
一个算法解决一个问题,算法是无止尽的,重要的是要学会需求分析和画图,再转换成代码实现的编程思想;
一、数组和链表
数组只能通过索引访问元素;
集合,是一个概念,只要能存放数据的容器并能动态大小,都是集合;
1、ArrayList自己实现,基于数组

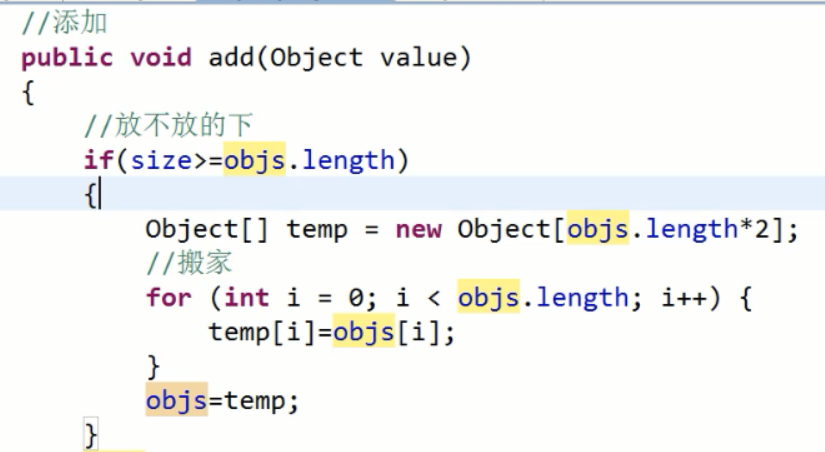
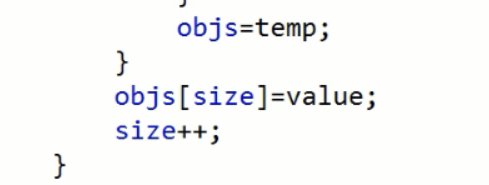
引用对象赋值实际是赋值的地址值,temp地址值再赋值给objs,保证始终操作的是objs对象名;
size是实际元素个数,保证不能访问没有元素的索引;
修改某个索引对应元素:

删除某索引对应元素:

从删除的索引位置开始,后面所有的元素都向前移动一位,如排队;
清除集合:

size=0就是逻辑清除,访问不到了,并没有正在清除;
2、LinkedList实现
2.1节点类
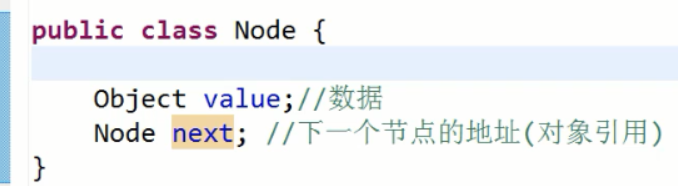
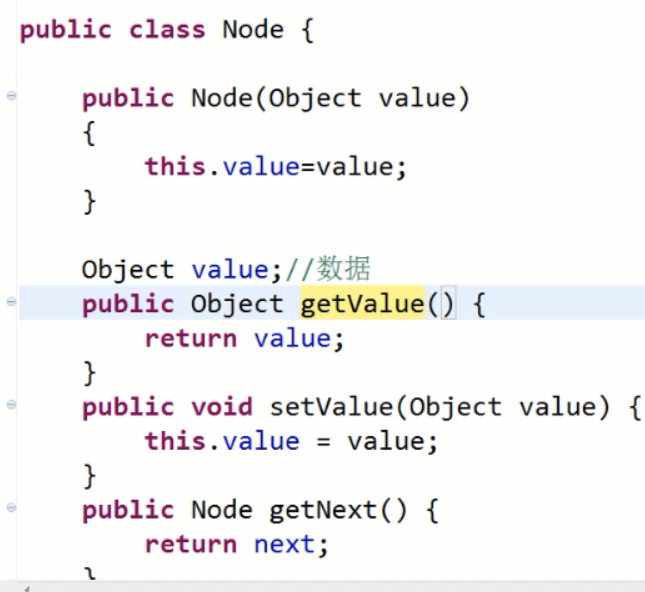
java没有正在直接操作地址值的指针,有对应地址值的引用;
2.2 LinkedList实现



设置和获取已存在某位置的节点的元素值:


