排序算法
如何分析一个“排序算法”?三个方面着手:
- 执行效率
- 最好情况,最坏情况,平均情况时间复杂度
- 时间复杂度的系数,常数,低阶
- 比较次数和交换(或移动)次数
- 内存消耗
- 原地排序,空间复杂度O(1)
- 稳定性
- 关注的是值相同的项,排序前后的先后顺序是否不变,一致则表示是稳定算法
-
排序比较
排序算法动画演示:https://visualgo.net/zh/sorting
插入排序比冒泡排序高效--冒泡排序的数据交换有三个操作,插入排序数据移动只有一个操作,也就是复杂度系数低
| 排序算法 | 是否稳定 | 是否原地排序 | 最好情况 | 最坏情况 | 平均情况 |
| 冒泡排序 | 是 | 是 | O(n) | O(n2) | O(n2) |
| 插入排序 | 是 | 是 | O(n) | O(n2) | O(n2) |
| 选择排序 | 否 | 是 | O(n2) | O(n2) | O(n2) |
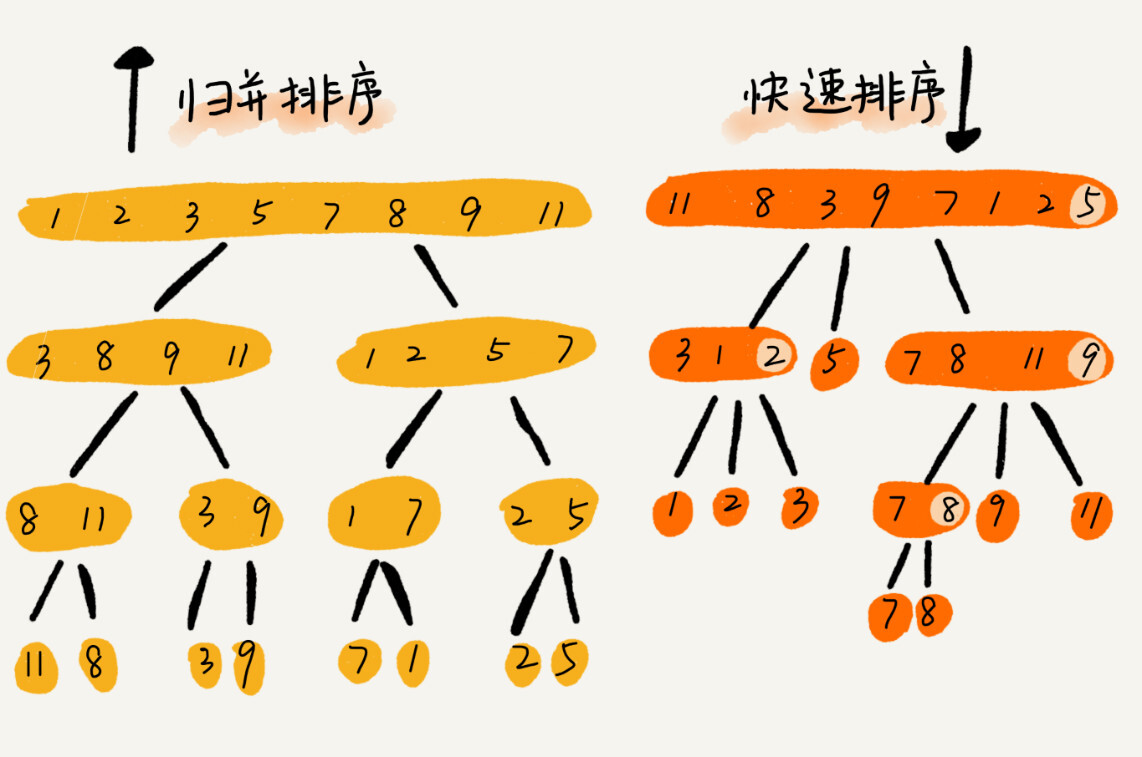
| 归并排序 | 是 | 否--O(n) | O(nlogn) | O(nlogn) | O(nlogn) |
| 快速排序 | 否 | 是 | O(n) | O(n2) | O(nlogn) |
-
冒泡排序--操作相邻数据比较互换
-
插入排序--分已排序和未排序区间,每次从未排序取一项插入到已排序区间的合适位置(通过比较确定,比较过程中完成数据移动)
