实现一个小型搜索引擎
麻雀虽小,五脏俱全,跟大型搜索引擎相比,实现一个小型搜索引擎所用到的理论基础是相通的。
四个部分:搜集、分析、索引、查询
概述流程
搜集
爬虫爬取网页数据
分析
抽取网页文本信息
分词并创建临时索引
索引
将临时索引构建为倒排索引:关键词被哪些网页包含
查询
先对关键词做分词处理
根据单词查找对应的单词编号
根据单词编号查找单词编号在索引文件中的偏移位置
根据偏移位置查找这些单词对应的包含它们的网页编号列表
对网页编号列表进行排序
根据网页编号查找对应的网页链接,分页展示给用户
涉及的数据结构与算法:
图、散列表、Trie 树、布隆过滤器、单模式字符串匹配算法、AC 自动机、广度优先遍历、归并排序
搜集
- 搜索引擎把整个互联网看作数据结构中的有向图,把每个页面看作一个顶点。
- 如果某个页面中包含另外一个页面的链接,那我们就在两个顶点之间连一条有向边。
- 可以利用图的遍历搜索算法,来遍历整个互联网中的网页:
- 深度优先和广度优先
- 搜索引擎采用广度优先搜索策略
- 先找一些权重比较高的链接(比如新浪主页网址、腾讯主页网址等),作为种子网页链接,放入到队列中。爬虫按照广度优先的策略,不停地从队列中取出链接,然后取爬取对应的网页,解析出网页里包含的其他网页链接,再将解析出来的链接添加到队列中。
- 关键技术细节
- 待爬取网页链接文件:links.bin:
- 在广度优先搜索爬取页面的过程中,爬虫会不停地解析页面链接,将其放到队列中。
- 队列中的链接就会越来越多,用一个存储在磁盘中的文件(links.bin)来作为广度优先搜索中的队列。
- 爬虫从 links.bin 文件中,取出链接去爬取对应的页面。等爬取到网页之后,将解析出来的链接,直接存储到 links.bin 文件中。
- 这样用文件来存储网页链接的方式,还可以支持断点续爬。当机器断电之后,网页链接不会丢失;当机器重启之后,还可以从之前爬取到的位置继续爬取。
- 网页判重文件:bloom_filter.bin
- 如何避免重复爬取相同的网页呢?
- 使用布隆过滤器快速并且非常节省内存地实现网页的判重。
- 为了可以断点续爬,也需要将布隆过滤器持久化到磁盘中,也就是存储在 bloom_filter.bin 文件中。
- 原始网页存储文件:doc_raw.bin
- 爬取到网页之后,需要将其存储下来,以备后面离线分析、索引之用。那如何存储海量的原始网页数据呢?
- 网页成千上万,可以把多个网页存储在一个文件中。每个网页之间,通过一定的标识进行分隔,方便后续读取。具体存储格式如下
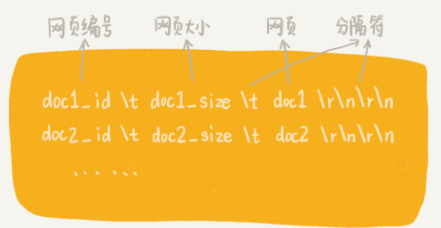
-
设置每个文件的大小不能超过一定的值(比如 1GB)
- 简单估算:假设一台机器的硬盘大小是 100GB 左右,一个网页的平均大小是 64KB。那在一台机器上,我们可以存储 100 万到 200 万左右的网页。假设我们的机器的带宽是 10MB,那下载 100GB 的网页,大约需要 10000 秒。也就是说,爬取 100 多万的网页,也就是只需要花费几小时的时间。
- 网页链接及其编号的对应文件:doc_id.bin
- 网页编号实际上就是给每个网页分配一个唯一的 ID,方便我们后续对网页进行分析、索引。那如何给网页编号呢?
