写在前面:之前想分类图像的时候有看过k-means算法,当时一知半解的去使用,不懂原理不懂使用规则。。。显然最后失败了,然后看了《机器学习》这本书对k-means算法有了理论的认识,现在通过贾志刚老师的视频有了实际应用的理解。
k-means算法原理
注:还是和之前一样,核心都是别人的,我只是知识的搬运工并且加上了自己的理解。弄完之后发现理论部分都是别人的~~没办法这算法太简单了。。。
k-means含义:无监督的聚类算法。
无监督:就是不需要人干预,拿来一大批东西直接放进算法就可以进行分类。SVM和神经网络都是需要提前训练好然后再进行分类这样就是监督学习。而k-means和K近邻都是无监督学习。
聚类:通过一个中心聚在一起的分类,比如给你一批数据让你分成三类,那就是三个中心,那这三个中心代表的意思就是三个类。
k-means步骤:
这个算法其实很简单,如下图所示: (这里直接复制别人步骤,说的很明白了)

从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
- 随机在图中取K(这里K=2)个种子点。
- 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
- 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
- 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
这个算法很简单,但是有些细节我要提一下,求距离的公式我不说了,大家有初中毕业水平的人都应该知道怎么算的。我重点想说一下“求点群中心的算法”。
求点群中心的算法
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance公式——也就是第一个公式λ=2的情况

3)CityBlock Distance公式——也就是第一个公式λ=1的情况
![]()
k-means的缺点:
① 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是 K-means 算法的一个不足。
② 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
③ 从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。
opencv+K-means
没什么好写的,因为这个k-means比较简单,主要说的就是函数参数的应用而已:
void RNG::fill(InputOutputArray mat, int distType, InputArray a, InputArray b, bool saturateRange=false )
这个函数是对矩阵mat填充随机数,随机数的产生方式有参数2来决定,如果为参数2的类型为RNG::UNIFORM,则表示产生均一分布的随机数,如果为RNG::NORMAL则表示产生高斯分布的随机数。对应的参数3和参数4为上面两种随机数产生模型的参数。比如说如果随机数产生模型为均匀分布,则参数a表示均匀分布的下限,参数b表示上限。如果随机数产生模型为高斯模型,则参数a表示均值,参数b表示方程。参数5只有当随机数产生方式为均匀分布时才有效,表示的是是否产生的数据要布满整个范围(没用过,所以也没仔细去研究)。另外,需要注意的是用来保存随机数的矩阵mat可以是多维的,也可以是多通道的,目前最多只能支持4个通道。
void randShuffle(InputOutputArray dst, double iterFactor=1., RNG* rng=0 )
该函数表示随机打乱1D数组dst里面的数据,随机打乱的方式由随机数发生器rng决定。iterFactor为随机打乱数据对数的因子,总共打乱的数据对数为:dst.rows*dst.cols*iterFactor,因此如果为0,表示没有打乱数据。
Class TermCriteria
类TermCriteria 一般表示迭代终止的条件,如果为CV_TERMCRIT_ITER,则用最大迭代次数作为终止条件,如果为CV_TERMCRIT_EPS 则用精度作为迭代条件,如果为CV_TERMCRIT_ITER+CV_TERMCRIT_EPS则用最大迭代次数或者精度作为迭代条件,看哪个条件先满足。
double kmeans(InputArray data, int K, InputOutputArray bestLabels, TermCriteria criteria, int attempts, int flags, OutputArray centers=noArray() )
该函数为kmeans聚类算法实现函数。参数data表示需要被聚类的原始数据集合,一行表示一个数据样本,每一个样本的每一列都是一个属性;参数k表示需要被聚类的个数;参数bestLabels表示每一个样本的类的标签,是一个整数,从0开始的索引整数;参数criteria表示的是算法迭代终止条件;参数attempts表示运行kmeans的次数,取结果最好的那次聚类为最终的聚类,要配合下一个参数flages来使用;参数flags表示的是聚类初始化的条件。其取值有3种情况,如果为KMEANS_RANDOM_CENTERS,则表示为随机选取初始化中心点,如果为KMEANS_PP_CENTERS则表示使用某一种算法来确定初始聚类的点;如果为KMEANS_USE_INITIAL_LABELS,则表示使用用户自定义的初始点,但是如果此时的attempts大于1,则后面的聚类初始点依旧使用随机的方式;参数centers表示的是聚类后的中心点存放矩阵。该函数返回的是聚类结果的紧凑性,其计算公式为:

