elasticsearch设计的理念就是分布式搜索引擎,底层其实还是基于lucene的,通过倒排索引的方式快速查询。比如一本书的目录是索引,然后快速找到每一章的的文本内容这种叫正向索引;而如果一件衣服比如有:蓝色,389元,L码这些信息,我们通过搜索这些信息就能找到这条记录,这就叫倒排索引,实际就是通过分词、重组、来共享前缀存储索引。
倒排索引
比如有5条数据,左边是id右边是名称,我要查询名字包含james的记录,就需要把所有记录遍历一遍才行。
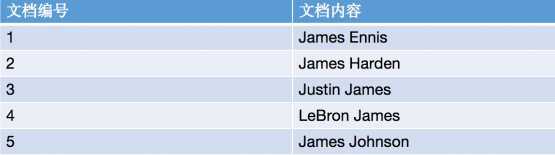
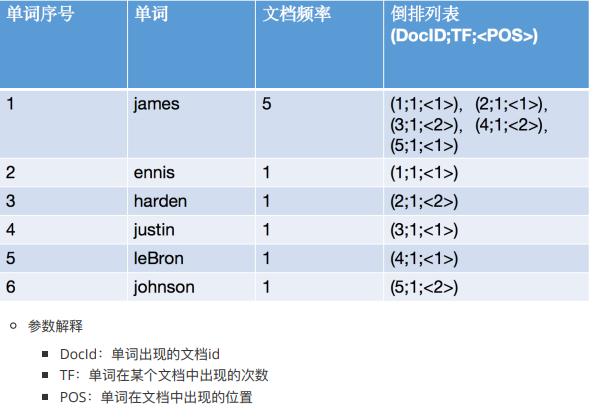
如果我们把名字进行分词,然后对这些分词进行分组,统计它所在的文档位置就好了。倒排索引会记录每个分词锁出现的次数,以及这些分词存在于那些doc中等等一系列信息。
es中存储数据的基本单位是索引,比如说你现在要在es中存储一些订单数据,你就应该在es中创建一个索引,order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是mysql里的数据库。index -> type -> mapping -> document -> field。
index:mysql数据库
type:就像一张表。ES5.X中一个index可以有多个type、
ES6.X中一个type只能有一个type、
ES7.X中移除了type这个概念,此时的index就像一张表了。
mapping:定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
document:一条document就代表了mysql表里的一条记录。
field:每个field就代表了这个document中的一个字段的值。
ES如何实现分布式的(es架构原理)
创建一个索引,这个索引可以拆分成多个shard,每个shard存储部分数据。每个shard的数据实际是有多个备份,就是说每个shard都有一个主分片写数据、还有一个或多个副分片同步数据(主副并不在一个服务上),es集群多个节点会自动选一个为master节点,这个节点其实就是干一些管理的工作的,比如维护索引元数据拉,负责切换 主/副节点 的身份之类的;如果一个节点的主分片挂了,副分片会切换为主分片,一个主分片及其所有副分片都挂了,集群就崩塌了。一个集群中会有以下几个角色:
集群(cluster)
集群由一个或多个节点组成,一个集群有一个默认名称"elasticsearch"。
节点(node)
一个Elasticsearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例应该会部署在不同的机器上。Elasticsearch 的配置文件中可以通过 node.master、node.data 来设置节点类型。node.master:表示节点是有资格竞选为主节点的资格。node.data:表示节点是否存储数据。
主节点+数据节点:即有成为主节点的资格,又存储数据
node.master: true
node.data: tru
数据节点:节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
客户端节点:不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进⾏负载均衡
node.master: false
node.data: false
分片和副本(shard)
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片( primary shard)和副分片(replica shard),副分片是主分片的拷贝。默认每个主分片有一个副分片,一个索引的副分片的数量可以动态地调整,副分片从不与它的主分片在同一个节点上。
ES 读/写 数据过程
写入文档
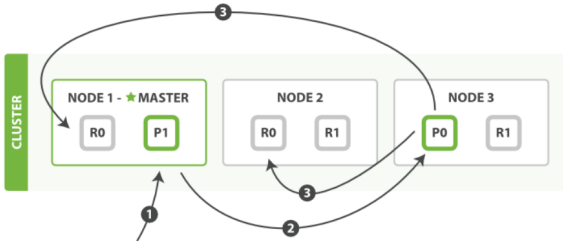
1. 客户端向任意一个节点发送新增文档请求,比如node1(此时node1就成了协调节点)。
2. 节点对这个document进行路由,发现这个document属于主分片P0,因为P0在node3上,所以请求会转发到node3.
