一、作业内容
作业一:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
关键词:java
思路:1、建立数据库mydb,在数据库mydb中建立books表
2、建立pychram与MySQL的连接
3、爬取网站数据输出并存入books表
步骤:
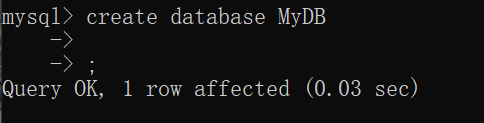
1、建立数据库mydb:
2、建立books表:

3、编写代码:
items.py:
1 import scrapy 2 3 4 class DangdangItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 title = scrapy.Field() 8 author = scrapy.Field() 9 date = scrapy.Field() 10 publisher = scrapy.Field() 11 detail = scrapy.Field() 12 price = scrapy.Field()
settings.py:
1 BOT_NAME = 'dangdang' 2 3 SPIDER_MODULES = ['dangdang.spiders'] 4 NEWSPIDER_MODULE = 'dangdang.spiders' 5 6 ITEM_PIPELINES = { 7 'dangdang.pipelines.DangdangPipeline': 300, 8 } 9 # Crawl responsibly by identifying yourself (and your website) on the user-agent 10 # USER_AGENT = 'dangdang (+http://www.yourdomain.com)' 11 12 # Obey robots.txt rules 13 ROBOTSTXT_OBEY = False 14 COOKIES_ENABLED = False
dd.py:主要实现对网站数据的爬取
1 import scrapy 2 from dangdang.items import DangdangItem 3 from bs4 import BeautifulSoup 4 from bs4 import UnicodeDammit 5 6 7 class DdSpider(scrapy.Spider): 8 name = 'dd' 9 key = 'java' 10 start_urls = ['http://search.dangdang.com/'] 11 source_url = 'http://search.dangdang.com/' 12 header = { 13 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 14 'Chrome/57.0.2987.98 Safari/537.36 LBBROWSER'} 15 16 def start_request(self): 17 url = DdSpider.source_url + "?key=" + DdSpider.key + "&act=input" 18 yield scrapy.Request(url=url, callback=self.parse) 19 20 def parse(self, response): 21 try: 22 dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) 23 data = dammit.unicode_markup 24 selector = scrapy.Selector(text=data) 25 lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") 