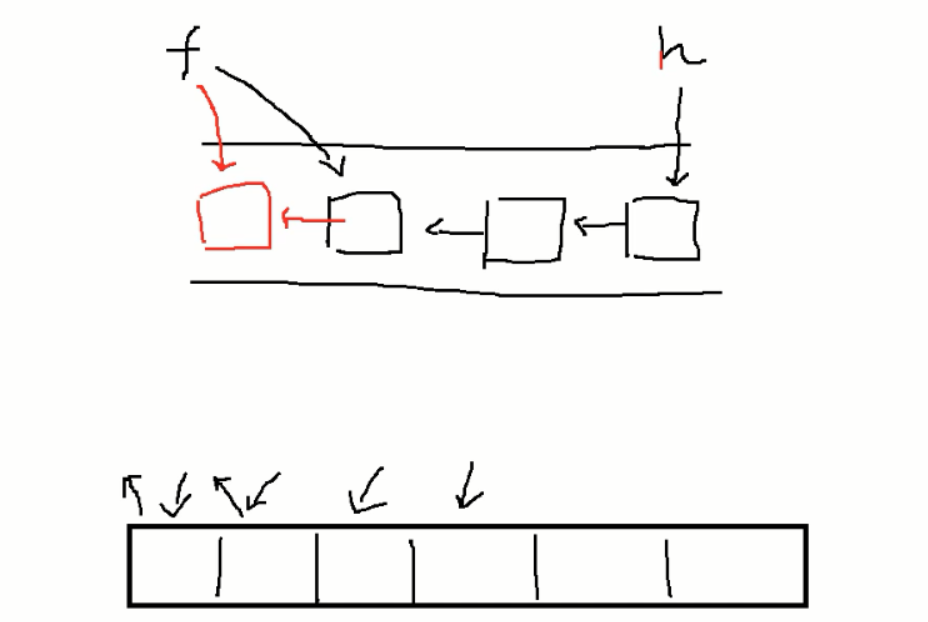
移除一个元素:

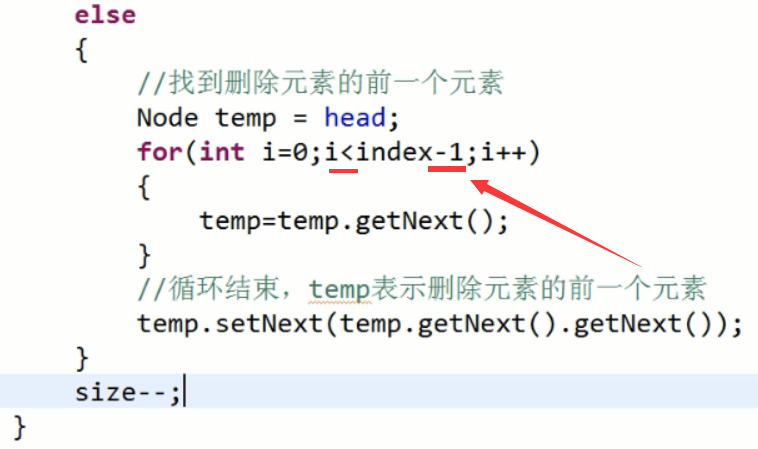
只需要将链表上的前一个元素的指向下一个元素的地址值改成被移除的元素的下一个就可以;
链表的元素本就是散落存在的,没有实际的连线,就是通过引用对象名肯定会存储表头结点的地址,然后从表头开始挨个访问下一个结点地址;

