一 模块介绍
一个模块就是一个包含了一组功能的python文件,比如spam.py,模块名为spam,可以通过import spam使用。
在python中,模块的使用方式都是一样的,但其实细说的话,模块可以分为四个通用类别:
1 使用python编写的.py文件
2 已被编译为共享库或DLL的C或C++扩展
3 把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
4 使用C编写并链接到python解释器的内置模块
示例文件
#spam.py
print('from the spam.py')
money=1000
def read1():
print('spam模块:',money)
def read2():
print('spam模块')
read1()
def change():
global money
money=0
py文件区分两种用途:模块与脚本
#编写好的一个python文件可以有两种用途:
一:脚本,一个文件就是整个程序,用来被执行
二:模块,文件中存放着一堆功能,用来被导入使用 #python为我们内置了全局变量__name__,
当文件被当做脚本执行时:__name__ 等于'__main__' 当文件被当做模块导入时:__name__等于模块名
#作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
import
import的本质:
import spam:相当于把spam文件下所有代码解释一遍(类似于print的代码直接运行了),然后赋值给spam,这样一来就能spam.money,spam.read2()调用了
模块导入时到底发生了是么?
- 当模块第一次被导入时,先为源文件(spam模块)创建新的名称空间,然后在该命名空间解释代码(相当于执行源文件),最后创建名字spam来引用该命名空间,这样就可以通过spam.xx访问。
- 当再次导入相同文件时,由于第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句。
- ps:我们可以从sys.module中找到当前已经加载的模块,sys.module是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
#test.py import spam #只在第一次导入时才执行spam.py内代码,此处的显式效果是只打印一次'from the spam.py',当然其他的顶级代码也都被执行了,只不过没有显示效果. import spam import spam import spam ''' 执行结果: from the spam.py '''
导入模块还有别的方式,例如:
import spam
import spam,spam1
from spam import *(把spam中所有的不是以下划线(_)开头的名字都导入到当前位置)(不建议使用)
from spam import money,read1
from spam import money,read1 as spam_read1
- from spam import * 因为会吧spam文件所有的变量,函数都导入,可能会与本身文件变量,函数有冲突,不建议使用
- 通过from导入的模块,使用时,不能再用spam.xx来使用,只能直接xx或者xxx()来使用。
- 当用from导入的变量或函数与本文件产生冲突(名字相同)时,以本文件的为优先
导入模块时:
首先,会根据sys.path进行寻找,在sys.path对应的路径中找是否有需要导入的模块,没找到就报错,可以通过sys.path.append()和sys.path.insert()来添加需要的路径。
文件的__file__属性代表当前文件的文件名,os.path.abspath(__file__)代表获取当前文件的绝对路径,os.path.dirname()获取目录名(相当于上一级)。eg:
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path 输出是一个列表,其中第一项是空串'',代表当前目录(若是从一个脚本中打印出来的话,可以更清楚地看出是哪个目录),亦即我们执行python解释器的目录(对于脚本的话就是运行的脚本所在的目录)。
包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
这样不同的作者都可以提供 NumPy 模块,或者是 Python 图形库。
不妨假设你想设计一套统一处理声音文件和数据的模块(或者称之为一个"包")。
这里给出了一种可能的包结构(在分层的文件系统中):
sound/ 顶层包
__init__.py 初始化 sound 包
formats/ 文件格式转换子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 声音效果子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ filters 子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo
这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)
注意当使用from package import item这种形式的时候,对应的item既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import语法会首先把item当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,恭喜,一个:exc:ImportError 异常被抛出了。
