一、今日学习内容
1、获取疫情的url【腾讯新闻肺炎疫情】:
通过打开开发者工具,我们可以看到这样的画面,其次,我们需要找到指向数据的url:
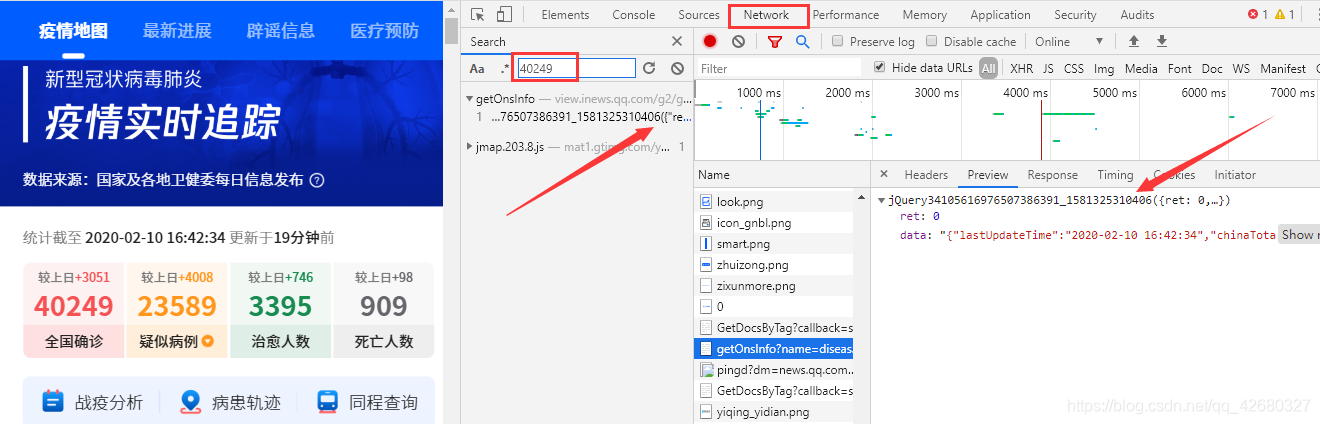
因此我们可以得到如下数据:
https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5
2、为了避免反爬,伪装成浏览器:
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
3、分析url,找到数据存放的规律:

从上图杂乱无章的json数据中,我们不难找到如下规律:

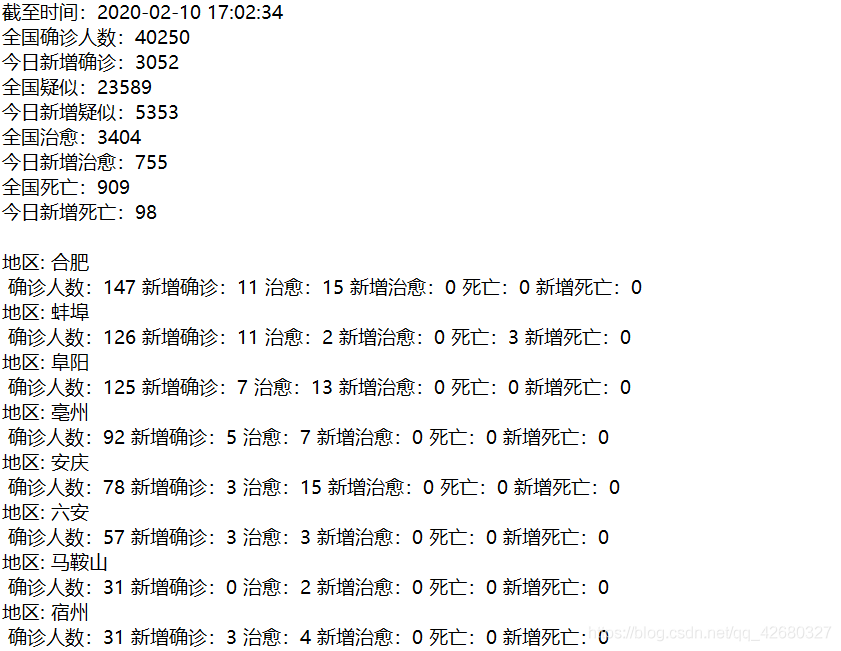
效果如图:
#author_='zhi'; #date: 2020/2/10 17:01 import requests import json def Down_data(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5' headers = { 'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36' } r = requests.get(url, headers) res = json.loads(r.text) data_res = json.loads(res['data']) return data_res def Parse_data1(): data = Down_data() list = ['截至时间:' + str(data['lastUpdateTime']) + ' ' '全国确诊人数:' + str(data['chinaTotal']['confirm']) + ' ' '今日新增确诊:' + str(data['chinaAdd']['confirm']) + ' ' '全国疑似:' + str(data['chinaTotal']['suspect']) + ' ' '今日新增疑似:' + str(data['chinaAdd']['suspect']) + ' ' '全国治愈:' + str(data['chinaTotal']['heal']) + ' ' '今日新增治愈:' + str(data['chinaAdd']['heal']) + ' ' '全国死亡:' + str(data['chinaTotal']['dead']) + ' ' '今日新增死亡:' + str(data['chinaAdd']['dead']) + ' '] result = ''.join(list) with open('疫情查询.txt', 'a+', encoding="utf-8") as f: f.write(result + ' ') def Parse_data2(): data = Down_data()['areaTree'][0]['children'] path = str(input('请输入你要查询的省份:')) for i in data: if path in i['name']: for item in i['children']: list_city = [ '地区: ' + str(item['name']) + ' ' ' 确诊人数:' + str(item['total']['confirm']), ' 新增确诊:' + str(item['today']['confirm']), ' 治愈:' + str(item['total']['heal']), ' 新增治愈:' + str(item['today']['heal']), ' 死亡:' + str(item['total']['dead']), ' 新增死亡:' + str(item['today']['dead']) + ' ' ] res_city = ''.join(list_city) with open('疫情查询.txt', 'a+', encoding="utf-8") as f: f.write(res_city) Down_data() Parse_data1() Parse_data2()