=================================版权声明=================================
版权声明:原创文章 禁止转载
请通过右侧公告中的“联系邮箱(wlsandwho@foxmail.com)”联系我
勿用于学术性引用。
勿用于商业出版、商业印刷、商业引用以及其他商业用途。
本文不定期修正完善。
本文链接:http://www.cnblogs.com/wlsandwho/p/7512119.html
耻辱墙:http://www.cnblogs.com/wlsandwho/p/4206472.html
=======================================================================
很显然我没有足够的巩俐,啊功力去讲解机器学习的大道理,但是我愿意把我的读书笔记分享出来。
当然,我保留版权。
=======================================================================
关于kNN算法的伪代码描述,我这里得写一下,因为《机器学习实践》这本书里写的不是很清楚。(当然我的用词更通俗,毕竟不能照抄原文啊:)
1 计算目标点与数据集中每个点的距离。
这个求距离的算法应当是根据实际情况具体问题具体分析采取的。书中使用的是欧几里德几何体系里的两点之间的距离。对,就是初中学的那个。
2 对距离的结果按照从小到大的顺序排序。
这里要记录哪个结果是由哪个点产生的。总不能排序之后结果排序了,但是对应点找不到了吧?
3 从结果中取前k个点。
kNN算法之所以叫kNN算法,是因为它选取了前k个点。
4 记录这k个点对应类别的频率。
比方说在这k个点中,a类出现了5次,b类出现了2次,c类出现了7次
5 取出现频率最高的类别作为结果。
通俗地讲,就是发现跟a有5成像,跟b有2成像,跟c有7成像。当然是选最像的啦。
=======================================================================
话是这么说,看起来也很简单。但是用指定的编程语言实现,就得看对于该语言的熟练程度了。
比方说,我用C++写的话,比较麻烦的地方是矩阵运算,其他就很简单了。
但是用Python的话,我需要熟悉相关的类库和代码。
=======================================================================
对于我这种只看过《Python编程:从入门到实践》的人来说,看《机器学习与实践》的代码还是要查资料的。
要理解下面的内容:
1 tile(x,(m,n))
通俗的说就是把指定的块x,按行复制m次,按列复制n次。m和n是可以取0的,但这没有意义,因为把没有复制了0次,还是没有啊:)
为什么我说的是块x呢?因为这个x可以是一个数,也可以是一个矩阵。对,大学线性代数课程里对矩阵运算时,就是可以把某一部分看成一个子矩阵的。这个同理。
2 x.sum(axis=?)
手册上说,是垂直求和还是水平求和。
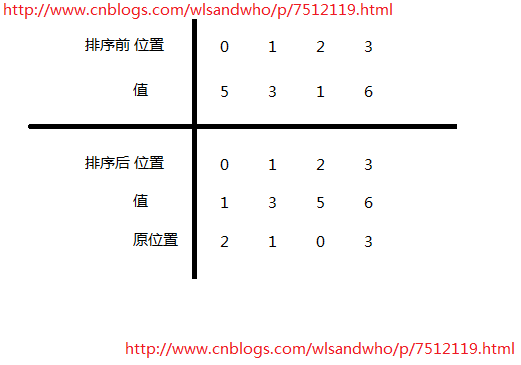
3 a.argsort()
这个得画个图。一图胜千言。输入5316,输出2103。
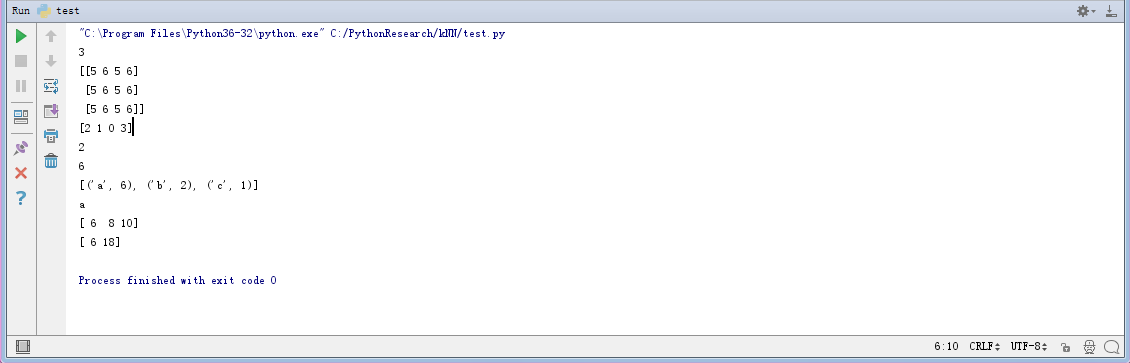