-
选择排序--分已排序和未排序区间,每次取未排序中最小项放到已排序区间末尾,交换完成插入。
-
归并排序--分治思想,递归实现:把整个数据分成两部分,分别将两部分排序,再把排序后的两部分合并,递归处理以上步骤。
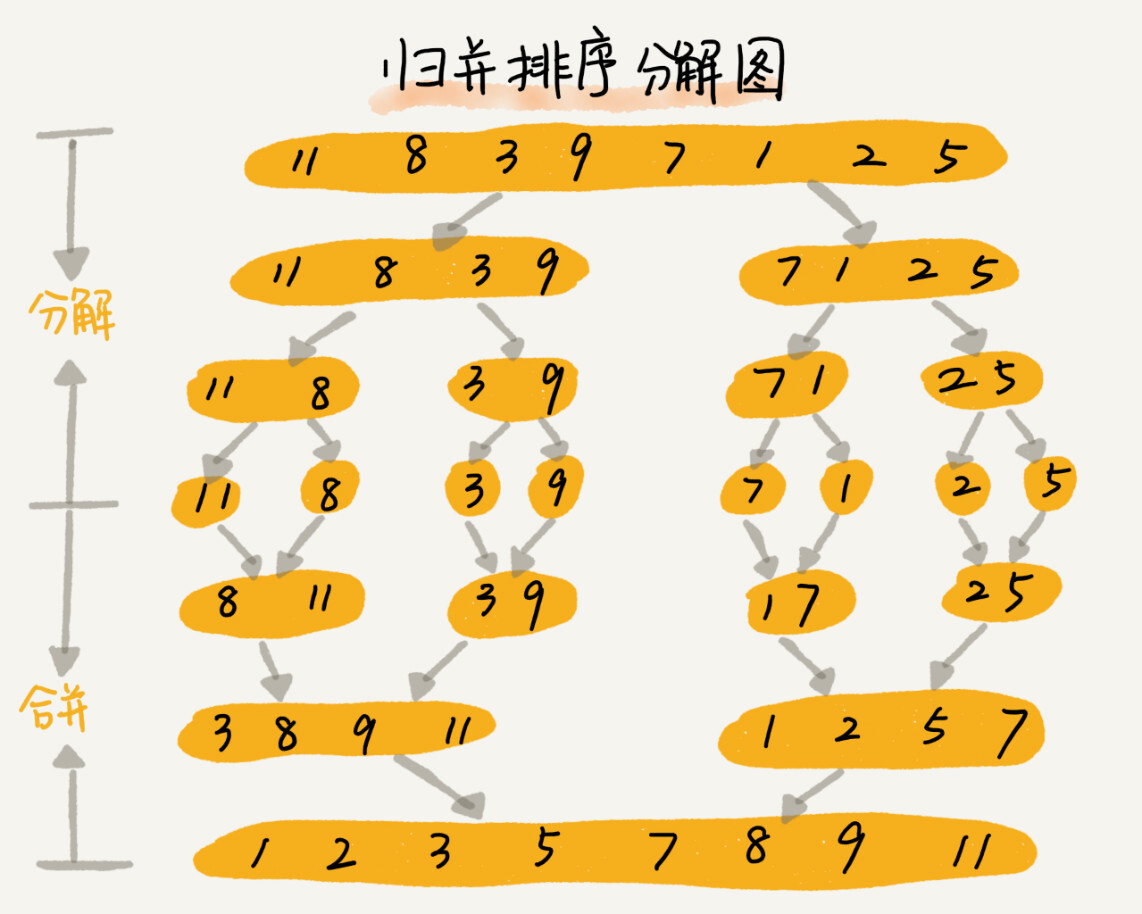
- 分割过程:取数组A中间位置,分成两部分,对两部分分别排序,递归处理直到不能再分割。
- 合并过程--将两个有序部分进行合并:从头遍历每次取两部分头部的较小值放入新的数组,直到一个数组结束,将另一个数组的剩余部分移入新数组末尾,合并完成则排序完成。
- 伪代码
// 归并排序算法, A是数组,n表示数组大小 merge_sort(A, n) { merge_sort_c(A, 0, n-1) } // 递归调用函数 merge_sort_c(A, p, r) { // 递归终止条件 if p >= r then return // 取p到r之间的中间位置q q = (p+r) / 2 // 分治递归 merge_sort_c(A, p, q) merge_sort_c(A, q+1, r) // 将A[p...q]和A[q+1...r]合并为A[p...r] merge(A[p...r], A[p...q], A[q+1...r]) }
