这篇博文将会展示如何采用一个预训练的深度学习网络(模型)在ImageNet的数据集并把它当作输入图像。
首先说明,运行环境为Ubuntu16.04(或者MacOS),windows暂不支持,已经编译好的OpenCV3.3.0,如何查看以及是否编译OpenCV3.3.0成功,请看博文:http://www.cnblogs.com/wmr95/p/7638985.html
OpenCV并不是(也不打算)作为一个工具来训练网络,这里已经有更伟大的框架来完成这件事情。新版OpenCV兼容以下热门网络架构:
OpenCV并不是(也不打算)作为一个工具来训练网络,这里已经有更伟大的框架来完成这件事情。新版OpenCV兼容以下热门网络架构:
GoogleLeNet (used in this blog post)
AlexNet
SqueezeNet
VGGNet (and associated flavors)
ResNet
用OpenCV和深度学习给图像分类
接下来,我们将创建一个Python脚本,该脚本可用于使用Caffe框架使用OpenCV和GoogLeNet(在ImageNet上进行预培训)对输入图像进行分类。
同时,让我们学习如何加载预先训练好的Caffe模型,并使用它来使用OpenCV对图像进行分类。
首先,打开一个新文件,将其命名为deep_learning_with_opencv.py ,插入如下代码,来导入我们需要的包:

然后我们解析命令行参数:
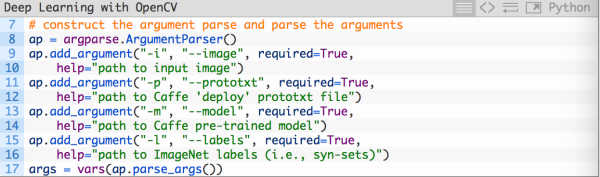
--image : The path to the input image.
--prototxt : The path to the Caffe “deploy” prototxt file.
--model : The pre-trained Caffe model (i.e,. the network weights themselves).
--labels : The path to ImageNet labels (i.e., “syn-sets”).
然后加载输入图像和标签:

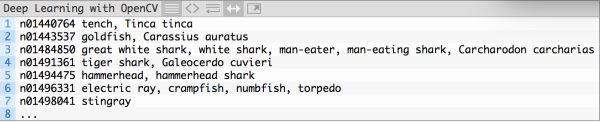
接下来,让我们看下OpenCV3.3的dnn模块:

然后,我们从磁盘加载预训练好的模型:

我们用cv2.dnn.readNetFromCaffe来加载Caffe模型定义prototxt,以及预训练模型。
接下来,我们以blob为输入,在神经网络中完成一次正向传播:
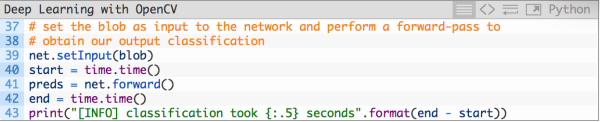
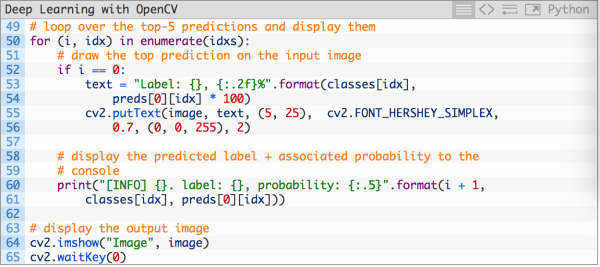
最后,我们来为输入图像取出5个排名最高的预测结果:

我们来选取排名前5的结果,然后将他们显示出来:
以上是关于OpenCV3.3的dnn模型的介绍,下面在本地上完成模型的输出:
1.首先下载源代码以及预训练的GoogleNet架构以及示例图片,链接我在下面的原文链接中给出,直接找到”Downloads“输入邮箱获取;
2.打开ternimal,cd到你下载的路径下,输入下面的命令:
$ python deep_learning_with_opencv.py --image images/jemma.png
--prototxt bvlc_googlenet.prototxt
--model bvlc_googlenet.caffemodel --labels synset_words.txt
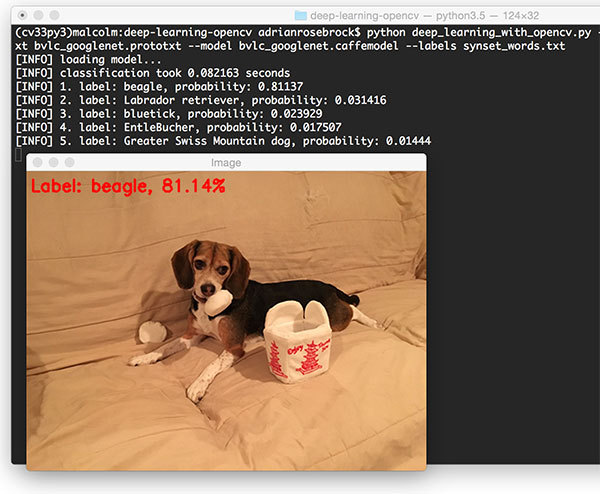
运行成功的话会在ternimal下显示:
[INFO] loading model...
[INFO] classification took 0.075035 seconds
[INFO] 1. label: beagle, probability: 0.81137
[INFO] 2. label: Labrador retriever, probability: 0.031416
[INFO] 3. label: bluetick, probability: 0.023929
[INFO] 4. label: EntleBucher, probability: 0.017507
[INFO] 5. label: Greater Swiss Mountain dog, probability: 0.01444
当然你还可以尝试其他图片,现在你已经成功运用预训练的模型实现图像分类啦。
附上原文链接:https://www.pyimagesearch.com/2017/08/21/deep-learning-with-opencv/
项目地址:https://github.com/wanglaotou/deeplearning-opencv
版权声明:
作者:王老头
出处:http://www.cnblogs.com/wmr95/p/7640017.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,并在文章页面明显位置给出原文链接,否则,作者将保留追究法律责任的权利。