Disentangled Non-Local Neural Networks
一. 论文简介
理论(部分感觉不是很合理,不懂大佬思维)和实践相结合的论文,感觉很不错,第一次读很难读懂。
解决局部感受野的问题,是上一篇论文 的扩展
主要做的贡献如下(可能之前有人已提出):
- 解决局部感受野,设计一个Block
二. 模块详解
2.1 论文思路简介
全部基于论文的内容进行改进,下述将论文A进行代替:
论文A主要是表达一个函数(f(x_i,x_j)*f(x_j)) ,表示当前像素的表达需要依靠周围像素,前者表示周围像素的权重,后者表示当前像素进行的处理(你也可以直接化简函数(f(x_i,x_j)*x_i))
论文A中的缺点是 (f(x_i,x_j))(当前像素和周围像素的关系函数)在周围像素比较相似的时候,函数的作用会降低为一元函数,那么就起不到原始的意愿:当前像素和周围像素的关系函数
此论文发现(f(x_i,x_j))不能仅仅的表示为两者的关系,还应该包含其他部分。论文里的说法是:此二元函数((pairwise))里面包含一个一元函数((unary))+一个二元函数((pairwise)),得分开来表达。
下附图体现了不同模块表达的函数不同:

2.2 具体实现
2.2.1 理论部分
- 公式(3)的提出,如何得到公式(3),下附图论文只是一笔带过:

补充:
(key = unary) ,(query=piarwise)含义的一样的。
论文使用白化(减均值)进行操作,公式的目的是获得(key)和(query)之间相关性的最大距离,也就是让两个值相互(尽量)独立,这样当周围像素相似才不影响整体的判断。
其中,(q_i,q_j) 表示(query)的当前特征和周围特征,(k_m,k_n) 表示(key)的当前特征和周围特征。
论文使用点乘表示两者的相关性,因为写高斯函数比较复杂,所以简化操作(见论文A)。
那么以下的公式就比较明了,笔者进行化解: (q_i^T*k_m-q_i^T*k_n-k_m^T*q_j) ,第一项表示两者的相关性(肯定越大越好),第二项和第三项表示对对方周围像素的关联性(肯定越小越好),我们最大化这个函数,就能保住两者之间差异性最大化。其实第一项也可以表示成差异性,第二三项表示成关联性,这样更容易理解。
以下公式分子是差异性 ,分母是归一化的求和。