merge(A[p...r], A[p...q], A[q+1...r]) { var i := p,j := q+1,k := 0 // 初始化变量i, j, k var tmp := new array[0...r-p] // 申请一个大小跟A[p...r]一样的临时数组 while i<=q AND j<=r do { if A[i] <= A[j] { tmp[k++] = A[i++] // i++等于i:=i+1 } else { tmp[k++] = A[j++] } } // 判断哪个子数组中有剩余的数据 var start := i,end := q if j<=r then start := j, end:=r // 将剩余的数据拷贝到临时数组tmp while start <= end do { tmp[k++] = A[start++] } // 将tmp中的数组拷贝回A[p...r] for i:=0 to r-p do { A[p+i] = tmp[i] } }
-
快速排序--分治思想,递归处理:每次取末尾项作中位数,将小于等中位数的放左边,大于的放右边,再对左右分区分别递归执行上述步骤,直到无法分区(只剩一项)。
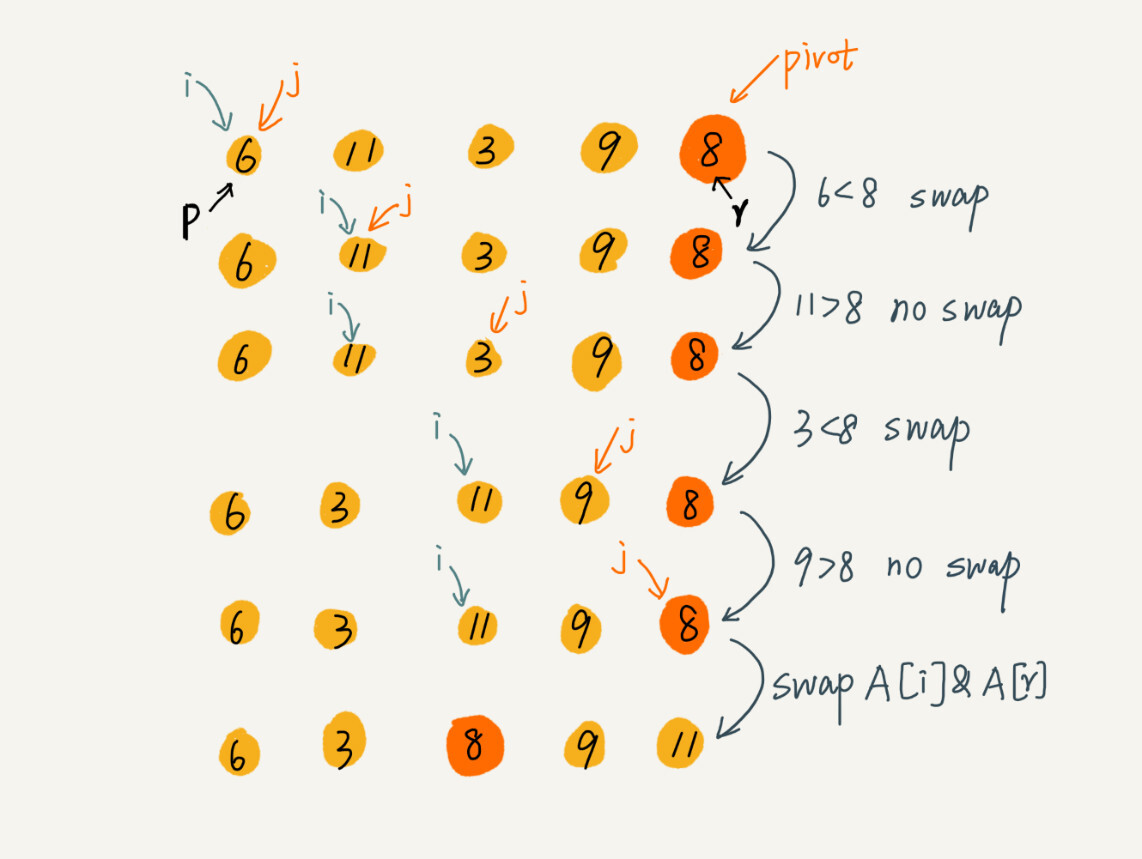
- 利用快排思想查找第K大元素:先按快排分区,比较K与中位数的"下标index+1",K==index+1,则中位数就是第K大元素,K<index+1则在左边,K>index+1则在右边,对所在边递归执行上述步骤,直到找到该元素。