1、准备工作
先创建具有百万量的数据表 转自:https://blog.csdn.net/mysqltop/article/details/105230327
#建测试表
drop table if exists t;
CREATE TABLE t (
id int NOT NULL AUTO_INCREMENT PRIMARY KEY comment '自增主键',
dept tinyint not null comment '部门id',
name varchar(30) comment '用户名称',
create_time datetime not null comment '注册时间',
last_login_time datetime comment '最后登录时间'
) comment '测试表';
#手工插入第一条测试数据,后面数据会根据这条数据作为基础生成
insert into t values(1,1,'user_1', '2018-01-01 00:00:00', '2018-03-01 12:00:00');
#初始化序列变量
set @i=1;
#==================此处拷贝反复执行,直接符合预想的数据量===================
#执行20次即2的20次方=1048576 条记录
#执行23次即2的23次方=8388608 条记录
#执行24次即2的24次方=16777216 条记录
#......
insert into t(dept, name, create_time, last_login_time)
select left(rand()*10,1) as dept, #随机生成1~10的整数
concat('user_',@i:=@i+1), #按序列生成不同的name
date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), #生成有时间大顺序随机注册时间
date_add(date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), interval + cast(rand()*1000000 as signed) SECOND) #生成有时间大顺序的随机的最后登录时间
from t;
select count(1) from t;
2、在mysql中如何查看语句执行时间
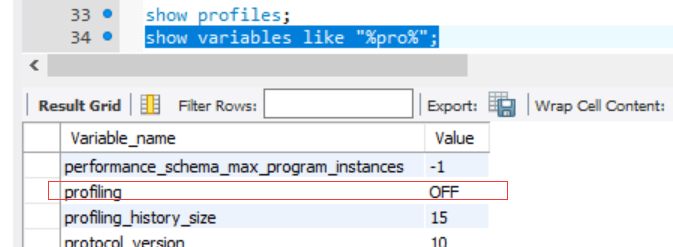
语句:show profiles;
如果执行上述语句不能查看,则需要查看是否开启:show variables like "%pro%";
开启:set profiling=1;
关闭:set profiling=0;
3、为什么使用索引
主要是为了提高查询效率。没有索引,MySQL不得不首先以第一条记录开始,然后读完整个表直到它找出相关的行。表越大,花费时间越多。
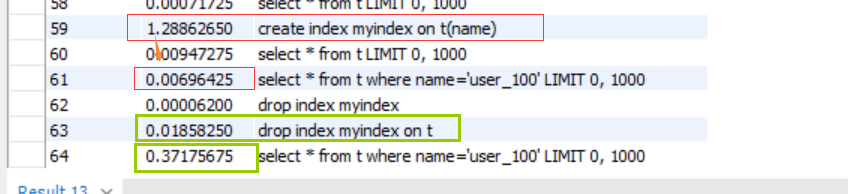
上图:红色为创建索引后的查询时间,绿色为删除索引后同一条语句的查询时间。
4、什么时候使用索引
● 表中该字段中的数据量庞大
● 经常被检索,经常出现在where子句中的字段
● 经常被DML操作的字段不建议添加索引
5、创建索引
语句:create index 索引名 on 表名(字段名)
alter table 表名 add index 索引名(字段)
示例:create index myindex on t(name);
alter table t add index(name);
注:主键,unique 都会默认的添加索引
6、查看索引
show index from 表名;

7、删除索引
drop index 索引名 ON 表名;
alter table 表名 drop index 索引名;