1. 一个数据处理难题
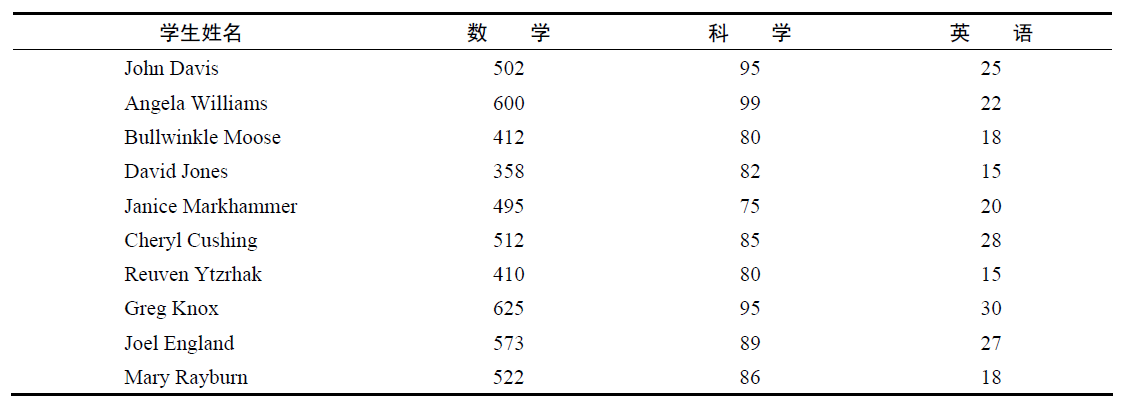
a. 确定一个单一的成绩衡量指标
b. 前20%的学生评定为A,接下来20%评定为B,以此类推
c. 按字母顺序对学生排序
2. 数值和字符处理函数
数值函数(数学,统计,概率)
字符处理函数
2.1 数学函数
> abs(-4) [1] 4 > > sqrt(25) [1] 5 > > ceiling(3.475) [1] 4 > > floor(3.475) [1] 3 > > trunc(5.99) [1] 5 > > round(3.475, digits=2) [1] 3.48 > > signif(3.475, digits=2) [1] 3.5 > > cos(3.1415926) [1] -1 > > sin(3.1415926) [1] 5.358979e-08 > > acos(-0.416) [1] 1.999839 > > sinh(2) [1] 3.62686 > > asinh(3.627) [1] 2.000037 > > log(10) [1] 2.302585 > > log10(10) [1] 1 > > exp(2.3026) [1] 10.00015 >
2.2 统计函数
> mean(c(1, 2, 3, 4))
[1] 2.5
>
> median(c(1, 2, 3, 4))
[1] 2.5
>
> sd(c(1, 2, 3, 4))
[1] 1.290994
>
> var(c(1, 2, 3, 4))
[1] 1.666667
>
> mad(c(1, 2, 3, 4))
[1] 1.4826
>
> x <- c(1, 2, 3, 4)
> y <- quantile(x, c(.3, .84))
> y
30% 84%
1.90 3.52
>
> range(x)
[1] 1 4
>
> diff(range(x))
[1] 3
>
> sum(x)
[1] 10
>
> x <- c(1, 5, 23, 29)
> diff(x)
[1] 4 18 6
>
> min(x)
[1] 1
>
> max(x)
[1] 29
>
> scale(x, center=TRUE, scale=TRUE)
[,1]
[1,] -0.9925397
[2,] -0.6984539
[3,] 0.6249324
[4,] 1.0660612
attr(,"scaled:center")
[1] 14.5
attr(,"scaled:scale")
[1] 13.60147
>
> x <- c(1, 2, 3, 4, 5, 6, 7, 8) > mean(x) [1] 4.5 > sd(x) [1] 2.44949 > > n <- length(x) > meanx <- sum(x)/n > css <- sum((x - meanx)^2) > sdx <- sqrt(css / (n-1)) > meanx [1] 4.5 > sdx [1] 2.44949 >
2.3 概率函数

> x <- pretty(c(-3, 3), 30) > x [1] -3.0 -2.8 -2.6 -2.4 -2.2 -2.0 -1.8 -1.6 -1.4 -1.2 -1.0 -0.8 -0.6 -0.4 -0.2 [16] 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.6 2.8 [31] 3.0 > y <- dnorm(x) > y [1] 0.004431848 0.007915452 0.013582969 0.022394530 0.035474593 0.053990967 [7] 0.078950158 0.110920835 0.149727466 0.194186055 0.241970725 0.289691553 [13] 0.333224603 0.368270140 0.391042694 0.398942280 0.391042694 0.368270140 [19] 0.333224603 0.289691553 0.241970725 0.194186055 0.149727466 0.110920835 [25] 0.078950158 0.053990967 0.035474593 0.022394530 0.013582969 0.007915452 [31] 0.004431848 > plot(x, y, type="l", xlab="NormalDeviate", ylab="Density", yaxs="i") >

> pnorm(1.96) [1] 0.9750021 > qnorm(.9, mean=500, sd=100) [1] 628.1552 > rnorm(50, mean=50, sd=10) [1] 67.26521 54.63231 42.90968 48.38989 73.67308 49.74476 57.81742 67.75197 [9] 66.51772 48.48707 39.37449 35.09612 59.43735 58.02651 40.43783 51.18190 [17] 63.75237 39.67564 42.67555 50.88800 43.47265 58.69022 64.55702 34.35042 [25] 63.23016 45.81644 43.31544 54.58287 50.46310 31.72297 40.34214 55.06260 [33] 42.25432 45.63078 56.23651 53.27949 47.83063 53.69351 56.68358 46.04020 [41] 57.20872 52.52052 49.20011 47.71317 55.79194 42.20664 48.22365 43.57350 [49] 33.02280 36.45630 >
2.3.1 设定随机数种子
> runif(5) [1] 0.8650632 0.2548104 0.7736314 0.9595250 0.5731663 > runif(5) [1] 0.3458971 0.8683841 0.7487097 0.1382841 0.1953431 > set.seed(1234) > runif(5) [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154 > set.seed(1234) > runif(5) [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154 >
2.3.2 生成多元正态数据
> library(MASS)
> options(digits=3)
# 生成随机数种子
> set.seed(1234)
# 指定均值向量、协方差阵
> mean <- c(230.7, 146.7, 3.6)
> sigma <- matrix(c(15360.8, 6721.2, -47.1,
+ 6721.2, 4700.9, -16.5,
+ -47.1, -16.5, 0.3), nrow=3, ncol=3)
# 生成500个伪随机观测数据
> mydata <- mvrnorm(500, mean, sigma)
# 为方便,结果从矩阵转换为数据框
> mydata <- as.data.frame(mydata)
# 为变量指定了名称
> names(mydata) <- c("y", "x1", "x2")
# 确认拥有500个观测和3个变量
> dim(mydata)
[1] 500 3
# 输出前10个观测
> head(mydata, n=10)
y x1 x2
1 98.8 41.3 3.43
2 244.5 205.2 3.80
3 375.7 186.7 2.51
4 -59.2 11.2 4.71
5 313.0 111.0 3.45
6 288.8 185.1 2.72
7 134.8 165.0 4.39
8 171.7 97.4 3.64
9 167.2 101.0 3.50
10 121.1 94.5 4.10
>
2.4 字符处理函数