新建scrapy
scrapy startproject ArticleSpider
创建spider
cd ArticleSpider
scrapy genspider jobbole http://blog.jobbole.com
scrapy genspider -t crawl lagou www.lagou.com #指定生成的模板-t crawl scrapy genspider --list 查看生成spider可以使用的模板
pip install pypiwin32
在pycharm中open该项目
在该目录下添加main.py 用于执行爬虫代码
setting.py中修改内容 ROBOTSTXT_OBEY = False
from scrapy.cmdline import execute import sys import os #得到项目路径 sys.path.append(os.path.dirname(os.path.abspath(__file__))) #传递执行命令 execute(["scrapy","crawl","jobbole"])
在cmd下可以执行 scrapy crawl jobbole 或者使用pycharm执行main.py文件 便可以正常使用pycharm调试爬虫程序
在cmd下进行页面的调试比pycharm的debug更方便 scrapy shell http://blog.jobbole.com/112801/
XPATH语法



cmd: title = response.xpath('//*[@id="post-112801"]/div[1]/h1/text()') 加粗部分代码是使用chrome的调试工具里面复制的xpath 直接获取里边的内容
cmd: title.extract() 返回的是一个python list

title.extract()[0].strip() 将多余的符号删除
title.extract()[0].strip().replace("X","Y") 将不需要的字符替换掉
CSS选择器
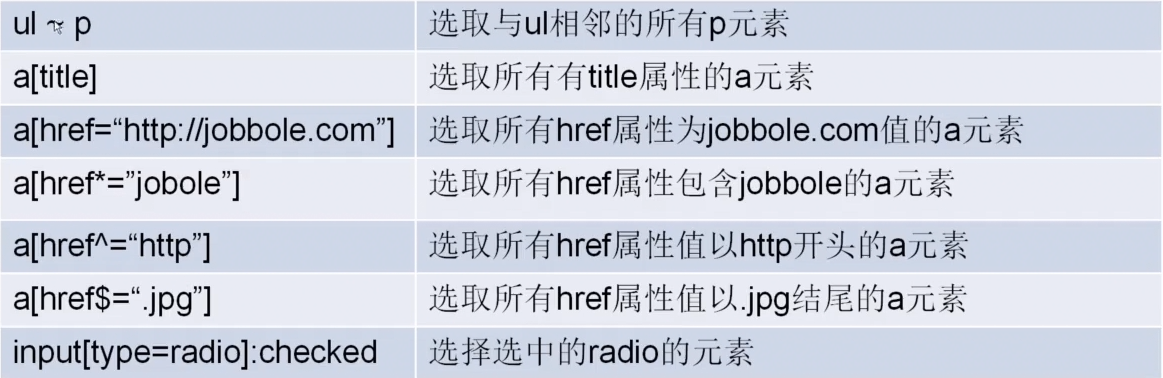