- 可以按照网页被爬取的先后顺序,从小到大依次编号。具体是这样做的:
- 维护一个中心的计数器,每爬取到一个网页之后,就从计数器中拿一个号码,分配给这个网页,然后计数器加一。
- 在存储网页的同时,将网页链接跟编号之间的对应关系,存储在另一个 doc_id.bin 文件中。
- 待爬取网页链接文件:links.bin:
分析
- 网页爬取下来之后,需要对网页进行离线分析。分析阶段主要包括两个步骤:
- 抽取网页文本信息
- 分词并创建临时索引
- 抽取网页文本信息
- 网页是半结构化数据,里面夹杂着各种标签、JavaScript 代码、CSS 样式
- 网页遵循HTML 语法规范。依靠 HTML 标签来抽取网页中的文本信息。这个抽取的过程,大体可以分为两步:
- 去掉 JavaScript 代码、CSS 格式以及下拉框中的内容:
- 也就是<style></style>,<script></script>,<option></option>这三组标签之间的内容。
- 可以利用 AC 自动机这种多模式串匹配算法,在网页这个大字符串中,一次性查找<style>, <script>, <option>这三个关键词。当找到某个关键词出现的位置之后,只需要依次往后遍历,直到对应结束标签(</style>, </script>, </option)为止。而这期间遍历到的字符串连带着标签就应该从网页中删除。
- 去掉所有 HTML 标签:
- 也是通过字符串匹配算法来实现的,过程跟第一步类似。
- 去掉 JavaScript 代码、CSS 格式以及下拉框中的内容:
- 分词并创建临时索引
- 从网页中抽取出了我们关心的文本信息。接下来,我们要对文本信息进行分词,并且创建临时索引。
- 对于英文网页来说,只需要通过空格、标点符号等分隔符,将每个单词分割开来就可以了,对于中文来说,分词就复杂多了:
- 基于字典和规则的分词方法:
- 字典也叫词库,包含大量常用的词语(可以直接从网上下载别人整理好的)。
- 借助词库并采用最长匹配规则,来对文本进行分词。最长匹配,就是匹配尽可能长的词语。
- 举例:比如要分词的文本是“中国人民解放了”,词库中有“中国”“中国人”“中国人民”“中国人民解放军”这几个词,取最长匹配,也就是“中国人民”划为一个词,而不是把“中国”、“中国人“划为一个词。具体到实现层面,我们可以将词库中的单词,构建成 Trie 树结构,然后拿网页文本在 Trie 树中匹配。
- 创建临时索引
- 分词完成之后,得到一组单词列表。把单词与网页之间的对应关系,写入到一个临时索引文件中(tmp_Index.bin),此临时索引文件用来构建倒排索引文件。临时索引文件的格式如下:
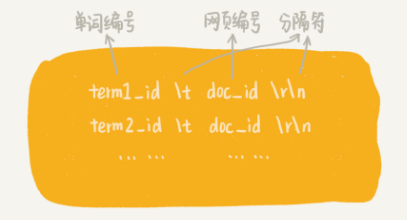
- 给单词编号的方式,跟给网页编号类似。也是维护一个计数器,每当从网页文本信息中分割出一个新的单词的时候,我们就从计数器中取一个编号,分配给它,然后计数器加一。
- 此过程还需要使用散列表,记录已经编过号的单词:
- 在对网页文本信息分词的过程中,拿分割出来的单词,先到散列表中查找,如果找到,那就直接使用已有的编号;如果没有找到,再去计数器中拿号码,并且将这个新单词以及编号添加到散列表中。
- 分词及写入临时索引完成之后,将这个单词跟编号之间的对应关系,写入到磁盘文件中,并命名为 term_id.bin。
- 经过分析阶段,得到了两个重要的文件:临时索引文件(tmp_index.bin)和单词编号文件(term_id.bin)
索引
- 索引阶段主要负责将分析阶段产生的临时索引,构建成倒排索引。倒排索引( Inverted index)中记录了每个单词以及包含它的网页列表。
- 倒排的理解:正排-》文档包含哪些单词;倒排-》单词被哪些文档包含
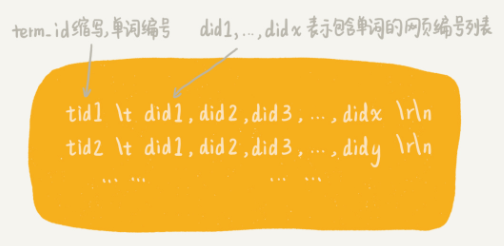
- 如何通过临时索引文件,构建出倒排索引文件呢?