注意点一:
这是说个我自己不理解的地方:fill(InputOutputArray mat, int distType, InputArray a, InputArray b, bool saturateRange=false )
这里的InputArray a, InputArray b------>>>分别用了Scalar(center.x, center.y, 0, 0), Scalar(img.cols*0.05, img.rows*0.05, 0, 0)去替换
去查了一下手册:InputArray这个接口类可以是Mat、Mat_<T>、Mat_<T, m, n>、vector<T>、vector<vector<T>>、vector<Mat>。没有提到Scalar()可以使用
特意定义了一个:InputArray test = Scalar(1,1);这个又是可以的,定义Mat不行,Vector也不行,这个真的不知道什么原因,有时间得去看源码a,b的使用。
//----下面的定义都是错误的,运行的结果都不对,原因暂时不知道
1 Mat a = (Mat_<uchar>(1, 2) << center.x, center.y); 2 Mat b = (Mat_<uchar>(1, 2) << img.cols*0.05, img.rows*0.05); 3 4 InputArray a1 = Scalar(center.x, center.y); 5 InputArray b1 = Scalar(img.cols*0.05, img.rows*0.05); 6 Mat a2 = a1.getMat(); 7 Mat b2 = b1.getMat(); 8 9 Mat c(1, 2, CV_8UC1); 10 c = Scalar(center.x, center.y); 11 Mat c1(1, 2, CV_8UC1); 12 c1 = Scalar(img.cols*0.05, img.rows*0.05); 13 14 rng.fill(pointChunk, RNG::NORMAL, a, b, 0);
注意点二:
kmeans()函数的输入只接受 data0.dims <= 2 && type == CV_32F && K > 0 ,
第一个dims一般都不会越界(三维不行)
第二个参数CV_32F == float,千万别带入CV_8U == uchar
第三个参数不用说了,设置的种类肯定是大于0的
注意点三:
opencv里面k-means函数的样本数据、标签、中心点的存储:


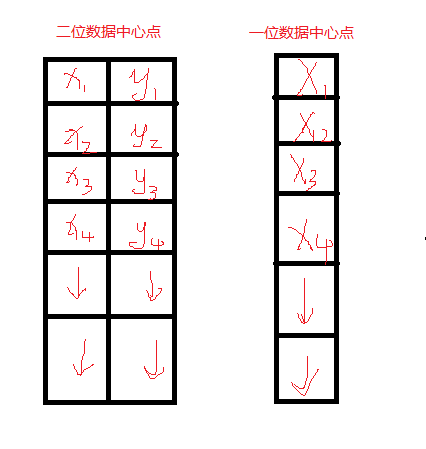
这是正确的代码:(聚类)
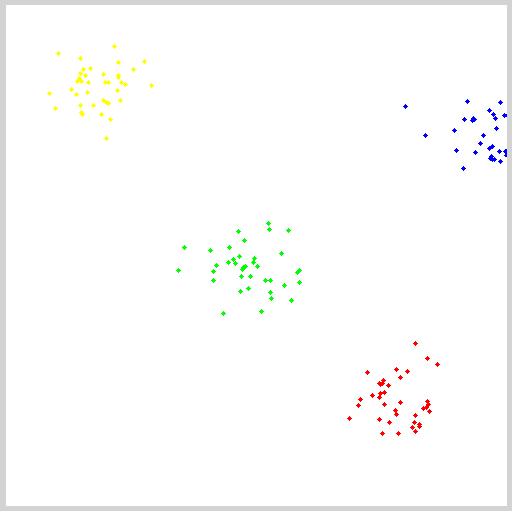
1 #include <opencv2/opencv.hpp> 2 #include <iostream> 3 4 using namespace cv; 5 using namespace std; 6 7 int main(int argc, char** argv) { 8 Mat img(500, 500, CV_8UC3); 9 RNG rng(12345); 10 const int Max_nCluster = 5; 11 Scalar colorTab[] = { 12 Scalar(0, 0, 255), 13 Scalar(0, 255, 0), 14 Scalar(255, 0, 0), 15 Scalar(0, 255, 255), 16 Scalar(255, 0, 255) 17 }; 18 //InputArray a = Scalar(1,1); 19 int numCluster = rng.uniform(2, Max_nCluster + 1);//随机类数 20 int sampleCount = rng.uniform(5, 1000);//样本点数量 21 Mat matPoints(sampleCount, 1, CV_32FC2);//样本点矩阵:sampleCount X 2 22 Mat labels; 23 Mat centers; 24 25 // 生成随机数 26 for (int k = 0; k < numCluster; k++) { 27 Point center;//随机产生中心点 28 center.x = rng.uniform(0, img.cols); 29 center.y = rng.uniform(0, img.rows); 30 Mat pointChunk = matPoints.rowRange( k*sampleCount / numCluster, 31 (k + 1)*sampleCount / numCluster); 32 //-----这句话的意思我不明白作用是什么,没意义啊! 33 /*Mat pointChunk = matPoints.rowRange(k*sampleCount / numCluster, 34 k == numCluster - 1 ? sampleCount : (k + 1)*sampleCount / numCluster);*/ 35 //-----符合高斯分布的随机高斯 36 rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y, 0, 0), Scalar(img.cols*0.05, img.rows*0.05, 0, 0)); 37 } 38 randShuffle(matPoints, 1, &rng);//打乱高斯生成的数据点顺序 39 40 // 使用KMeans 41 kmeans(matPoints, numCluster, labels, TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1), 3, KMEANS_PP_CENTERS, centers); 42 43 // 用不同颜色显示分类 44 img = Scalar::all(255); 45 for (int i = 0; i < sampleCount; i++) { 46 int index = labels.at<int>(i); 47 Point p = matPoints.at<Point2f>(i); 48 circle(img, p, 2, colorTab[index], -1, 8); 49 } 50 51 // 每个聚类的中心来绘制圆 52 for (int i = 0; i < centers.rows; i++) { 53 int x = centers.at<float>(i, 0); 54 int y = centers.at<float>(i, 1); 55 printf("c.x= %d, c.y=%d", x, y); 56 circle(img, Point(x, y), 40, colorTab[i], 1, LINE_AA); 57 } 58 59 imshow("KMeans-Data-Demo", img); 60 waitKey(0); 61 return 0; 62 }