- 公式(4)作者也是一笔带过
补充:
论文前面一直说:(q_i^Tk_j=(q_i-mu_q)^T(k_j-mu_k)) ,为什么到这里突然出现后面三项?
因为论文一直在说一件事,(f(x_i,x_j)) 不仅仅包含(q_i^Tk_j),还影藏的包含了一元函数。
一元函数到底是什么?
既然是未知的,那就全部列出来,(u_q^Tk_j+q_i^Tu_k+u_q^Tu_k) ,这里是上面式子展开的全部组合,具体哪个项的作用具体是什么?论文未进一步讨论。
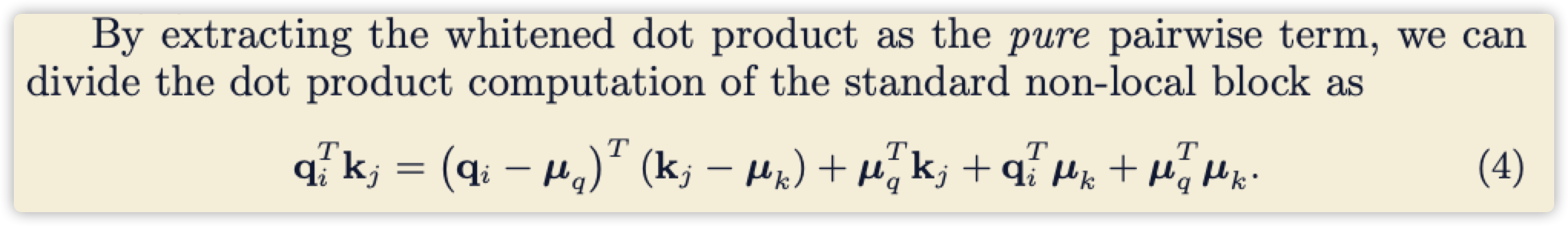
- 公式在视觉上的体现(论文3.2节)
这部分主要对理论的实际展现,通过label和operate的边界交集进行可视化分析
- 反向推导公式的好处(论文3.3节)
通过理论反向推导公式的优势,反向链式求导,add比multi更具有分离性
- 推导(附录)
其中hessian矩阵小于0,获得最大值
2.2.2 具体实现
下图只是一个整体流程图,具体实现得结合公式
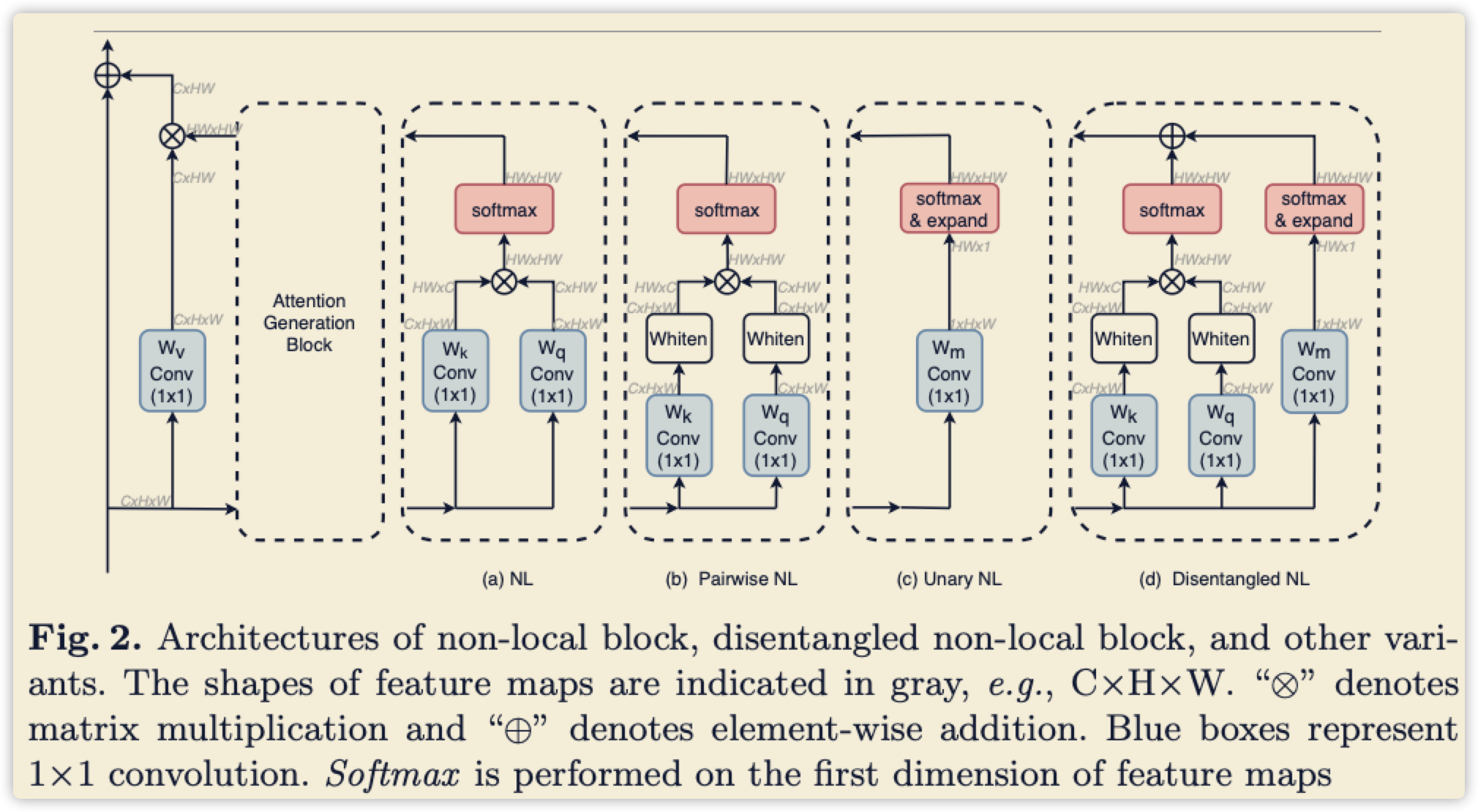 主要有两个实现版本,感觉都不全。
主要有两个实现版本,感觉都不全。
g_k = conv(x), g_q = conv(x), g_m=conv(x), g_w=conv(x)
g_k= = g_k - k_mean, g_q = g_q - q_mean
g_pnl = soft_max( g_k * g_q ), g_m = soft_max(g_m * q_mean) #这里得加上公式里的内容(u_q^Tk_j)
g_dnl = g_pnl + g_m
g_dnl = g_v*g_dnl
x = x + g_dnl
import torch
import torch.nn as nn
from mmcv.cnn import constant_init, normal_init
from ..utils import ConvModule
from mmdet.ops import ContextBlock
from torch.nn.parameter import Parameter
class NonLocal2D(nn.Module):
"""Non-local module.