- 考虑到临时索引文件很大,无法一次性加载到内存中,搜索引擎一般会选择使用多路归并排序的方法来实现。
- 先对临时索引文件,按照单词编号的大小进行排序。因为临时索引很大,所以一般基于内存的排序算法就没法处理。
- 可以用的归并排序的处理思想,将其分割成多个小文件,先对每个小文件独立排序,最后再合并在一起。实际的软件开发中,可以直接利用 MapReduce 来处理。
- 临时索引文件排序完成之后,相同的单词就被排列到了一起。顺序地遍历排好序的临时索引文件,就能将每个单词对应的网页编号列表找出来,然后把它们存储在倒排索引文件中。
- 具体的处理过程画成了一张图:
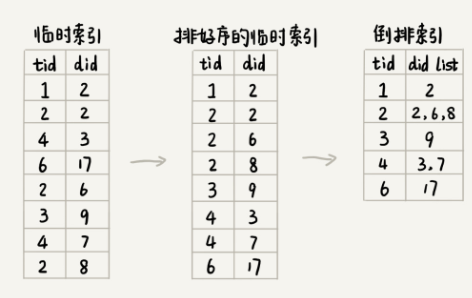
-
除了倒排文件之外,还需要一个文件,来记录每个单词编号在倒排索引文件中的偏移位置。把这个文件命名为 term_offset.bin,
-
作用是:帮助我们快速地查找某个单词编号在倒排索引中存储的位置,进而快速地从倒排索引中读取单词编号对应的网页编号列表。
查询
- 前面三个阶段的处理,只是为了最后的查询做铺垫。因此,现在就要利用之前产生的几个文件,来实现最终的用户搜索功能。
- doc_id.bin:记录网页链接和编号之间的对应关系。
- term_id.bin:记录单词和编号之间的对应关系。
- index.bin:倒排索引文件,记录每个单词编号以及对应包含它的网页编号列表。
- term_offsert.bin:记录每个单词编号在倒排索引文件中的偏移位置。
- 四个文件中,除了倒排索引文件(index.bin)比较大之外,其他的都比较小。为了方便快速查找数据,将其他三个文件都加载到内存中,并且组织成散列表这种数据结构
- 当用户在搜索框中,输入某个查询文本的时候,先对用户输入的文本进行分词处理。假设分分词之后,得到 k 个单词。
- 拿这 k 个单词,去 term_id.bin 对应的散列表中,查找对应的单词编号。经过这个查询之后,得到了这 k 个单词对应的单词编号。
- 拿这 k 个单词编号,去 term_offset.bin 对应的散列表中,查找每个单词编号在倒排索引文件中的偏移位置。经过这个查询之后,得到了 k 个偏移位置。
- 拿这 k 个偏移位置,去倒排索引(index.bin)中,查找 k 个单词对应的包含它的网页编号列表。经过这一步查询之后,得到了 k 个网页编号列表。
- 针对这 k 个网页编号列表,统计每个网页编号出现的次数。
- 具体到实现层面,可以借助散列表来进行统计。
- 统计得到的结果,按照出现次数的多少,从小到大排序。
- 出现次数越多,说明包含越多的用户查询单词(用户输入的搜索文本,经过分词之后的单词)。
- 经过这一系列查询,就得到了一组排好序的网页编号。
- 拿着网页编号,去 doc_id.bin 文件中查找对应的网页链接,分页显示给用户就可以了。
其他优化相关
- 计算网页权重的PageRank算法、
- 计算查询结果排名的tf-idf模型等等。