分类代码:
1 #include <opencv2/opencv.hpp> 2 #include <iostream> 3 4 using namespace cv; 5 using namespace std; 6 7 RNG rng(12345); 8 const int Max_nCluster = 5; 9 10 int main(int argc, char** argv) { 11 //Mat img(500, 500, CV_8UC3); 12 Mat inputImage = imread("1.jpg"); 13 assert(!inputImage.data); 14 Scalar colorTab[] = { 15 Scalar(0, 0, 255), 16 Scalar(0, 255, 0), 17 Scalar(255, 0, 0), 18 Scalar(0, 255, 255), 19 Scalar(255, 0, 255) 20 }; 78 Mat matData = Mat::zeros(Size(inputImage.channels(), inputImage.rows*inputImage.cols), CV_32FC1); 79 int ncluster = 5; //rng.uniform(2, Max_nCluster + 1);//聚类数量 80 Mat label;//聚类标签 81 Mat centers(ncluster, 1, matData.type()); 82 for (size_t i = 0; i < inputImage.rows; i++)//把图像存储到样本容器 83 { 84 uchar* ptr = inputImage.ptr<uchar>(i); 85 for (size_t j = 0; j < inputImage.cols; j++) 86 { 87 matData.at<float>(i*inputImage.cols + j, 0) = ptr[j*inputImage.channels()]; 88 matData.at<float>(i*inputImage.cols + j, 1) = ptr[j*inputImage.channels() +1]; 89 matData.at<float>(i*inputImage.cols + j, 2) = ptr[j*inputImage.channels() +2]; 90 } 91 } 92 Mat result = Mat::zeros(inputImage.size(), inputImage.type()); 93 TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 20, 0.1); 94 kmeans(matData, ncluster, label, criteria, 3, KMEANS_PP_CENTERS, centers); 95 for (size_t i = 0; i < inputImage.rows; i++) 96 { 97 for (size_t j = 0; j < inputImage.cols; j ++) 98 { 99 int index = label.at<int>(i*inputImage.cols + j,0); 100 result.at<Vec3b>(i, j)[0] = colorTab[index][0]; 101 result.at<Vec3b>(i, j)[1] = colorTab[index][1]; 102 result.at<Vec3b>(i, j)[2] = colorTab[index][2]; 103 } 104 } 105 imshow("12", result); 106 waitKey(0); 107 return 0; 108 }


参考: 百度百科
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
http://coolshell.cn/articles/7779.html(讲的太好了)
http://www.xuebuyuan.com/414264.html(代码的解释来自这里)
贾老师课程(如果一点不懂得可以看看)