blog:www.wjyyy.top
AC自动机是一种毒瘤的方便的多模式串匹配算法。基于字典树,用到了类似KMP的思维。
AC自动机与KMP不同的是,AC自动机可以同时匹配多个模式串,而复杂度不会达到太高。如果用KMP多次匹配字符串,复杂度就是(O(k(n+m)))。
我们知道,如果让一个字符串头对头或者完全匹配其他字符串,用字典树来匹配是最为方便的。但是如果匹配过程中发现当前节点没有目标儿子,就发生了失配。在KMP字符串匹配中,失配可以跳到给当前位置预处理出的nxt,继续匹配。
而AC自动机在字典树上,我们如何找出每个节点失配位置呢?我们知道,像KMP一样,失配位置是唯一确定的。而在字典树上,一条路径唯一对应了一个子串,因此也是唯一确定的。
KMP中的nxt数组是由变量j承接了前一个位置的nxt,我们考虑在AC自动机中也让失配指针从父节点转移过来。那么如此一来,当前节点(设为'c')的失配指针就会从当前父节点的失配指针一直沿失配指针递归,找到第一个有以'c'字符为儿子的节点,把当前节点的失配指针连接到这个节点的'c'儿子上。如此做下去,会发现有了失配指针的树变成了一个图。但是如果上面的回溯过程找到根了还没有找到怎么办?
正常情况下,字典树的根是不带任何字符的,也就是说它是一个空节点,也是重新匹配的开始。如果我们一开始匹配就出现了失误,也就是根节点都没有这个儿子,我们当然要留在自己位置上继续做,因此根节点的失配指针指向自己(同时防止越界)。同理,根节点的儿子们失配指针指向根节点,因为在这里失配了,接下来只有两种情况:一是根节点也没有这个儿子,于是回归到根节点的一般情况;二是根节点有这个儿子,根节点有这个儿子我们就通过当前节点的失配指针先走到根节点,再走到这个儿子去。
于是,我们的Trie树变成了Trie图。
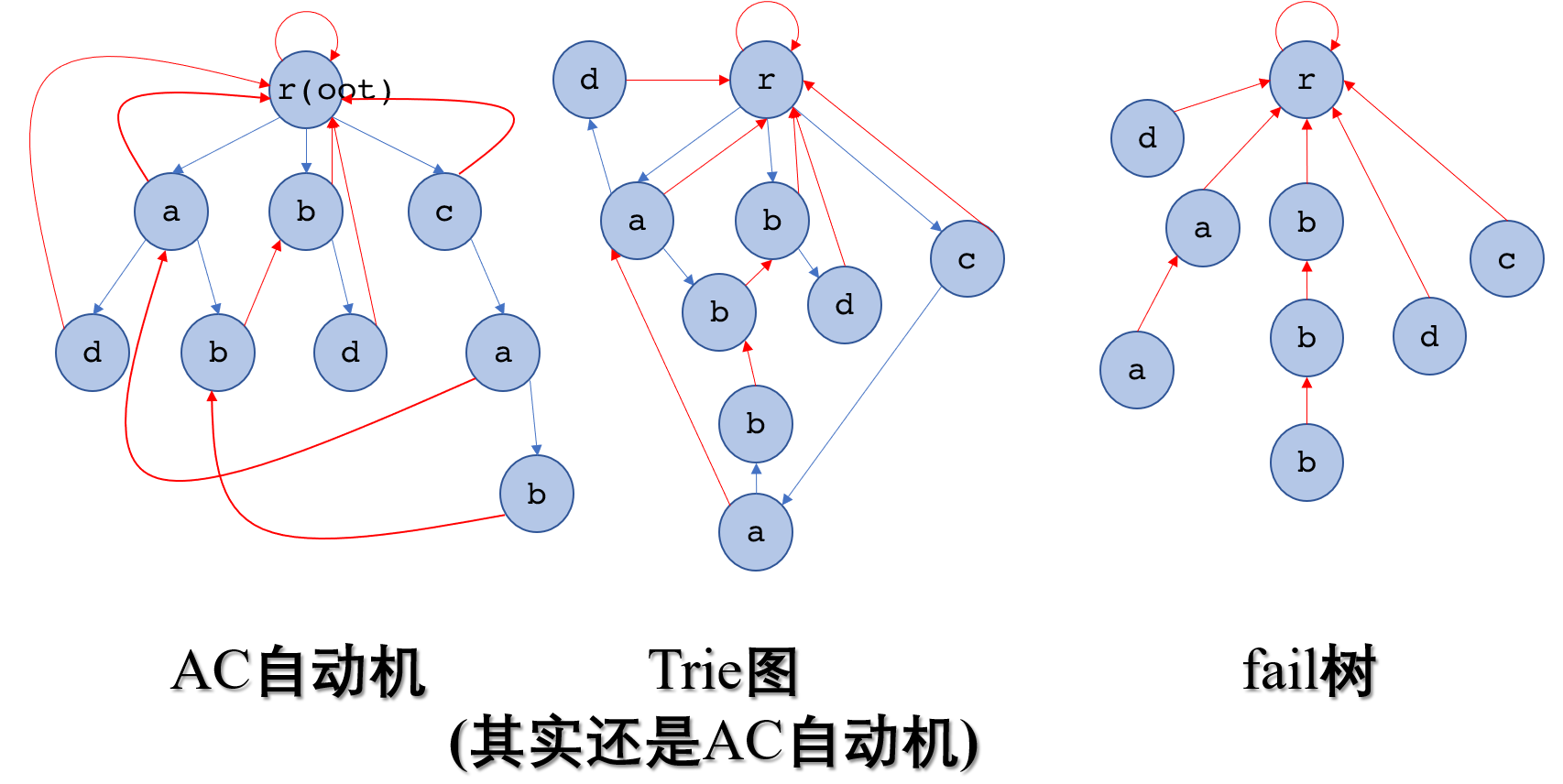
可以根据上面的前两幅图更清楚的了解AC自动机,其中红色边是fail边。我们可以发现一个有趣的事情,fail指针可以构成一棵有向树,注意到每条单独的链都没有分支,而且一条链上的字母总是一致的,因此可能在以后的题目或者优化中出现。(就像KMP的nxt一样)
实际上在构建AC自动机时,我们的失配指针并不这样建。为了减小常数(也许是这个原因),我们认为当前节点如果没有儿子'c',就把当前节点代表'c'儿子的指针连向当前节点失配指针的'c'儿子。因为一个点的失配指针指向的节点总是比这个点浅,所以我们用BFS来做,深度较浅的点总比深度深的点先被访问,也因此,当前节点的失配指针的'c'儿子一定有位置,即使不是它真正的儿子,也一定是它通过失配指针索引得到的。在最坏的情况下,如果失配指针回溯的过程中怎么也找不到这样的儿子,自然而然当前节点的'c'儿子就连向根了。
与字典树类似,AC自动机成功匹配就是找到了一个单词的结尾,我们在构建字典树时就应该把每个模式串的结尾做上标记。但是如果两个模式串有包含关系怎么办?有两种方法可以完成,一是访问到每个节点时暴力跳fail指针,直到递归到根,对答案的贡献就是这条路径的标记数;二是构建fail树,跳就是沿着fail树在跳,只需要预处理出fail树上每个节点到根路径上标记的数目(前缀和),就可以在当前节点记录答案。看上去第二种方法复杂度更优,但是它有局限性。也就是当确切地统计每个模式串出现的次数时,这种直接用fail树统计出现次数和的方法不能适用。
Code of luoguP3796:
这个题要注意重复的模式串统计问题
#include<cstdio>
#include<cstring>
#include<vector>
using std::vector;
vector<int> same[155];//与某一个模式串相同的模式串编号
