继续来了解dplyr中的其他有用函数
1、sample()
目的是可以从一个数据框中,随机抽取一些行,然后组成新的数据框。
sample_n(tbl, size, replace = FALSE, weight = NULL, .env = parent.frame())
sample_frac(tbl, size = 1, replace = FALSE, weight = NULL, .env = parent.frame())
从参数来看,sample输入数据是tbl格式,size表示抽取的个数,replace指的是能否重复抽取,weight指的是抽取比重。
另外,sample_frac是按照比例进行抽样。
下面来看些具体的例子
sample_n(mtcars, 10)
sample_n(mtcars, 20, replace = TRUE)
sample_n(group_by(mtcars,cyl), 3)
对数据分组后,再进行抽样是按照每组个抽取size个数的数据进行抽样。
sample_frac(mtcars, 0.1)

表示从数据从随机抽取1%的数据。
2、对两个数据集进行操作的函数
intersect(x, y, ...)
union(x, y, ...)
union_all(x, y, ...)
setdiff(x, y, ...)
setequal(x, y, ...)
intersect 用于求两个函数的交集部分数据,union求并集部分数据,union_all求两个数据集的合集,
setdiff求两个数据集差异部分,setequal判别两个数据集是否相同
下面来看些具体的例子
mtcars$model <- rownames(mtcars) first <- mtcars[1:20, ] second <- mtcars[10:32, ]
first 数据集打印结果

second数据集打印结果

intersect(first, second)

union(first, second)

setdiff(first, second)

setdiff(second, first)

这里值得注意的是,setdiff(first, second) 和 setdiff(second, first)的结果是不一样的。
setequal(mtcars, mtcars[32:1, ])
TRUE
3、slice()
按照具体数据所在行进行抽取数据,即定向抽取数据。
slice(.data, ...)
下面来看些具体的例子
slice(mtcars, 1L)

抽取第一行数据
slice(mtcars, n())

抽取最后一行数据
slice(mtcars, 25:n())
抽取第25行到最后一行数据
slice(group_by(mtcars, cyl), 1:2)

按照cyl分组后,每组抽取前两行数据
当然以上各组数据的抽取也可以用filter函数进行实现
filter(mtcars, row_number() == 1L)
filter(mtcars, row_number() == n())
filter(mtcars, between(row_number(), 5, n()))
3、tally()
用于统计数据行数
tally(x, wt, sort = FALSE)
count(x, ..., wt = NULL, sort = FALSE)
直接根据实例来观察这个几个函数的区别
tally(mtcars)

直接返回mtcars总行数。
count(mtcars)

也是返回mtcars总行数
tally(mtcars,cyl)

返回cyl列所有数据求和后的结果
count(mtcars,cyl)

返回每个cyl并统计每个值得个数。
tally(group_by(mtcars,cyl))

与上面count(mtcars,cyl)的效果一致。
tally(group_by(mtcars,cyl),mpg)

根据cyl分组后,对mpg进行求和
count(group_by(mtcars,cyl),mpg)
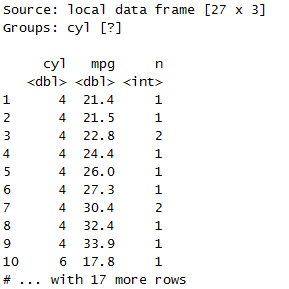
进行多次分组统计。