26 for li in lis: 27 title = li.xpath("./a[position()=1]/@title").extract_first() 28 price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() 29 author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() 30 date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first() 31 publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first() 32 detail = li.xpath("./p[@class='detail']/text()").extract_first() 33 34 item = DangdangItem() 35 item["title"] = title.strip() if title else "" 36 item["author"] = author.strip() if author else "" 37 item["date"] = date.strip()[1:] if date else "" 38 item["publisher"] = publisher.strip() if publisher else "" 39 item["price"] = price.strip() if price else "" 40 item["detail"] = detail.strip() if detail else "" 41 yield item 42 43 # 爬取前十页内容 44 for i in range(2, 11): 45 url = DdSpider.source_url + "?key=" + DdSpider.key + "&act=input&page_index=" + str(i) 46 yield scrapy.Request(url=url, callback=self.parse) 47 48 except Exception as err: 49 print(err)
pipelines.py:实现建立pycharm与MySQL的连接,向books表中插入数据,输出爬取结果等操作
1 import pymysql 2 3 4 class DangdangPipeline(object): 5 def open_spider(self, spider): 6 print("opened") 7 try: 8 # 建立和数据库的连接 9 # 参数1:数据库的ip(localhost为本地ip的意思) 10 # 参数2:数据库端口 11 # 参数3,4:用户及密码 12 # 参数5:数据库名 13 # 参数6:编码格式 14 self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='523523', db="mydb", 15 charset="utf8") 16 # 建立游标 17 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 18 # 如果有books表就删除 19 self.cursor.execute("delete from books") 20 self.opened = True 21 self.count = 0 22 except Exception as err: 23 print(err) 24 self.opened = False 25 26 def close_spider(self, spider): 27 if self.opened: 28 # 用连接提交 