3. document在P0上新增成功后,会转发到node1、node2上的副分片R0 R1。
4. node1发现他们都搞定之后,就会将结果响应给客户端。
读取文档
1. 客户端向任意一个节点发送读请求,比如node2(此时node2就成了协调节点)。
2. node2对document进行路由,将请求转发到对应的node,比如node1。
3. 此时会使用round-robin随机轮询算法,然后对其所有主副节点随机选择一个,让读请求负载均衡。
4. node1处理完成之后将结果给node2,node2将结果响应给客户端。
路由算法
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing默认是文档的id,也可以自定义,hash(routing)后得到一个数字,再对主分片个数取余,这个数字肯定是0~number_of_primary_shards-1 之间的余数,就是我们文档所在的位置。所以我们在创建索引的时候就要确定好主分片个数,并永远不修改,否则就找不到之前的数据了。
es大量数据(数十亿级别)时,如何提高查询效率
1. filesystem cache
往es写入数据时,其实就是写入到磁盘中的。而es的搜索引擎底层是严重依赖于文件系统缓存的,es所有的indx segment file索引数据文件就存在这里面,如果filesystem cache的内存够大,那么你搜索的时候基本就是走内存的,性能会很高。打个比方说:
es节点有3台机器,每台机器,看起来内存很多,64G,总内存,64 * 3 = 192g;每台机器给es jvm heap是32G,那么剩下来留给filesystem cache的就是每台机器才32g,总共集群里给filesystem cache的就是32 * 3 = 96g内存。如果有1T的数据量,那就只有10%的索引文件被存到file cache里面去,效率肯定是比较低的,就是你的机器的内存,至少可以容纳你的总数据量的一半。
2. 数据预热/冷热分离
预热:比如file cache有50g内存,而数据超过了100g怎么办呢?我们可以做一个后台系统定时去拉取一些容易被人访问的数据。因为我们查询es时,它会重新记录这个索引的信息、进行排序将这些数据放到file cache中。
冷热分离:大量不搜索的字段拆到别的index里面去,就有点像mysql的垂直拆分,这样可以确保热数据在被预热之后,尽量都让他们留在filesystem os cache里,别让冷数据给冲刷掉。热数据可能就占总数据量的10%,此时数据量很少,几乎全都保留在filesystem cache里面了,就可以确保热数据的访问性能是很高的。
3. document模型设计
es里面的复杂的关联查询,复杂的查询语法,尽量别用,一旦用了性能一般都不太好。有关联的最好写入es的时候,搞成两个索引,order索引,orderItem索引,order索引里面就包含id order_code total_price;orderItem索引直接包含id order_code total_price id order_id goods_id purchase_count price,这样就不需要es的语法来完成join了。
4. 分页性能优化
es的分页是较坑的,假如你每页是10条数据,你现在要查询第100页,实际上是会把每个shard上存储的前1000条数据都查到一个协调节点上,如果你有个5个shard,那么就有5000条数据,接着协调节点对这5000条数据进行一些合并、处理,再获取到最终第100页的10条数据。翻页的时候,翻的越深,每个shard返回的数据就越多,而且协调节点处理的时间越长。非常坑爹。所以用es做分页的时候,你会发现越翻到后面,就越是慢。有2个折中的优化方案:
1 不允许分页,直接把数据给客户端(这么说估计会被打)。
2 允许一页页的翻但是不允许选择页数,就像app的推荐商品一样。用scroll api一页页去刷,scroll的原理实际上是保留一个数据快照,然后在一定时间内,你如果不断的滑动往后翻页的时候,类似于你现在在浏览微博,不断往下刷新翻页。那么就用scroll不断通过游标获取下一页数据,这个性能是很高的,比es实际翻页要好的多的多。