函数递归
在函数内调用当前函数本身的函数就是递归函数,每调用一次自身,相当于复制一份该函数,只不过参数有变化,参数的变化,就是重要的结束条件
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出
递归分为两个阶段
1.回溯:就是一次次重复的过程,这个重复的过程必须建立在每一次重复问题的复杂度都应该下降
直到有一个最终的结束条件
2.递推:一次次往回推导的过程
算法之二分法
二分法就是解决运算高效率的方法,适用范围为一个已经排好序的数组(升序、降序
每次只找中间位置,这样做能够使得每次查找的数据数量减少一半)
target_num = 666 def get_num(l,target_num): if not l: print('你给的工资 这个任务怕是没法做') return # 获取列表中间的索引 print(l) middle_index = len(l) // 2 # 判断target_num跟middle_index对应的数字的大小 if target_num > l[middle_index]: # 切取列表右半部分 num_right = l[middle_index + 1:] # 再递归调用get_num函数 get_num(num_right,target_num) elif target_num < l[middle_index]: # 切取列表左半部分 num_left = l[0:middle_index] # 再递归调用get_num函数 get_num(num_left, target_num) else: print('find it',target_num) get_num(l,target_num)
三元表达式
def my_max(x,y): if x > y: return x else: return y """ 当x大的时候返回x当y大的时候返回y 当某个条件成立做一件事,不成立做另外一件事 """ x = 99999 y = 9898898 res = x if x > y else y # 如果if后面的条件成立返回if前面的值 否则返回else后面的值 print(res)
三元表达式固定表达式
值1 if 条件 else 值2
条件成立 值1
条件不成立 值2
列表生成式
列表生成式即生成列表的生成式,写法简单而优雅,可以将多行代码融合成一行。主要的作用是将其他对象转换成列表或对原来的列表进行过滤。
列表生成式的代码效率是高于多行循环结构的,原因是将原本多行代码融合一行,解释加快。
# 列表转换列表 ls = [1,2,4,6] ls1 = [x**2 for x in ls] print(ls1) 结果:[1,4,16,36] # 也可以这样 list(x**2 for x in range(10)) # 对列表过滤,返回true的才会保留到列表 ls = [1,2,4,6] ls1 = [x**2 for x in ls if x > 3] print(ls1) 结果:[16, 36] # 多条件过滤 ls = [1,2,4,6] ls1 = [x**2 if x > 2 else x**3 for x in ls] print(ls1) 结果:[1, 8, 16, 36] # 多重循环 ls = [1,2,4,6] ls1 = [x**y if x > 2 else x**3 for x in ls for y in ls] print(ls1) 结果:[1, 1, 1, 1, 8, 8, 8, 8, 4, 16, 256, 4096, 6, 36, 1296, 46656]
字典生成式
字典生成式在一些需要列表或元组转化成字典的场合可以写出很优雅的代码。
# dict()可以接受类似列表生成式的写法,前提是ls至少是二维可迭代对象,否则报错 ls = [('name1','xiao'),('name2','wang')] dict_ls = dict(x for x in ls) print(dict_ls) 结果:{'name1': 'xiao', 'name2': 'wang'} # 也可以针对zip使用 d = dict(zip([1,2],[3,4,])) print(d) # 结果 {1: 3, 2: 4} # 直接和列表生成式相似的写法 d = {x:y for x,y in enumerate(range(10))}
集合生成式
按照列表生成式类似的写法我们可以写集合生成式。
print(set(i for i in range(5))) print({i for i in range(5)}) print(frozenset(i for i in range(5))) # 结果 {0, 1, 2, 3, 4} {0, 1, 2, 3, 4} frozenset({0, 1, 2, 3, 4})
元组生成式
由于()这个类似列表生成式的形式被生成器占用了,所有元组生成式使用tuple()来进行。
ls = [('name1',['1','2']),('name2','wang')] dict_ls = tuple(x for x in ls) print(dict_ls) 结果:(('name1', ['1', '2']), ('name2', 'wang'))
匿名函数
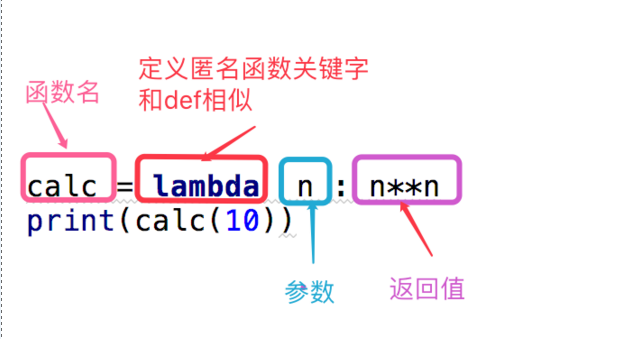
关键字lambda表示匿名函数,冒号前面的n表示函数参数,可以有多个参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
有些函数在代码中只用一次,而且函数体比较简单,使用匿名函数可以减少代码量,看起来比较"优雅“
#这段代码 def calc(x,y): return x**y #换成匿名函数 calc = lambda x,y:x**y print(calc(2,5)) def calc(x,y): if x > y: return x*y else: return x / y #三元运算换成匿名函数 calc = lambda x,y:x * y if x > y else x / y print(calc(2,5))
常用的内置函数
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
l = [1,2,3,4,5,6] # print(list('hello')) print(list(map(lambda x:x+5,l))) # 基于for循环
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
# l1 = [1,2,] # l2 = ['jason','egon','tank'] # l3 = ['a','b','c'] # print(list(zip(l1,l2,l3))) # l = [1,2,3,4,5,6] # print(list(filter(lambda x:x != 3,l))) # 基于for循环 # l = ['jason','egon','nick','tank'] # print(sorted(l,reverse=True))
sorted() 函数对所有可迭代的对象进行排序操作。
sorted(iterable[, cmp[, key[, reverse]]])
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
reduce() 函数会对参数序列中元素进行累积。
reduce(function, iterable[, initializer])
function -- 函数,有两个参数
iterable -- 可迭代对象
initializer -- 可选,初始参数
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
from functools import reduce l = [1,2,3,4,5,6] print(reduce(lambda x,y:x+y,l,19))