29 self.con.commit() 30 # 关闭连接 31 self.con.close() 32 self.opened = False 33 print("closed") 34 print("总共爬取", self.count, "本书籍") 35 36 def process_item(self, item, spider): 37 try: 38 print(item["title"]) 39 print(item["author"]) 40 print(item["publisher"]) 41 print(item["date"]) 42 print(item["price"]) 43 print(item["detail"]) 44 print() 45 if self.opened: 46 self.cursor.execute( 47 "insert into books (bTitle, bAuthor, bPublisher, bDate, bPrice, bDetail) values (%s,%s,%s,%s,%s,%s)", 48 (item["title"], item["author"], item["publisher"], item["date"], item["price"], item["detail"])) 49 self.count += 1 50 except Exception as err: 51 print(err) 52 53 return item
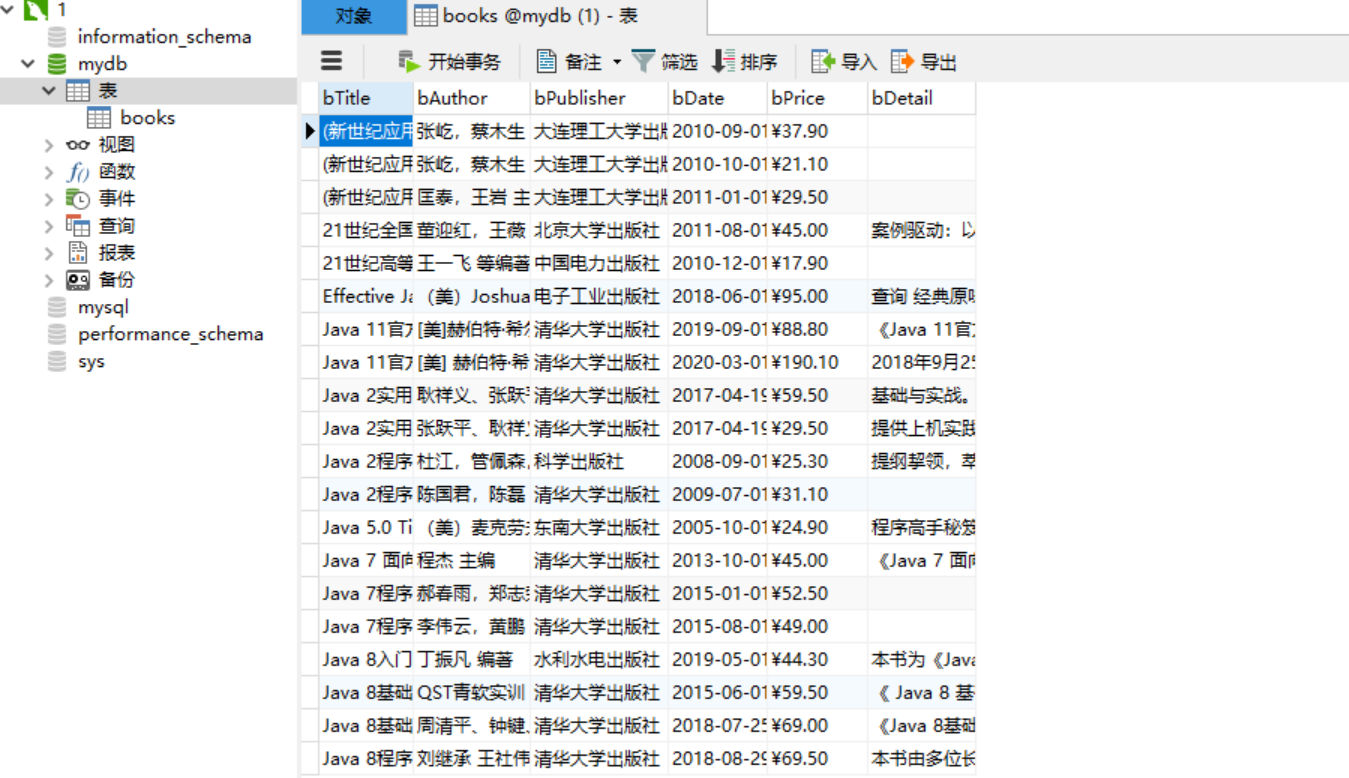
结果:


心得体会:
学习安装了MySQL,第一次安装的时候出了点差错,花了很长时间删除第一次安装的程序再重新安装,以后安装软件要细心了qaq;参照书本学会如何用pycharm与MySQL建立连接,并直接在程序里实现对表的插入操作;在爬取网站数据的时候更加熟悉了对xpath的理解和运用,特别要注意‘//’和‘/’的区别,使用‘//’表示文档下面所有元素的结点,用‘/’表示当前节点的下一级节点元素,挺容易弄错的;然后要注意xpath返回的是一个对象,需要用extract()或extract_first()获取其中的内容;最后就是使用Navicat for MySQL与MySQL建立连接,便于查看表中的内容。
作业二:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
思路:和第一题一样
代码:
items.py:
1 import scrapy 2 3 4 class GupiaoItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 f12 = scrapy.Field() 8 f14 = scrapy.Field() 9 f2 = scrapy.Field() 10 f3 = scrapy.Field() 11 f4 = scrapy.Field() 12 f5 = scrapy.Field() 13 f6 = scrapy.Field() 14 f7 = scrapy.Field()
settings.py:
1 BOT_NAME = 'Gupiao' 2 3 SPIDER_MODULES = ['Gupiao.spiders'] 4 NEWSPIDER_MODULE = 'Gupiao.spiders' 5 6 ROBOTSTXT_OBEY = False # 必须设为False,否则无法打印结果 7 8 ITEM_PIPELINES = { 9 'Gupiao.pipelines.GupiaoPipeline': 300, 10 }
stocks.py:
