分布式01-Dubbo基础
1-分布式基础理论
- 分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
- 首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。。。
- 分布式系统怎么将任务分发到这些计算机节点呢,很简单的思想,分而治之,即分片(partition)。对于计算,那么就是对计算任务进行切换,每个节点算一些,最终汇总就行了,这就是MapReduce的思想;对于存储,更好理解一下,每个节点存一部分数据就行了。当数据规模变大的时候,Partition是唯一的选择,同时也会带来一些好处:
- 提升性能和并发,操作被分发到不同的分片,相互独立
- 系统的可用性,即使部分分片不能用,其他分片不会受到影响
2-Dubbo架构演变
发展演变
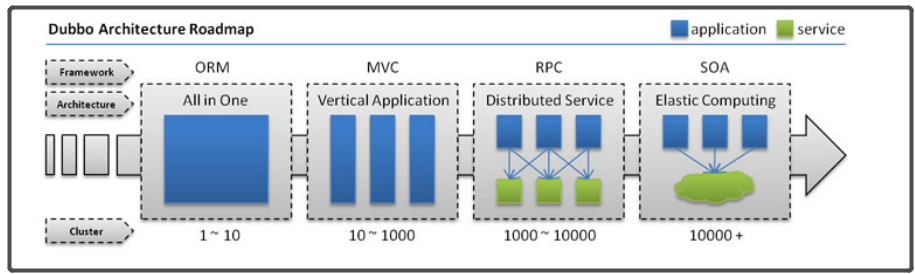
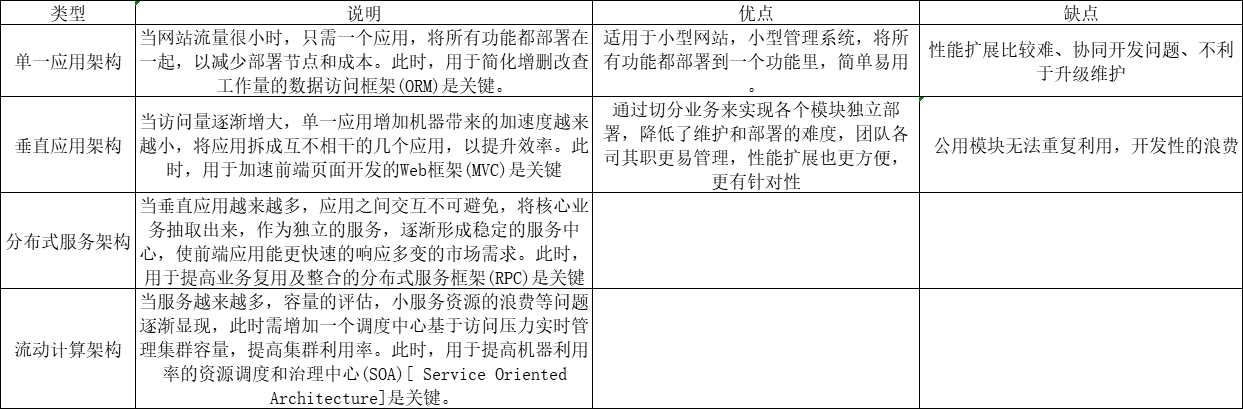
3-Dubbo需求

- 在大规模服务化之前,应用可能只是通过 RMI 或 Hessian 等工具,简单的暴露和引用远程服务,通过配置服务的URL地址进行调用,通过 F5 等硬件进行负载均衡。
- 当服务越来越多时,服务 URL 配置管理变得非常困难,F5 硬件负载均衡器的单点压力也越来越大。 此时需要一个服务注册中心,动态的注册和发现服务,使服务的位置透明。并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对 F5 硬件负载均衡器的依赖,也能减少部分成本。
- 当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。 这时,需要自动画出应用间的依赖关系图,以帮助架构师理清理关系。
- 接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器? 为了解决这些问题,第一步,要将服务现在每天的调用量,响应时间,都统计出来,作为容量规划的参考指标。其次,要可以动态调整权重,在线上,将某台机器的权重一直加大,并在加大的过程中记录响应时间的变化,直到响应时间到达阈值,记录此时的访问量,再以此访问量乘以机器数反推总容量。
4-Dubbo架构
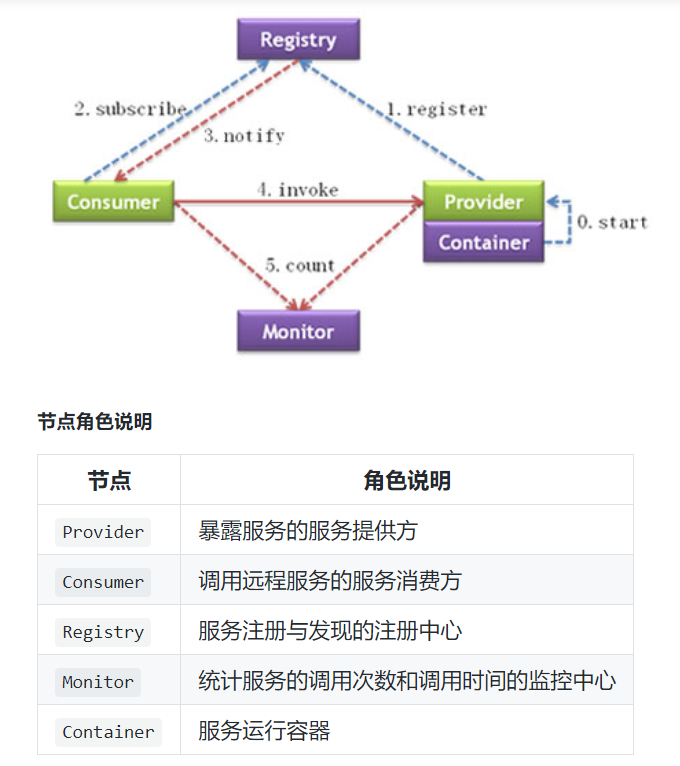
调用关系说明
- 0-服务容器负责启动,加载,运行服务提供者。
- 1-服务提供者在启动时,向注册中心注册自己提供的服务。
- 2-服务消费者在启动时,向注册中心订阅自己所需的服务。
- 3-注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 4-服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 5-服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
参考文献
1-https://www.cnblogs.com/xybaby/p/7787034.html
2-http://dubbo.apache.org/zh-cn/docs/user/preface/background.html