对于文件的存储、传输、磁盘IO读取等操作在使用Hadoop生态圈的存储系统时是非常常见的,而文件的大小等直接影响了这些操作的速度以及对磁盘空间的消耗。
此时,一种常用的方式就是对文件进行压缩。但文件被压缩之后,在读取数据时要先进行解压缩,会对CPU造成一定负担。
因此,在实际生产中,是否对数据进行压缩以及采用哪种方式进行压缩显得尤为重要。需要综合考虑压缩和解压缩数据所需的资源、磁盘IO,以及在网络传输数据所需带宽以及集群的性能和文件的特性等。它至少能带来以下好处:
-
减少磁盘存储空间
-
降低IO(包括磁盘和网络IO),加快数据在磁盘和网络中的传输速度,提升性能
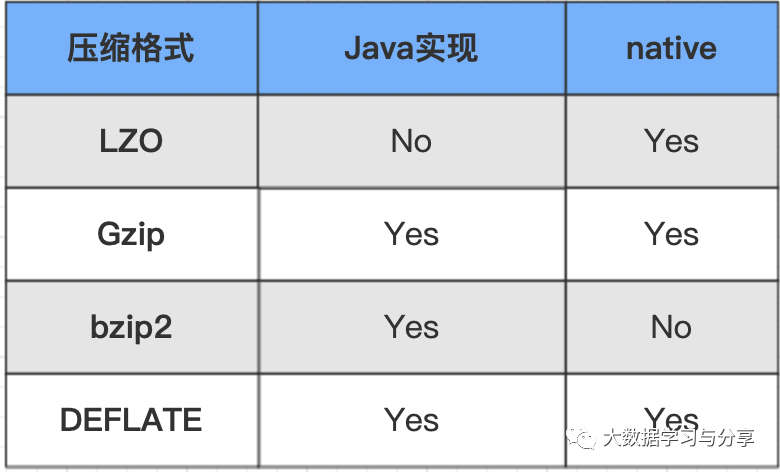
首先来看一下常见的Hadoop压缩格式一览表,以及详细介绍:

snappy压缩
优点:高速压缩速度和合理的压缩率;支持Hadoop native库。
缺点:不支持split;压缩率比gzip要低;Hadoop本身不支持,需要安装;linux系统下没有对应的命令。
应用场景:当MapReduce作业的map输出的数据量比较大的时候,作为map到reduce的中间数据的压缩格式;或者作为一个MapReduce作业的输出和另外一个MapReduce作业的输入。
lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是Hadoop中最流行的压缩格式;支持Hadoop native库;可以在linux系统下安装lzop命令,使用方便。
缺点:压缩率比gzip要低一些;hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显。
gzip压缩
优点:压缩率比较高,而且压缩/解压速度也比较快;Hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有Hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split
应用场景:当每个文件压缩之后在130M以内的,都可以考虑用gzip压缩格式。比如每天的日志压缩成一个gzip文件,运行MapReduce程序的时候通过多个gzip文件达到并发。对于处理这些文件的程序(如Hive、流、MapReduce程序)完全和文本处理一样,压缩之后原来的程序不需要做任何修改。
bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;Hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
应用场景:适合对速度要求不高,但需要较高的压缩率的场景。可以作为MapReduce作业的输出格式;输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
在介绍上述压缩格式时,强调了它们是否对Hadoop native库的支持,因为是否支持Hadoop native库对性能产生巨大影响。
Hadoop是使用Java语言开发的,但是有些操作并不总适合使用Java,所以才引入了native库即本地库的概念。通过使用本地库,Hadoop可更加高效的执行某些操作。
Hadoop带有预置的32位和64位Linux的本地压缩库。
本地库通过Java系统属性java.library.path来使用。Hadoop的脚本在bin目录中已经设置好这个属性,但如果不使用该脚本,则需要在应用中设置属性。
默认情况下,Hadoop会在它运行的平台上查找本地库,如果发现就自动加载,这意味着不需要修改任何配置就可以使用本地库。如果想禁用本地库(比如需要调试压缩相关问题),则将属性hadoop.native.lib设置为false,即可确保内置的Java等同内置实现 被使用(如果它们可用的话)。