1 import json 2 import scrapy 3 from Gupiao.items import GupiaoItem 4 5 6 class StocksSpider(scrapy.Spider): 7 name = 'stocks' 8 start_urls = [ 9 'http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240918880626239239_1602070531441&pn=1&pz=20&po=1' 10 '&np=3&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,' 11 'f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602070531442'] 12 13 def parse(self, response): 14 jsons = response.text[41:][:-2] # 将前后用不着的字符排除 15 text_json = json.loads(jsons) 16 for data in text_json['data']['diff']: 17 item = GupiaoItem() 18 item["f12"] = data['f12'] 19 item["f14"] = data['f14'] 20 item["f2"] = data['f2'] 21 item["f3"] = data['f3'] 22 item["f4"] = data['f4'] 23 item["f5"] = data['f5'] 24 item["f6"] = data['f6'] 25 item["f7"] = data['f7'] 26 yield item 27 print("完成") 28 29 # 再爬取后10页的内容 30 for i in range(2, 11): 31 new_url = 'http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240918880626239239_1602070531441&pn=' + str( 32 i) + '&pz=20&po=1&np=3&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,' 33 'm:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,' 34 'f22,f11,f62,f128,f136,f115,f152&_=1602070531442 ' 35 if new_url: 36 yield scrapy.Request(new_url, callback=self.parse)
pipelines.py:
1 import pymysql 2 3 4 class GupiaoPipeline(object): 5 def open_spider(self, spider): 6 print("opened") 7 try: 8 self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='523523', db="mydb", 9 charset="utf8") 10 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 11 self.cursor.execute("delete from gupiao") 12 self.opened = True 13 except Exception as err: 14 print(err) 15 self.opened = False 16 17 def close_spider(self, spider): 18 if self.opened: 19 self.con.commit() 20 self.con.close() 21 self.opened = False 