注:因本文撰写的时候参考了大量资料和博文,出处在此就不全部列出了,非常感谢前辈们分享的学习心得
有人归纳了计算机的五大常用算法,它们是贪心算法,动态规划算法,分治算法,回溯算法以及分支限界算法。虽然不知道为何要将这五个算法归为最常用的算法,但是毫无疑问,这五个算法是有很多应用场景的,最优化问题大多可以利用这些算法解决 ,接下来介绍的就是贪心算法。
一 贪心算法的概念
所谓贪心算法,是指在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。举个例子就很清楚了:现在有一个能装4斤苹果的袋子,苹果有两种,一种3斤一个,一种2斤一个,怎么装才能得到最多苹果?当然如果是我们人考虑的话当然是拿两个2斤的苹果,就刚好装满了,但是如果按贪心算法拿的话,首先就要把最重的那个3斤的苹果拿下(局部最优),但其实拿2个2斤的苹果能刚好装4斤,所以并没有得到最多苹果(整体最优)。
二 什么问题适合用贪心算法
对于一个详细的问题,怎么知道是否可用贪心算法解此问题,以及是否能得到问题的最优解? 我们能够依据贪心法的俩个重要的性质去证明:贪心选择性质和最优子结构性质。
贪心选择:什么叫贪心选择?从字义上就是贪心也就是目光短线。贪图眼前利益。在算法中就是仅仅依据当前已有的信息就做出选择,并且以后都不会改变这次选择。(这是和动态规划法的主要差别)所以对于一个详细问题。要确定它是否具有贪心选择性质,必须证明每做一步贪心选择是否终于导致问题的总体最优解
最优子结构:当一个问题的最优解包括其子问题的最优解时,称此问题具有最优子结构性质。这个性质和动态规划法的一样,是可用动态规划算法或贪心算法求解的关键特征。
区分动态规划:动态规划算法通常以自底向上的方式解各子问题,是递归过程;贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。以遍历二叉树为例:贪心算法是从上到下仅仅进行深度搜索,也就是说它从根节点一口气走到底,它的代价取决于子问题的数目,也就是树的高度,每次在当前问题的状态上作出的选择都是1,不进行广度搜索,所以它得到的解不一定是最优解,很可能是近似最优解;而动态规划算法在最优子结构的前提下,从树的叶子节点开始向上进行搜索,而且每一步都依据叶子节点的当前问题的状况作出选择,从而作出最优决策,所以它的代价是子问题的个数和可选择的数目,它得到的解一定是最优解。
三 贪心算法的求解过程
一般求解过程:
- 候选集合(C):通过一个候选集合C作为问题的可能解
- 解集合(S): 每完毕一次贪心选择,将一个解放入S
- 解决函数(solve): 检查解集合S是否构成问题的完整解
- 选择函数(select): 即贪心策略,选择出最有希望构成问题的解的对象
- 可行函数(availabe): 检查解集合中增加一个候选对象是否可行
代码实现:
Greedy(C) //C是问题的输入集合即候选集合
{
S={ }; //初始解集合为空集
while(not solve(S)) //集合S没有构成问题的一个解
{
x=select(C); //在候选集合C中做贪心选择
if availabe(S, x) //推断集合S中增加x后的解是否可行
S=S+{x};
C=C-{x};
}
return S;
}
四 经典案例分析
[活动选择问题]这是《算法导论》上的一个案例,也是一个非常经典的问题:
学校只有一个教室,下面表格i代表活动的编号,s代表活动开始时间,f代表活动结束时间,现在问题是怎么安排这些活动使得尽量多的活动能不冲突的举行?