See https://arxiv.org/abs/1711.07971 for details.
Args:
in_channels (int): Channels of the input feature map.
reduction (int): Channel reduction ratio.
use_scale (bool): Whether to scale pairwise_weight by 1/inter_channels.
conv_cfg (dict): The config dict for convolution layers.
(only applicable to conv_out)
norm_cfg (dict): The config dict for normalization layers.
(only applicable to conv_out)
mode (str): Options are `embedded_gaussian` and `dot_product`.
"""
def __init__(self,
in_channels,
reduction=2,
use_scale=True,
conv_cfg=None,
norm_cfg=None,
mode='embedded_gaussian',
whiten_type=None,
temp=1.0,
downsample=False,
fixbug=False,
learn_t=False,
gcb=None):
super(NonLocal2D, self).__init__()
self.in_channels = in_channels
self.reduction = reduction
self.use_scale = use_scale
self.inter_channels = in_channels // reduction
self.mode = mode
assert mode in ['embedded_gaussian', 'dot_product', 'gaussian']
if mode == 'gaussian':
self.with_embedded = False
else:
self.with_embedded = True
self.whiten_type = whiten_type
assert whiten_type in [None, 'channel', 'bn-like'] # TODO: support more
self.learn_t = learn_t
if self.learn_t:
self.temp = Parameter(torch.Tensor(1))
self.temp.data.fill_(temp)
else:
self.temp = temp
if downsample:
self.downsample = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
else:
self.downsample = None
self.fixbug=fixbug
assert gcb is None or isinstance(gcb, dict)
self.gcb = gcb
if gcb is not None:
self.gc_block = ContextBlock(inplanes=in_channels, **gcb)
else:
self.gc_block = None
# g, theta, phi are actually `nn.Conv2d`. Here we use ConvModule for
# potential usage.
self.g = ConvModule(
self.in_channels,
self.inter_channels,
kernel_size=1,
activation=None)
if self.with_embedded:
self.theta = ConvModule(
self.in_channels,
self.inter_channels,
kernel_size=1,
activation=None)
self.phi = ConvModule(
self.in_channels,
self.inter_channels,
kernel_size=1,
activation=None)
self.conv_out = ConvModule(
self.inter_channels,
self.in_channels,
kernel_size=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=None)
self.init_weights()
def init_weights(self, std=0.01, zeros_init=True):
transform_list = [self.g]
if self.with_embedded:
transform_list.extend([self.theta, self.phi])
for m in transform_list:
normal_init(m.conv, std=std)
if zeros_init:
constant_init(self.conv_out.conv, 0)
else:
normal_init(self.conv_out.conv, std=std)
def embedded_gaussian(self, theta_x, phi_x):
# pairwise_weight: [N, HxW, HxW]
pairwise_weight = torch.matmul(theta_x, phi_x)
if self.use_scale:
# theta_x.shape[-1] is `self.inter_channels`
if self.fixbug:
pairwise_weight /= theta_x.shape[-1]**0.5
else:
pairwise_weight /= theta_x.shape[-1]**-0.5
if self.learn_t:
pairwise_weight = pairwise_weight * nn.functional.softplus(self.temp) # stable training
else:
pairwise_weight = pairwise_weight / self.temp
pairwise_weight = pairwise_weight.softmax(dim=-1)
return pairwise_weight
def gaussian(self, theta_x, phi_x):
return self.embedded_gaussian(theta_x, phi_x)
def dot_product(self, theta_x, phi_x):
# pairwise_weight: [N, HxW, HxW]
pairwise_weight = torch.matmul(theta_x, phi_x)
pairwise_weight /= pairwise_weight.shape[-1]
return pairwise_weight
def forward(self, x):
n, _, h, w = x.shape
if self.downsample:
down_x = self.downsample(x)
else:
down_x = x
# g_x: [N, H'xW', C], VALUE?
g_x = self.g(down_x).view(n, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
# theta_x: [N, HxW, C], QUERY?
if self.with_embedded:
theta_x = self.theta(x).view(n, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
else:
theta_x = x.view(n, self.in_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
# phi_x: [N, C, H'xW'], KEY?
if self.with_embedded:
phi_x = self.phi(down_x).view(n, self.inter_channels, -1)
else:
phi_x = x.view(n, self.in_channels, -1)
# whiten
if self.whiten_type == "channel":
theta_x_mean = theta_x.mean(2).unsqueeze(2)
phi_x_mean = phi_x.mean(2).unsqueeze(2)
theta_x -= theta_x_mean
phi_x -= phi_x_mean
elif self.whiten_type == 'bn-like':
theta_x_mean = theta_x.mean(2).mean(0).unsqueeze(0).unsqueeze(2)
phi_x_mean = phi_x.mean(2).mean(0).unsqueeze(0).unsqueeze(2)
theta_x -= theta_x_mean
phi_x -= phi_x_mean
pairwise_func = getattr(self, self.mode)
# pairwise_weight: [N, HxW, H'xW']
pairwise_weight = pairwise_func(theta_x, phi_x)
# y: [N, HxW, C]
y = torch.matmul(pairwise_weight, g_x)
# y: [N, C, H, W]
y = y.permute(0, 2, 1).reshape(n, self.inter_channels, h, w)
# gc block
if self.gcb:
output = self.gc_block(x) + self.conv_out(y)
else:
output = x + self.conv_out(y)
return output
import torch
import torch.nn.functional as F
#from libs import InPlaceABN, InPlaceABNSync
from torch import nn
from torch.nn import init
import math
class _NonLocalNd_bn(nn.Module):
def __init__(self, dim, inplanes, planes, downsample, use_gn, lr_mult, use_out, out_bn, whiten_type, temperature,
with_gc, with_unary):
assert dim in [1, 2, 3], "dim {} is not supported yet".format(dim)
# assert whiten_type in ['channel', 'spatial']
if dim == 3:
conv_nd = nn.Conv3d
if downsample:
max_pool = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2))
else:
max_pool = None
bn_nd = nn.BatchNorm3d
elif dim == 2:
conv_nd = nn.Conv2d
if downsample:
max_pool = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
else:
max_pool = None
bn_nd = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
if downsample:
max_pool = nn.MaxPool1d(kernel_size=2, stride=2)
else:
max_pool = None
bn_nd = nn.BatchNorm1d
super(_NonLocalNd_bn, self).__init__()
self.conv_query = conv_nd(inplanes, planes, kernel_size=1)
self.conv_key = conv_nd(inplanes, planes, kernel_size=1)
if use_out:
self.conv_value = conv_nd(inplanes, planes, kernel_size=1)
self.conv_out = conv_nd(planes, inplanes, kernel_size=1, bias=False)
else:
self.conv_value = conv_nd(inplanes, inplanes, kernel_size=1, bias=False)
self.conv_out = None
if out_bn:
self.out_bn = nn.BatchNorm2d(inplanes)
else:
self.out_bn = None
if with_gc:
self.conv_mask = conv_nd(inplanes, 1, kernel_size=1)
if 'bn_affine' in whiten_type:
self.key_bn_affine = nn.BatchNorm1d(planes)
self.query_bn_affine = nn.BatchNorm1d(planes)
if 'bn' in whiten_type:
self.key_bn = nn.BatchNorm1d(planes, affine=False)
self.query_bn = nn.BatchNorm1d(planes, affine=False)
self.softmax = nn.Softmax(dim=2)
self.downsample = max_pool
# self.norm = nn.GroupNorm(num_groups=32, num_channels=inplanes) if use_gn else InPlaceABNSync(num_features=inplanes)
self.gamma = nn.Parameter(torch.zeros(1))
self.scale = math.sqrt(planes)
self.whiten_type = whiten_type
self.temperature = temperature
self.with_gc = with_gc