反之,如果使用形如import item.subitem.subsubitem这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
导入包的实质就是执行包的__init__.py文件
使用import 包名 # 相当于执行__init__.py,在__init__.py文件里也可以import导入模块,未在__init__.py中导入的模块尽管导入了包名也无法使用
使用import 包名.模块名 # 如此只能导入包中的一个模块,调用时也需要包名.模块名.方法名这样调用(用as优化),带路径的导入也是如此:(模块包名.[路径(子包).]模块名)
使用from 包名 import * # 这样会先找__init__.py中叫__all__ 的列表变量,把这个列表中的所有名字作为包内容导入。
- 当__all__未定义时,from 包名 import *这种方式会执行__init__.py,若__init__.py文件中导入了模块,则会把模块导入
- 当__all__定义了但是为空时,from 包名 import *这种方式也会执行__init__.py,若__init__.py文件中导入了模块,会对模块进行解释(相当于运行),但是无法使用该模块。因为__all__定义了,则只会导入__all__里的模块,但是其为空,所以值会执行__init__.py,对__init__.py文件导入的模块进行解释,却不能使用这些模块。
- 当__all__定义了且不为空时,from 包名 import *这种方式执行__init__.py,对__init__.py文件中导入的模块进行解释,但是只能使用__all__中的模块
包以及包所包含的模块都是用来被导入的,而不是被直接执行的。而环境变量都是以执行文件为准的
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,十分开心的就去做了,它直接这么做
在version.py中 import policy policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance同级下的一个test.py文件中导入version.py,如下
from glance.api import versions ''' 执行结果: ImportError: No module named 'policy' ''' ''' 分析: 此时我们导入versions在versions.py中执行 import policy需要找从sys.path也就是从当前目录找policy.py, 这必然是找不到的 '''
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回: >>> import spam, sys >>> dir(spam) ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'change', 'money', 'read1', 'read2'] >>> dir(sys) ['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags', 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount', 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'thread_info', 'version', 'version_info', 'warnoptions']
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
>>> a = [1, 2, 3, 4, 5] >>> import fibo >>> fib = fibo.fib >>> dir() # 得到一个当前模块中定义的属性列表 ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] >>> a = 5 # 建立一个新的变量 'a' >>> dir() ['__builtins__', '__doc__', '__name__', 'a', 'sys'] >>> >>> del a # 删除变量名a >>> >>> dir() ['__builtins__', '__doc__', '__name__', 'sys'] >>>
绝对导入
关于这句from __future__ import absolute_import的作用:
直观地看就是说”加入绝对引入这个新特性”。说到绝对引入,当然就会想到相对引入。那么什么是相对引入呢?比如说,你的包结构是这样的:
pkg/
pkg/init.py
pkg/main.py
pkg/string.py
如果你在main.py中写import string,那么在Python 2.4或之前, Python会先查找当前目录下有没有string.py, 若找到了,则引入该模块,然后你在main.py中可以直接用string了。如果你是真的想用同目录下的string.py那就好,但是如果你是想用系统自带的标准string.py呢?那其实没有什么好的简洁的方式可以忽略掉同目录的string.py而引入系统自带的标准string.py。这时候你就需要from __future__ import absolute_import了。这样,你就可以用import string来引入系统的标准string.py, 而用from pkg import string来引入当前目录下的string.py了
