FastHand: Fast Hand Pose Estimation From A Monocular Camera
数据集:
| Dataset | Usage | Des | image resolution | Joints | Images |
|---|---|---|---|---|---|
| Yotube2D | Training | Real-world | 256 × 256 | 21 | 47125 |
| GANeratedHands | Training | Synthetic | 256 × 256 | 21 | 141449 |
| STB | Test | Real-world | 640 × 480 | 21 | 6000 |
| RHD | Test | Synthetic | 320 × 320 | 21 | 2727 |
- 网络部分
Top-to-Down方式,先用mobilenetv2-SSD检测,之后使用指数平均进行跟踪,最后使用heatmap估计函数进行姿态估计

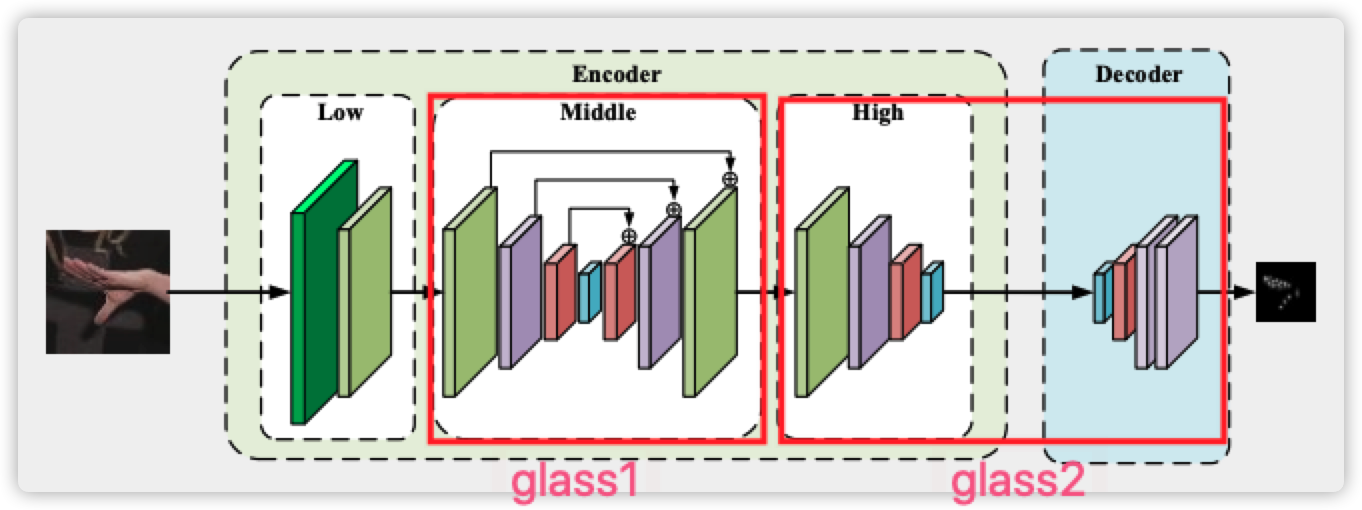
网络部分未用特殊操作,上图 ((b)) 下采样直接使用并行的conv+pooling(在所有阶段使用),上图 ((c)) 上采样直接resize(等于双线性插值,在encoder部分使用),decoder部分的上采样使用三次deconvolution
- 跟踪部分
滑动平均的方式改成指数平均
[P_{cur} = sum_{k=0}^{n}{P_{k} imes frac{e^{-k}}{sum_{j=0}^{n}{e^{-j}}}}
]
(P_{k}) 当前bbox的位置,这里怎么编码怎么来((c_x c_y w h) 或 ( x_{min} y_{min} x_{max} y_{max})),(n) 表示加权平均的数量。
- 比较结果
不清楚作者有没有把 (NSRM-Net) 等网络使用youtube2D+GANeratedHands进行训练,如果直接按照原始论文进行比较结果无意义,公认的STB数据集太简单很容易过拟合,RHD数据集和实际数据差别有点大,Onehand数据数量较少(实际使用有点不干净)。
- 个人观点
- [x] 当前关键点估计网络基本都会使用hourglass结构
- [x] 按照下图划分,其实作者就是使用了两层hourglass
-
[x] 关于作者给出的上下采用具体有没有效果,论文未给数据对比。
- 比如yolov5使用的focus结构下采样
- 比如pixelshuffle的上采样
- 等等
-
[x] 作者说思路和media-pipe比较类似,个人感觉google的创新主要在于使用heatmap进行弱监督