22 print("closed") 23 24 count = 0 25 print("序号 ", "代码 ", "名称 ", "最新价 ", "涨跌幅 ", "跌涨额 ", "成交量 ", "成交额 ", "涨幅 ") 26 27 def process_item(self, item, spider): 28 try: 29 self.count += 1 30 print(str(self.count) + " ", item['f12'] + " ", item['f14'] + " ", str(item['f2']) + " ", 31 str(item['f3']) + "% ", str(item['f4']) + " ", str(item['f5']) + " ", str(item['f6']) + " ", 32 str(item['f7']) + "%") 33 if self.opened: 34 self.cursor.execute( 35 "insert into gupiao (wNo, wCode, wName, wLatest, wRF, wFR, wVolume, wTurnover, wIncrease) values (%s,%s,%s,%s,%s,%s,%s,%s,%s)", 36 (str(self.count), item['f12'], item['f14'], str(item['f2']), str(item['f3'])+"%", str(item['f4']), 37 str(item['f5']), str(item['f6']), str(item['f7'])+"%")) 38 39 except Exception as err: 40 print(err) 41 42 return item
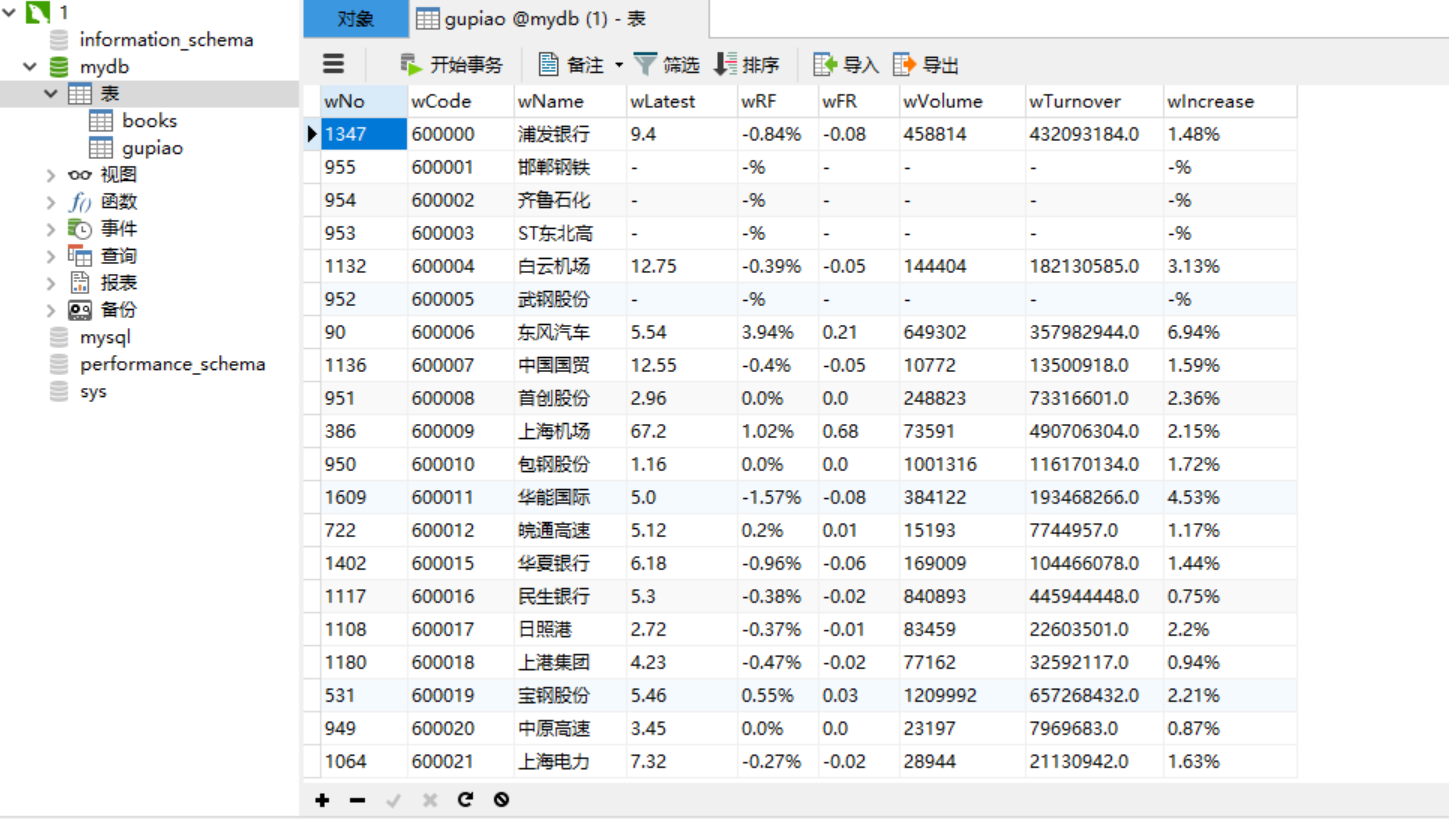
结果:

心得体会:
就是在之前爬取股票数据的pipelines.py中加入建立与MySQL连接、插入数据的代码语句。
作业三:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行:http://fx.cmbchina.com/hq/
思路:和第一题一样
代码:
items.py:
1 import scrapy 2 3 4 class WaihuistocksItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 Id = scrapy.Field() 8 Currency = scrapy.Field() 9 TSP = scrapy.Field() 10 CSP = scrapy.Field() 11 TBP = scrapy.Field() 12 CBP = scrapy.Field() 13 Time = scrapy.Field()
settings.py:
1 BOT_NAME = 'WaihuiStocks' 2 3 SPIDER_MODULES = ['WaihuiStocks.spiders'] 4 NEWSPIDER_MODULE = 'WaihuiStocks.spiders' 5 6 ITEM_PIPELINES = { 7 'WaihuiStocks.pipelines.WaihuistocksPipeline': 300, 8 } 9 # Crawl responsibly by identifying yourself (and your website) on the user-agent 10 #USER_AGENT = 'WaihuiStocks (+http://www.yourdomain.com)' 11 12 # Obey robots.txt rules 13 ROBOTSTXT_OBEY = False 14 COOKIES_ENABLED = False