相对导入(各种坑)
相对导入
如果在结构中包是一个子包(比如这个例子中对于包sound来说),而你又想导入兄弟包(同级别的包)你就得使用导入绝对的路径来导入。比如,如果模块sound.filters.vocoder 要使用包sound.effects中的模块echo,你就要写成 from sound.effects import echo。from后面一个点代表同级目录,两个点代表上级目录。
from . import echo from .. import formats from ..filters import equalizer
下面是相对导入需要注意的几点
1.如果要将一个文件夹目录当做package的话,必须要在该目录下加一个__init__.py的文件(注意是两个下划线连在一起__),否则将无法作为一个package;
2.执行模块是程序入口模块时(__name__ == '__main__'),不能使用相对导入。因为在程序入口模块执行时,__name__这个变量值是”__main__”。而相对引用符号”.”的就是对应__name__这个变量。当这个模块是在别的模块中被导入使用,此时的”.”就是原模块的文件名。在main函数中执行时,此时”.”变成了”__main__”。(会出现No module named '__main__.xxxx'; '__main__' is not a package)
3.虽然第二点说了,程序入口模块不能使用相对导入,那么在程序入口模块中随意调用别的模块进行相对导入不就行了?emmmm太天真了,与程序入口模块在同一目录下的模块也无法使用相对导入,否则会出现(ImportError: attempted relative import with no known parent package)解决模块的算法是基于__name__和__package__变量的值。大部分时候,这些变量不包含任何包信息 —- 比如:当 __name__ = __main__ 和 __package__ = None(第三点属于None) 时,python解释器不知道模块所属的包。在这种情况下,相对引用会认为这个模块就是顶级模块,而不管模块在文件系统上的实际位置。
4.执行脚本时,会把当前项目目录和执行文件的目录加入到sys.path中
下面给出报错示例:首先请看目录结构(请自行忽略8级汉语拼音)
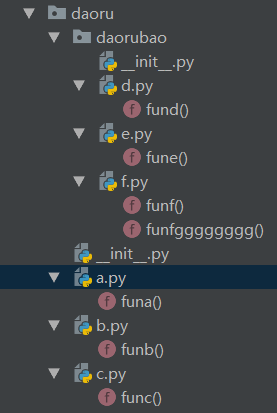
在abc三个文件中互相import a这种导入时一点问题都没有,但一旦换成相对导入
1.例如在a.py中写
from . import b from .b import funb from .daorubao import d
这三种写法都会报错,想想属于哪种错?答案是相对导入注意的第二点,执行模块是程序入口模块时不能使用相对导入
修改方法是把后两行的.去掉即可
2.在c.py中写
from .a import funa from .daorubao import d
然后在b.py中写
import c
然后运行b.py,这时,c.py中的两行语句无论哪一行都会报错,错误参考相对导入注意第三点
解决方法依然是吧c.py中的两行语句的.去掉即可
3.在e.py中写
from . import f from .f import *
然后在a.py中写
from daorubao import e
这个时候会出现。。emmm不会出现错误,因为这时e中的相对导入可以使用,不是入口程序,也不和入口程序在同一目录下
__all__属性在模块与包中的应用
在包中
在包中__all__的使用在上文有提到,总结来说就是使用from 包名 import *时,会先找__init__.py中叫__all__ 的列表变量
- 当__all__未定义时,from 包名 import *这种方式会执行__init__.py,若__init__.py文件中导入了模块,则会把模块导入
- 当__all__定义了但是为空时,from 包名 import *这种方式也会执行__init__.py,若__init__.py文件中导入了模块,会对模块进行解释(相当于运行),但是无法使用该模块。因为__all__定义了,则只会导入__all__里的模块,但是其为空,所以值会执行__init__.py,对__init__.py文件导入的模块进行解释,却不能使用这些模块。
- 当__all__定义了且不为空时,from 包名 import *这种方式执行__init__.py,对__init__.py文件中导入的模块进行解释,但是只能使用__all__中的模块
在模块中
用于模块导入时限制,也是只有使用
from 模块名 import *时,被导入模块若定义了__all__属性,则只有__all__内指定的属性、方法、类可被导入。若没定义,则导入模块内的所有公有属性,方法和类 。
详见https://blog.csdn.net/sxingming/article/details/52903377
特别注意一下这种
def func(): # 模块中的public方法
print('func() is called!')
def _func(): # 模块中的protected方法
print('_func() is called!')
def __func(): # 模块中的private方法
print('__func() is called!')
