层存放的是key,假设是Long类型的主键,那么第一、二层每页存放数据约为 16 x 1024 / 8 = 2048,三层深度可以存放 2048 x 2048 x 16 = 6700W。MySQL查询过程是按页加载数据的,每加载一页就是一次IO操作,B+Tree进行三次IO可以查询6700W数据量。从这里也可以知道Mysql一般设置三层深度就足够了。