stocks.py:观察网页的源代码
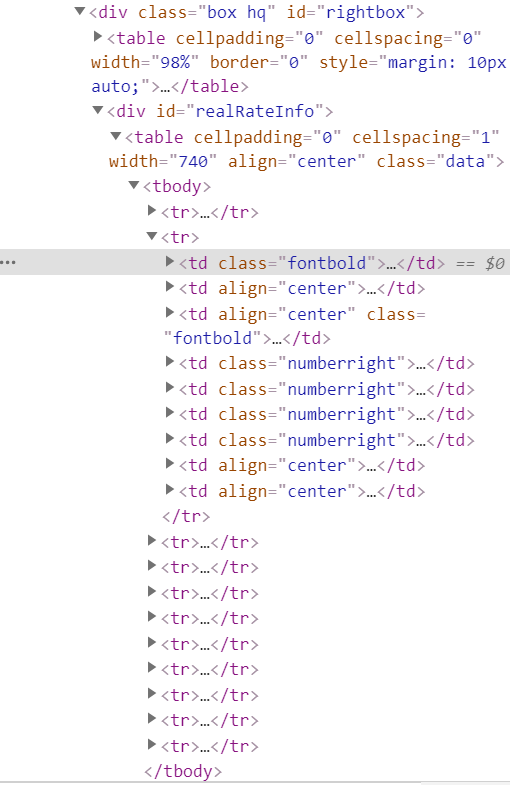
发现每一行的数据都在不同的<tr>...</tr>标签里,因此提取每一行数据,需要定位不同的位置的<tr>标签,这里就可以用到position()来确定所选择的标签。同样,同一行的不同列数据在不同的<td>...</td>标签中,第一列数据可由属性class确定,其余列的数据所在标签的属性有重复,因此也用position()来确定位置。
1 import scrapy 2 from WaihuiStocks.items import WaihuistocksItem 3 from bs4 import BeautifulSoup 4 from bs4 import UnicodeDammit 5 6 7 class StocksSpider(scrapy.Spider): 8 name = 'stocks' 9 start_urls = ['http://fx.cmbchina.com/hq/'] 10 source_url = 'http://fx.cmbchina.com/hq/' 11 header = { 12 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 13 'Chrome/57.0.2987.98 Safari/537.36 LBBROWSER'} 14 15 def start_request(self): 16 url = StocksSpider.source_url 17 yield scrapy.Request(url=url, callback=self.parse) 18 19 def parse(self, response): 20 try: 21 dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) 22 data = dammit.unicode_markup 23 selector = scrapy.Selector(text=data) 24 items = selector.xpath("//div[@class='box hq']/div[@id='realRateInfo']/table[@align='center']") 25 count = 2 26 while count < 12: 27 Currency = items.xpath("//tr[position()="+str(count)+"]/td[@class='fontbold']/text()").extract_first() 28 TSP = items.xpath("//tr[position()="+str(count)+"]/td[position()=4]/text()").extract_first() 29 CSP = items.xpath("//tr[position()="+str(count)+"]/td[position()=5]/text()").extract_first() 30 TBP = items.xpath("//tr[position()="+str(count)+"]/td[position()=6]/text()").extract_first() 31 CBP = items.xpath("//tr[position()="+str(count)+"]/td[position()=7]/text()").extract_first() 32 Time = items.xpath("//tr[position()="+str(count)+"]/td[position()=8]/text()").extract_first() 33 item = WaihuistocksItem() 34 