importlib
Python将importlib作为标准库提供。它旨在提供Pythonimport语法和(__import__()函数)的实现。另外,importlib提供了开发者可以创建自己的对象(即importer)来处理导入过程。
那么imp呢?还有一个imp模块提供了import语句接口,不过这个模块在Python3.4已经deprecated了。建议使用importlib来处理。
下面是简单使用:
import importlib
# 根据字符串导入模块
# 通常用来导入包下面的模块
o = importlib.import_module("xx.oo")
s2 = "Person"
# 由字符串找函数、方法、类 利用 反射
the_class = getattr(o, "Person")
p2 = the_class("小黑")
p2.dream()
动态导入
importlib模块支持传递字符串来导入模块。我们先来创建一些简单模块一遍演示。我们在模块里提供了相同接口,通过打印它们自身名字来区分。我们分别创建了foo.py和bar.py,代码如下:
def main():
print(__name__)
现在我们尽需要使用importlib导入它们。我们来看看代码是如何实现的,确保该代码在刚才创建的两个文件的相同目录下。
#importer
import importlib
def dynamic_import(module):
return importlib.import_module(module)
if __name__ == "__main__":
module = dynamic_import('foo')
module.main()
module2 = dynamic_import('bar')
module2.main()
这里我们导入importlib模块,并创建了一个非常简单的函数dynamic_import。这个函数直接就调用了importlib的import_module方法,并将要导入的模块字符串传递作为参数,最后返回其结果。然后在主入口中我们分别调用了各自的main方法,将打印出各自的name.
$ python3 importer.py
foo
bar
也许你很少会代码这么做,不过在你需要试用字符串作为导入路径的话,那么importlib就有用途了。
模块导入检查
Python有个众所周知的代码风格EAFP: Easier to ask forgiveness than permission.它所代表的意思就是总是先确保事物存在(例如字典中的键)以及在犯错时捕获。如果我们在导入前想检查是否这个模块存在而不是靠猜。 使用mportlib就能实现。
import importlib.util
def check_module(module_name):
"""
Checks if module can be imported without actually
importing it
"""
module_spec = importlib.util.find_spec(module_name)
if module_spec is None:
print("Module: {} not found".format(module_name))
return None
else:
print("Module: {} can be imported".format(module_name))
return module_spec
def import_module_from_spec(module_spec):
"""
Import the module via the passed in module specification
Returns the newly imported module
"""
module = importlib.util.module_from_spec(module_spec)
module_spec.loader.exec_module(module)
return module
if __name__ == '__main__':
module_spec = check_module('fake_module')
module_spec = check_module('collections')
if module_spec:
module = import_module_from_spec(module_spec)
print(dir(module))
这里我导入了importlib的子模块util。check_module里面调用find_spec方法, 传递该模块字符串作为参数。当我们分别传入了一个不存在和存在的Python模块。你可以看到当你传入不存在的模块时,find_spec函数将返回 None,在我们代码里就会打印提示。如果存在我们将返回模块的specification。
我们可以通过该模块的specification来实际导入该模块。或者你直接将字符串作为参数调用import_module函数。不过我这里也学习如何试用模块specification方式导入。看看import_module_from_spec函数。它接受check_module提供的模块specification作为参数。然后我们将它传递给了module_from_spec函数,它将返回导入模块。Python文档推荐导入后然后执行模块,所以接下来我们试用exec_module函数执行。最后我们使用dir来确保得到预期模块。
从源代码导入
importlib的子模块有个很好用的技巧我想提提。你可以使用util通过模块的名字和路径来导入模块。
import importlib.util
def import_source(module_name):
module_file_path = module_name.__file__
module_name = module_name.__name__
module_spec = importlib.util.spec_from_file_location(
module_name, module_file_path
)
module = importlib.util.module_from_spec(module_spec)
module_spec.loader.exec_module(module)
print(dir((module)))
msg = 'The {module_name} module has the following methods {methods}'
print(msg.format(module_name=module_name, methods=dir(module)))
if __name__ == "__main__":
import logging
import_source(logging)
在上面的代码中,我们实际导入logging模块,并将模块传递给了import_source函数。这样我们就可以通过导入的模块获取到实际的路 径和名字。然后我们将信息传递给sec_from_file_location函数,它将返回模块的specification。也了这个我们就可以在前 面那样直接通过importlib导入了。
总结目前,你知道如何在代码中使用importlib和import钩子。这个模块内容非常多,如果你想自定义importer或者loader,那么你可以通过官方文档或者源代码了解更多。