一、concurentMap
1、数据结构,分段数组segment不扩容,里面的table扩容,每次翻倍,table中放的是entry链表的头地址;
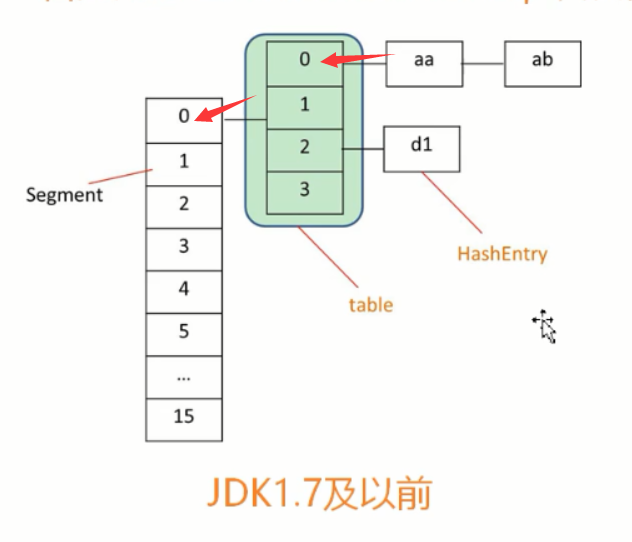
2、初始化


segment和table的长度都是2的幂次方,方便位运算,位运算扩容之后可以保证原先的元素排列不变;
用于定位元素所在segment。segmentShift表示偏移位数,通过前面的int类型的位的描述我们可以得知,int类型的数字在变大的过程中,低位总是比高位先填满的,为保证元素在segment级别分布的尽量均匀,计算元素所在segment时,总是取hash值的高位进行计算。segmentMask作用就是为了利用位运算中取模的操作:l a % (Math.pow(2,n)) 等价于 a&( Math.pow(2,n)-1)
3、get、put方法;
实现原理都是先通过hashcode位运算,找出在segment中的位置,key的hashcode再散列,找出在table中的位置,再确定equals是否相等,判定是否重复;
所以equals和hashCode方法要一起重写;

put时候是加锁的,所以线程安全;
get时候不加锁,所以是弱一致性;如何保证线程安全,修饰value时候用了volatile;

4、ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它们就可以并发进行
二、jdk1.8之后concurrentMap
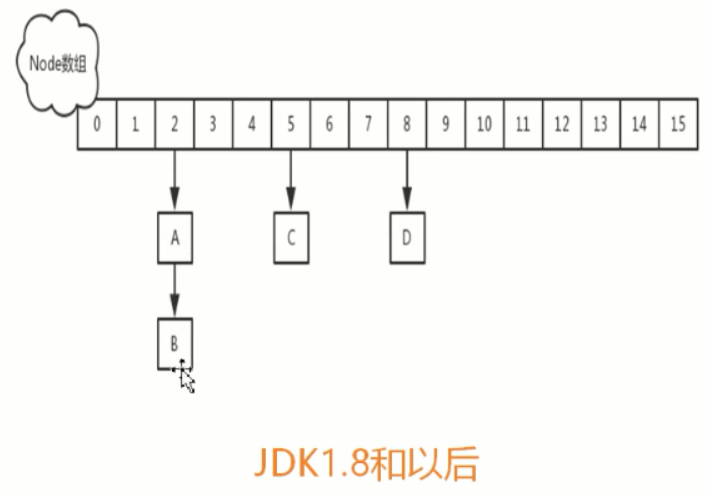
值少用链表结构简单,多的时候用红黑树,查询时间复复杂度低logn,但是结构实现复杂;
与1.7相比的重大变化
1、 取消了segment数组,直接用table保存数据,锁的粒度更小,减少并发冲突的概率。
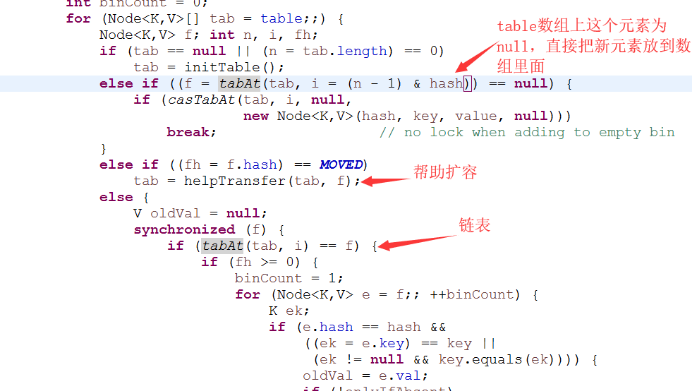
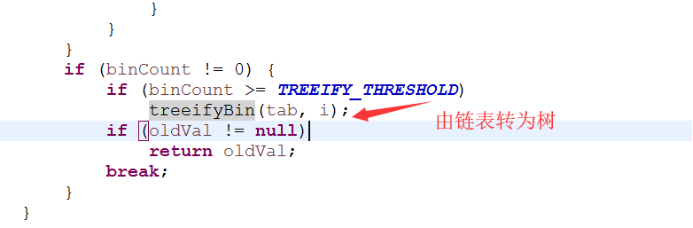
2、 存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大。什么时候链表转红黑树?当key值相等的元素形成的链表中元素个数超过8个的时候。非树化是6个时候
主要数据结构和关键变量
Node类存放实际的key和value值。
sizeCtl:
负数:表示进行初始化或者扩容,-1表示正在初始化,-N,表示有N-1个线程正在进行扩容
正数:0 表示还没有被初始化,>0的数,初始化或者是下一次进行扩容的阈值
TreeNode 用在红黑树,表示树的节点, TreeBin是实际放在table数组中的,代表了这个红黑树的根
初始化做了什么事?
只是给成员变量赋值,put时进行实际数组的填充
在get和put操作中,是如何快速定位元素放在哪个位置的?
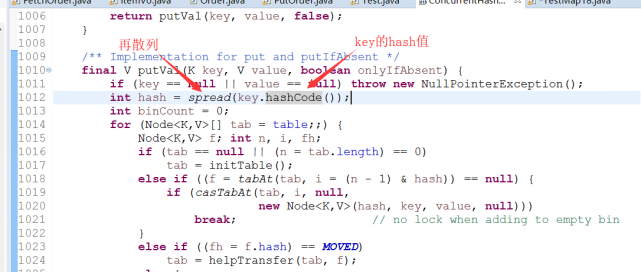
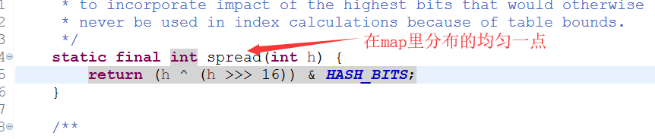
get()方法

put()方法
数组的实际初始化


扩容操作
transfer()方法进行实际的扩容操作,table大小也是翻倍的形式,有一个并发扩容的机制,put时候发现在扩容会帮助扩容。
size方法
估计的大概数量,不是精确数量
一致性
弱一致