item["Currency"] = Currency.strip() # if Currency else "" 35 item["TSP"] = TSP.strip() if TSP else "" 36 item["CSP"] = CSP.strip() if CSP else "" 37 item["TBP"] = TBP.strip() if TBP else "" 38 item["CBP"] = CBP.strip() if CBP else "" 39 item["Time"] = Time.strip() if Time else "" 40 count += 1 41 yield item 42 43 except Exception as err: 44 print(err)
pipelines.py:
1 import pymysql 2 3 4 class WaihuistocksPipeline(object): 5 6 def open_spider(self, spider): 7 print("opened") 8 try: 9 self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='523523', db="mydb", 10 charset="utf8") 11 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 12 self.cursor.execute("delete from waihui") 13 self.opened = True 14 except Exception as err: 15 print(err) 16 self.opened = False 17 18 def close_spider(self, spider): 19 if self.opened: 20 self.con.commit() 21 self.con.close() 22 self.opened = False 23 print("closed") 24 25 count = 0 26 print("序号 ", "交易币 ", "现汇卖出价 ", "现钞卖出价 ", "现汇买入价 ", "现钞买入价 ", "时间 ") 27 28 def process_item(self, item, spider): 29 try: 30 self.count += 1 31 print(str(self.count) + " ", item["Currency"] + " ", str(item["TSP"]) + " ", str(item["CSP"]) + " ", 32 str(item["TBP"]) + " ", str(item["CBP"]) + " ", item["Time"]) 33 34 if self.opened: 35 self.cursor.execute( 36 "insert into waihui (wId, wCurrency, wTSP, wCSP, wTBP, wCBP, wTime) values (%s,%s,%s,%s,%s,%s,%s)", 37 (str(self.count), item["Currency"], str(item["TSP"]), str(item["CSP"]), str(item["TBP"]), str(item["CBP"]), 38 str(item["Time"]))) 39 40 except Exception as err: 41 print(err) 42 43 return item
结果:
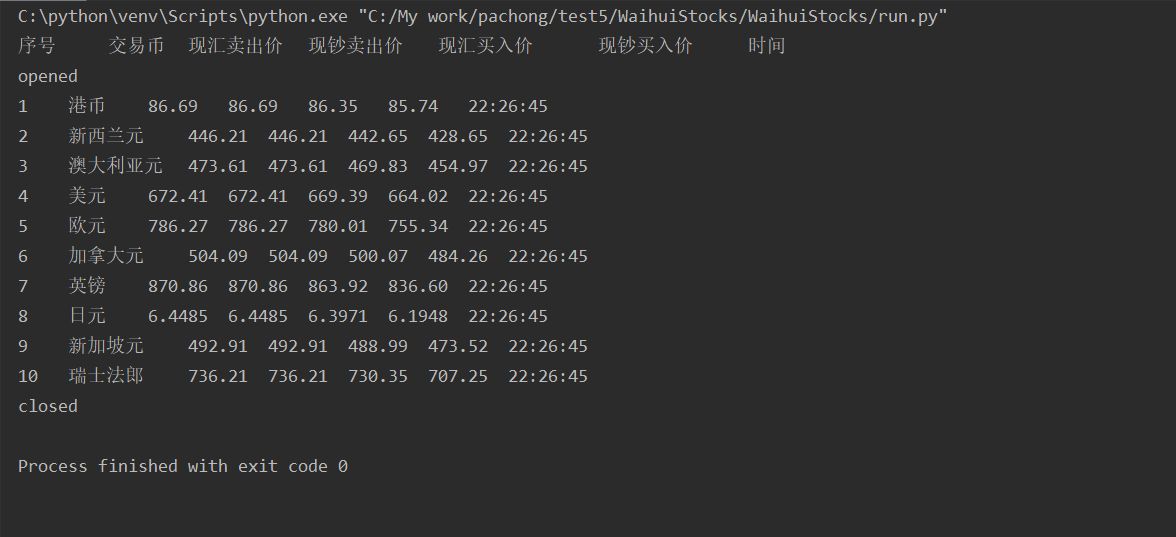
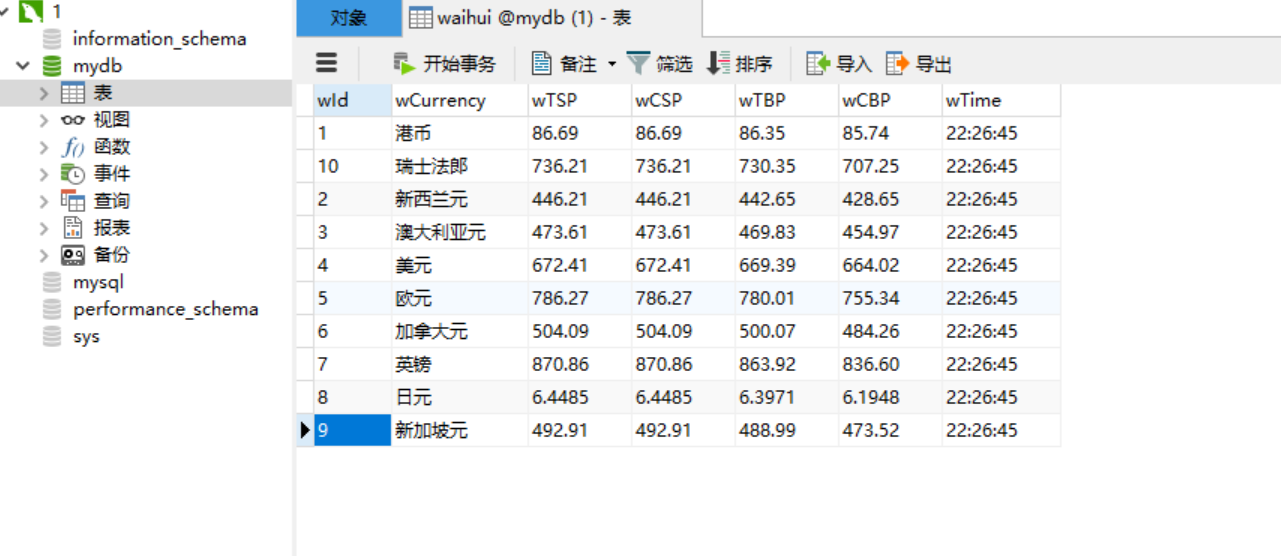
心得:
注意观察网页数据的存储方式,灵活使用xpath()爬取数据。