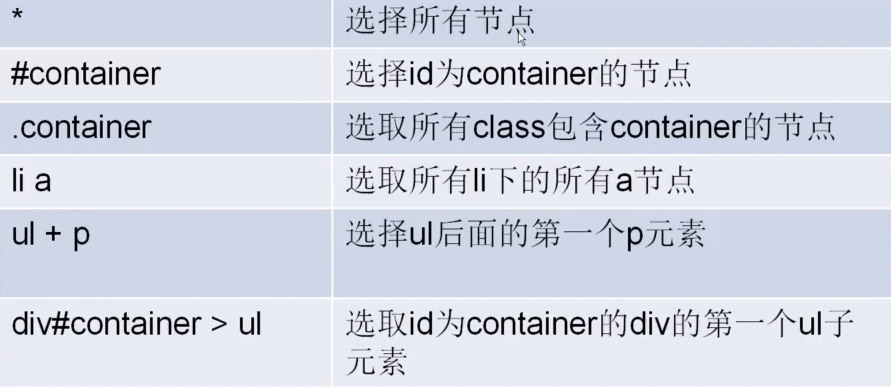
response.css(".entry-header h1::text").extract()
爬虫就是将非结构化的html解析成自定义结构的数据
最简单的就是保存到sql
1.定义items.py
name = scrapy.Field()#可以定义一个函数对Field里面的值进行转换lambda X:X + “author” 就可以将取到的值进行添加author操作
2.在setting文件中使得pipelines生效
ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, }
3.这样spider里面yield的item就可以传递到pipelines
name = request.css(XXXXXXXXXXXX).extract_first("") article = XXXitem() article["name"] = scrapy.Field()
yield article#yield可以将此处生成的article对象传到pipelines里面
4.配置自动下载图片 setting
ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'scrapy.pipelines.images.ImagesPipeline': 1, } IMAGES_URLS_FIELD = "front_image_url" project_dir = os.path.abspath(os.path.dirname(__file__)) IMAGES_STORE = os.path.join(project_dir, "images")#到此 设置只能讲图片保存到指定路径但是 如果需要拿出指定文章的指定图片还是不可以
提取图片路径(定制自制pipeline)
class ArticleImagePipeline(ImagesPipeline): #重载该函数获取保存image的path def item_completed(self, results, item, info): for ok, result in results: image_file_path = result["path"] item["front_image_path"] = image_file_path return item
#配置pipeline执行顺序 'ArticleSpider.pipelines.ArticleImagePipeline': 1, 'ArticleSpider.pipelines.MysqlTwistedPipeline': 300,#进行保存的pipeline 设置一个大的值 执行顺序由小到大
将内容保存到json
class JsonWithEncodingPipeline(object): def __init__(self): self.file = codecs.open("article.json", "w", encoding='utf-8') def process_item(self, item, spider): lines = json.dumps(dict(item), ensure_ascii=False) + ' ' self.file.write(lines) return item def spider_closed(self, spider): self.file.close()
将内容保存到mysql中要在虚拟环境中添加mysqlclient pip install mysqlclient(window) centos下 sudo yum install python-devel mysql-devel ubuntu下 sudo apt-get install libmysqlclient-dev
#python 插入mysql方法 class MysqlClientPipeline(object): def __init__(self): self.conn = MySQLdb.connect('127.0.0.1', 'root', '', 'jobbole', charset="utf8", use_unicode=True) self.cursor = self.conn.cursor() def process_item(self, item, spider): insert_sql = """insert into jobbole_article(title, url, create_date, fav_nums) VALUES(%s, %s, %s, %s)""" self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"])) self.conn.commit()
scrapy ItemLoader
item_loader = ItemLoader(item=XXXItem(), response=response) #三种add方法替换原先的css选择器 xpath 以及赋值 item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_xpath("url", response.url)
XXX_item = item_loader.load_item()#直接使用ItemLoader返回的XXXItem里边的属性值都是list(不确定在html中提取的值为一个)要改变list成为值就需要 自定义ItemLoader如下
from scrapy.loader.processors import TakeFirst from scrapy.loader import ItemLoader class XXXItemLoader(ItemLoader): #自定义itemloader 将输出改变 由原来的list 改变成第一个元素 default_output_processor = TakeFirst() #在spider里边调用 item_loader = XXXItemLoader(item=JobBoleArticleItem(), response=response) #这样得到的item里面的值便不是list
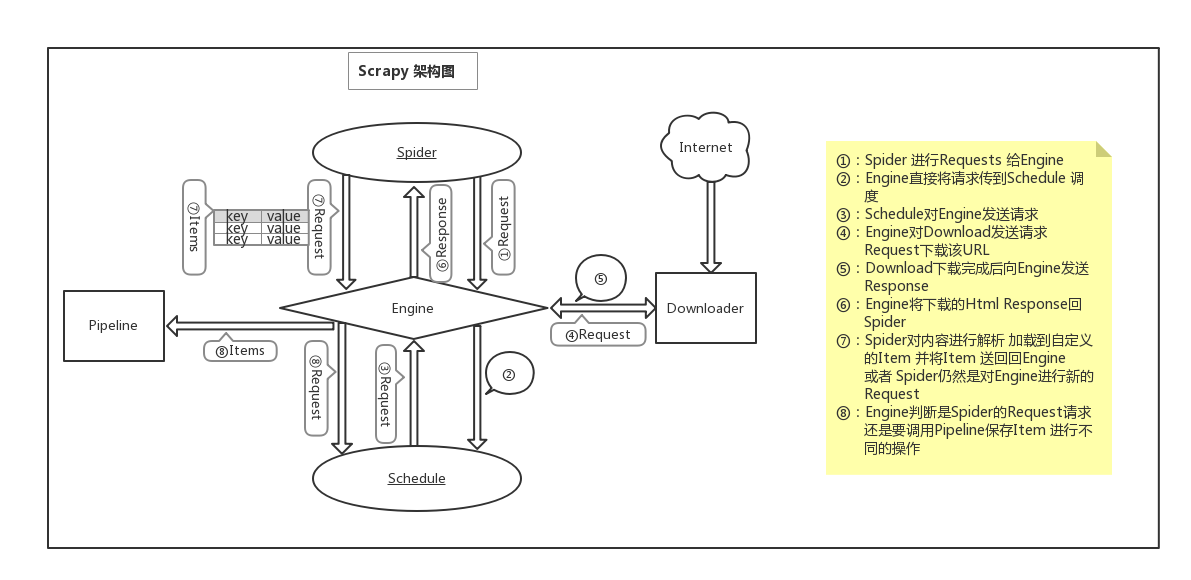
Scrapy 架构图 来自官方文档 为理解流程重新绘制