贴出示例小代码有助于理解。毕竟我们用事实说话。
1 from numpy import * 2 import operator 3 4 5 r=array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) 6 rows=r.shape[0] 7 print(rows) 8 9 x=[5,6] 10 xxx=tile(x,(3,2)) 11 print(xxx) 12 13 a=array([5,3,1,6]) 14 #1,3, 5, 6 15 #2,1, 0, 3 16 b=a.argsort() 17 print(b) 18 print(b[0]) 19 20 c={} 21 c['c']=1 22 c["b"]=2 23 c["a"]=1 24 c["a"]=c.get('a')+5 25 print(c["a"]) 26 27 d=sorted(c.items(),key=operator.itemgetter(1),reverse=True) 28 print(d) 29 print(d[0][0]) 30 31 mm=array([[1,2,3],[5,6,7]]) 32 print(mm.sum(axis=0)) 33 print(mm.sum(axis=1))
=======================================================================
好了,可以贴我的kNN代码了。Python的风格不习惯,随手写了下。
1 from numpy import * 2 import operator 3 4 5 def create_data_set(): 6 group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) 7 labels=["A","A","B","B"] 8 9 return group,labels 10 11 def classify_kNN(dest,sample,labels,k): 12 rows=sample.shape[0] 13 dests=tile(dest,(rows,1)) 14 res=(((dests-sample)**2).sum(axis=1))**0.5 15 resrank=res.argsort() 16 17 clfy={} 18 19 for i in range(k): 20 index=resrank[i] 21 sometype=labels[index] 22 clfy[sometype]=clfy.get(sometype,0)+1 23 24 sclfy=sorted(clfy.items(),key=operator.itemgetter(1),reverse=True) 25 26 return sclfy[0][0]
这是算法。
下面是调用。
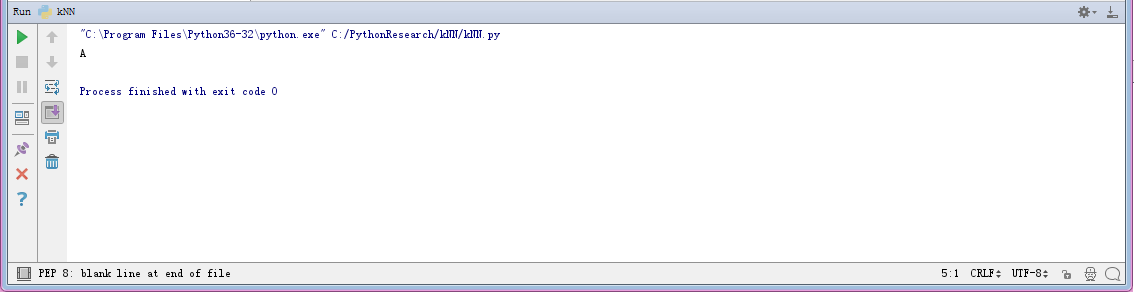
1 g,l=create_data_set() 2 r=classify_kNN([0.5,0.6],g,l,2) 3 print(r)
这个是结果
=======================================================================
那么问题来了:
新分类值是否可以加入样本扩充原来的数据?