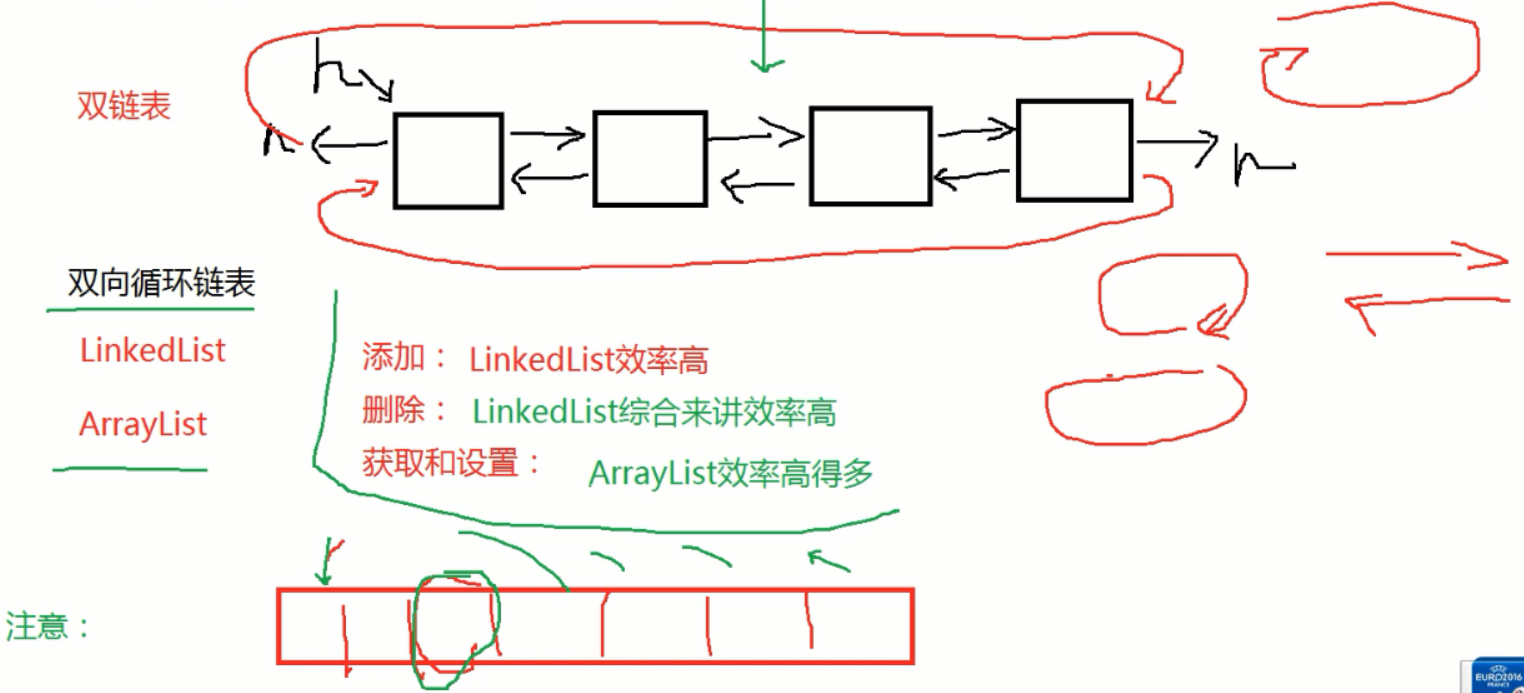
数组,删除添加时候,后面的所有元素的位置都要移动一位,多的时候效率很低,如果长度不够了,还要“搬家”,小数组搬到大数组里面,arr.length*3/2+1;查找时候,地址值连续,有索引,二分查找,速度极快;
链表,for循环遍历的话,外面for本身循环一次,里面链表自己没有索引也要循环找到当前for循环的这一步,嵌套循环,没有索引,效率很低,使用for each 迭代器遍历;增删时候只需改前后指针(引用对象节点地址值),增删很快,还是要先遍历找到要修改的值,所以增删时候双向循环链表首尾一样很快,中间最慢;
二、栈
1、栈的实现
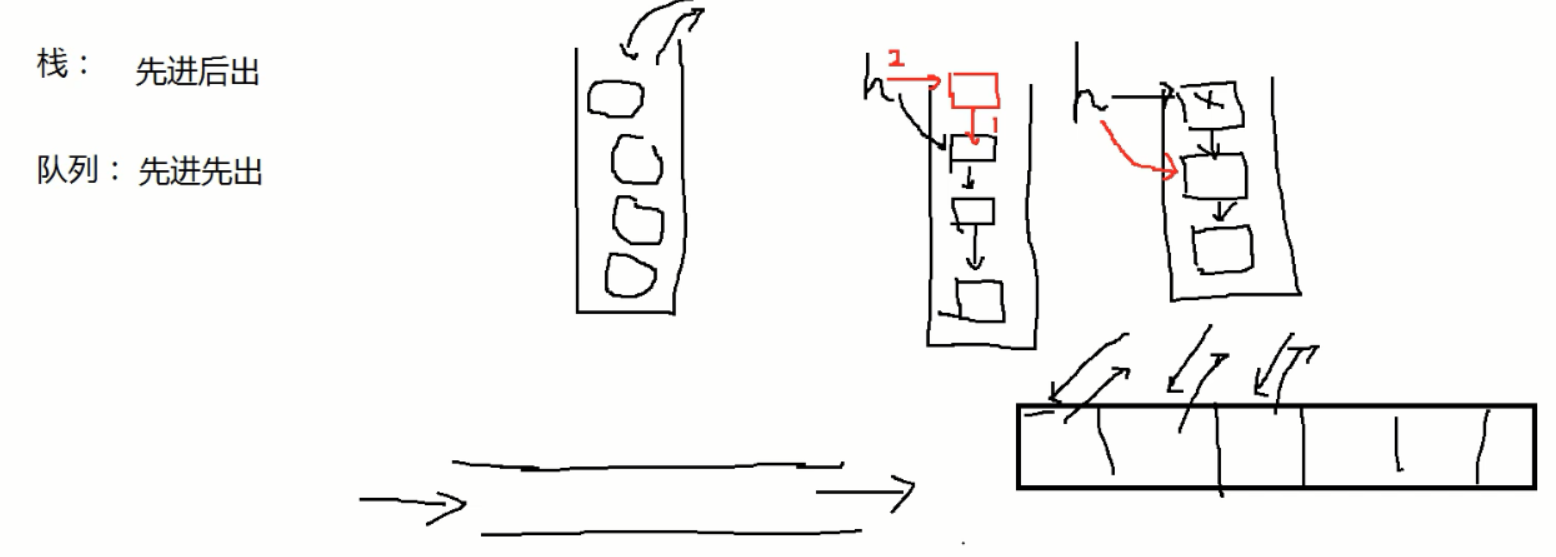
使用队列效率更高,只需要处理尾节点;
队列使用链表也是一样,只需要处理尾结点,无需遍历,效率更高;