struct node
{
int End,num;//num表示相同模式串个数,End表示是否为结束位置
node *ch[26];
node *fail;
node()
{
memset(ch,0,sizeof(ch));
fail=NULL;
End=0;
num=0;
}
void build(char *c,int i)//构建字典树
{
if(*c=='�')
{
End=1;
if(!num)
num=i;
same[num].push_back(i);//如果发现这里已经有单词结束了,那么一定是重复的,直接向原来的后面加编号就好了
return;
}
if(!ch[*c-'a'])
ch[*c-'a']=new node();
ch[*c-'a']->build(c+1,i);
}
}*root=new node();
char t[200][200];
node *q[1000011];//用队列完成BFS
int l=0,r=0;
void Fail()//构建fail指针
{
root->fail=root;//没有这句话貌似也可以,为了保险起见,防止越界
for(int i=0;i<26;++i)//根节点的儿子失配指针都指向自己
if(!root->ch[i])//没有这个儿子就指向失配指针的这个儿子,而失配指针是自己,为了不紊乱和方便,这个儿子就指向自己
root->ch[i]=root;
else
{
root->ch[i]->fail=root;//设置失配指针
q[++r]=root->ch[i];
}
while(l<r)
{
node *p=q[++l];
for(int i=0;i<26;++i)
if(p->ch[i])
{
p->ch[i]->fail=p->fail->ch[i];//有这个儿子就设置失配指针到自己的失配指针,自己的失配指针指向的地方一定已经完成工作了
q[++r]=p->ch[i];
}
else
p->ch[i]=p->fail->ch[i];
}
return;
}
char s[1000010];
int cnt[155];
void match()
{
int ans=0;
scanf("%s",s);
node *now=root;
for(int i=0;s[i]!='�';++i)//开始匹配
{
now=now->ch[s[i]-'a'];
cnt[now->num]+=now->End;
node *p=now;
while(p!=root)//暴力跳fail
{
p=p->fail;
cnt[p->num]+=p->End;
}
}
}
int main()
{
int n;
scanf("%d",&n);
while(n)
{
root=new node();
memset(cnt,0,sizeof(cnt));
for(int i=1;i<=n;++i)
{
scanf("%s",t[i]);
root->build(t[i],i);
}
Fail();
match();
int mx=0;
for(int i=1;i<=n;++i)
{
for(vector<int>::iterator it=same[i].begin();it!=same[i].end();++it)//处理相同模式串
cnt[*it]=cnt[i];
if(mx<cnt[i])
{
cnt[0]=1;
mx=cnt[i];
}
else if(mx==cnt[i])
++cnt[0];
}
printf("%d
",mx);
for(int i=1;i<=n;++i)
if(cnt[i]==mx)
printf("%s
",t[i]);
scanf("%d",&n);
}
return 0;
}