self.with_unary = with_unary
self.reset_parameters()
self.reset_lr_mult(lr_mult)
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Conv3d) or isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
init.zeros_(m.bias)
m.inited = True
# init.constant_(self.norm.weight, 0)
# init.constant_(self.norm.bias, 0)
# self.norm.inited = True
def reset_lr_mult(self, lr_mult):
if lr_mult is not None:
for m in self.modules():
m.lr_mult = lr_mult
else:
print('not change lr_mult')
def forward(self, x):
# [N, C, T, H, W]
residual = x
# [N, C, T, H', W']
if self.downsample is not None:
input_x = self.downsample(x)
else:
input_x = x
# [N, C', T, H, W]
query = self.conv_query(x)
# [N, C', T, H', W']
key = self.conv_key(input_x)
value = self.conv_value(input_x)
# [N, C', H x W]
query = query.view(query.size(0), query.size(1), -1)
# [N, C', H' x W']
key = key.view(key.size(0), key.size(1), -1)
value = value.view(value.size(0), value.size(1), -1)
if 'channel' in self.whiten_type:
key_mean = key.mean(2).unsqueeze(2)
query_mean = query.mean(2).unsqueeze(2)
key -= key_mean
query -= query_mean
if 'spatial' in self.whiten_type:
key_mean = key.mean(1).unsqueeze(1)
query_mean = query.mean(1).unsqueeze(1)
key -= key_mean
query -= query_mean
if 'bn_affine' in self.whiten_type:
key = self.key_bn_affine(key)
query = self.query_bn_affine(query)
if 'bn' in self.whiten_type:
key = self.key_bn(key)
query = self.query_bn(query)
if 'ln_nostd' in self.whiten_type :
key_mean = key.mean(1).mean(1).view(key.size(0), 1, 1)
query_mean = query.mean(1).mean(1).view(query.size(0), 1, 1)
key -= key_mean
query -= query_mean
# [N, T x H x W, T x H' x W']
sim_map = torch.bmm(query.transpose(1, 2), key)
sim_map = sim_map / self.scale
sim_map = sim_map / self.temperature
sim_map = self.softmax(sim_map)
# [N, T x H x W, C']
out_sim = torch.bmm(sim_map, value.transpose(1, 2))
# [N, C', T x H x W]
out_sim = out_sim.transpose(1, 2)
# [N, C', T, H, W]
out_sim = out_sim.view(out_sim.size(0), out_sim.size(1), *x.size()[2:])
# if self.norm is not None:
# out = self.norm(out)
out_sim = self.gamma * out_sim
if self.with_unary:
if query_mean.shape[1] ==1:
query_mean = query_mean.expand(-1, key.shape[1], -1)
unary = torch.bmm(query_mean.transpose(1,2),key)
unary = self.softmax(unary)
out_unary = torch.bmm(value, unary.permute(0,2,1)).unsqueeze(-1)
out_sim = out_sim + out_unary
# out = residual + out_sim
if self.with_gc:
# [N, 1, H', W']
mask = self.conv_mask(input_x)
# [N, 1, H'x W']
mask = mask.view(mask.size(0), mask.size(1), -1)
mask = self.softmax(mask)
# [N, C', 1, 1]
out_gc = torch.bmm(value, mask.permute(0, 2, 1)).unsqueeze(-1)
out_sim = out_sim + out_gc
# [N, C, T, H, W]
if self.conv_out is not None:
out_sim = self.conv_out(out_sim)
if self.out_bn:
out_sim = self.out_bn(out_sim)
out = out_sim + residual
return out
class NonLocal2d_bn(_NonLocalNd_bn):
def __init__(self, inplanes, planes, downsample=True, use_gn=False, lr_mult=None, use_out=False, out_bn=False,
whiten_type=['channel'], temperature=1.0, with_gc=False, with_unary=False):
super(NonLocal2d_bn, self).__init__(dim=2, inplanes=inplanes, planes=planes, downsample=downsample,
use_gn=use_gn, lr_mult=lr_mult, use_out=use_out, out_bn=out_bn,
whiten_type=whiten_type, temperature=temperature, with_gc=with_gc, with_unary=with_unary)