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
s[i] |
1 |
3 |
0 |
5 |
3 |
5 |
6 |
8 |
8 |
2 |
12 |
|
f[i] |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
表 1.1 活动时间表
用动态规划的话较麻烦:假设我已经知道第k个活动是活动序列之一,那么又把1到k和k到11看做两个子问题继续分下去。
用贪心算法的话很简单:活动越早结束,剩余的时间越多,那就找到最早结束的那个活动,找到后在剩下的活动中再找最早结束的,最后输出找到的总数。
贪心选择示例:
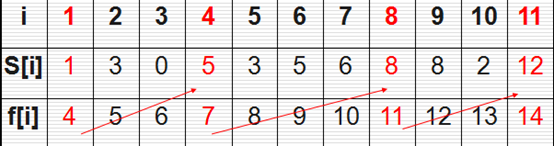
图 1.1 贪心选择图
流程图示例:
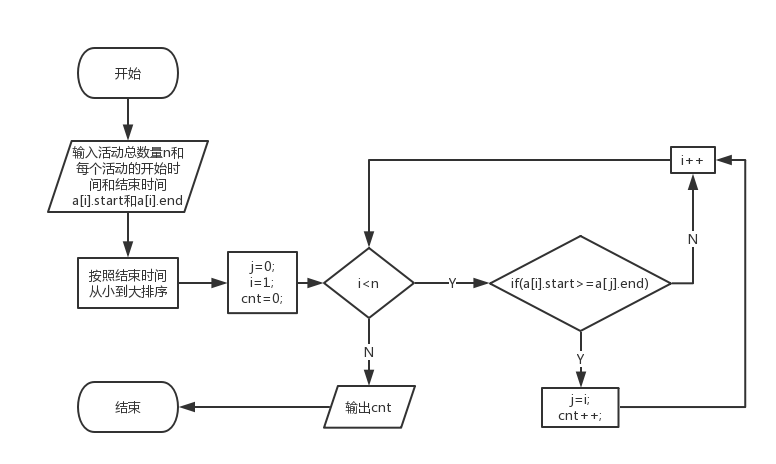
图 1.2 思路流程图
代码:
#include<bits/stdc++.h> using namespace std;
int N;
struct Act { int start; int end; }act[100010];
bool cmp(Act a,Act b) { return a.end<b.end; }
int greedy_activity_selector() { int num=1,i=1; for(int j=2;j<=N;j++) { if(act[j].start>=act[i].end) { i=j; num++; } } return num; } int main() { int t; scanf("%d",&t); while(t--) { scanf("%d",&N); for(int i=1;i<=N;i++) { scanf("%lld %lld",&act[i].start,&act[i].end); } act[0].start=-1; act[0].end=-1; sort(act+1,act+N+1,cmp); int res=greedy_activity_selector(); cout<<res<<endl; } }
虽然贪心算法的思想简单,但是贪心法不保证能得到问题的最优解,如果得不到最优解,那就不是我们想要的东西了,比如常见的背包问题就不能使用贪心算法,下面举个例子:
[0-1背包问题]有一个背包,背包容量是M=150。有7个物品,有着各自的重量和价值。现要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。
物品 A B C D E F G
重量 35 30 60 50 40 10 25
价值 10 40 30 50 35 40 30
分析:
目标函数:∑pi最大
约束条件是装入的物品总重量不超过背包容量:∑wi<=M( M=150)
3种贪心策略:
(1)每次挑选价值最大的物品装入背包,是否能得到最优解?
(2)每次挑选所占重量最小的物品装入背包,是否能得到最优解?
(3)每次选取单位重量价值最大的物品装入背包,是否能得到最优解?
证明:
一般来说,贪心算法的证明围绕着:整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
对于例题中的3种贪心策略,都是无法被证明的,解释如下:
(1)贪心策略:选取价值最大者。反例:
W=30
物品:A B C
重量:28 12 12
价值:30 20 20
根据策略,首先选取物品A,接下来就无法再选取了,可是,选取B、C则更好。
(2)贪心策略:选取重量最小者。它的反例与第一种策略的反例差不多。
(3)贪心策略:选取单位重量价值最大者。反例:
W=30
物品:A B C
重量:28 20 10
价值:28 20 10
根据策略,三种物品单位重量价值一样,程序无法依据现有策略作出判断,如果选择物品A,则答案错误。
但如果现在考虑这样一种背包问题:在选择物品i装入背包时,可以选择物品的一部分,而不一定要全部装入背包,即可以分割物品,这时便可以使用贪心算法求解了。计算每种物品的单位重量价值作为贪心选择的依据指标,选择单位重量价值最高的物品,将尽可能多的该物品装入背包,依此策略一直地进行下去,直到背包装满为止。在之前的0-1背包问题中三种贪心策略之所以不能得到最优解的原因是贪心选择无法保证最终能将背包装满,部分闲置的背包空间使每公斤背包空间的价值降低了。以HDUOJ-1009为例:
[老鼠交易问题]老鼠准备了M磅的猫粮,准备与守卫他最喜欢的食物JavaBean的仓库的猫交易。该仓库有N个房间。第i个房间包含J[i]磅的JavaBeans并且需要F[i]磅的猫粮。老鼠不需要为房间里的所有JavaBeans进行交易,相反,如果他支付F[i]*a%磅的猫粮,他会得到J[i]*a%磅的JavaBeans。现在要求出老鼠能得到的最多的JavaBean的数量。
分析:这道题其实就是一个0-1背包问题,只不过物品可以被分割的放进背包中,所以我们的贪心策略当然是选取单位数量价值最大者放进背包。
代码:
#include<bits/stdc++.h> using namespace std;
struct jb { double j,f,avg;//用于保存每个房间的信息 };
bool cmp(jb x,jb y) { return x.avg<y.avg;//定义排序规则,即均值小的排在前面 }
int main() { double n; int m; while(cin>>n>>m&&n!=-1) { jb s[1001]; for(int i=0;i<m;i++) { cin>>s[i].j>>s[i].f; s[i].avg=s[i].j/s[i].f; } sort(s,s+m,cmp); double sum=0; for(int i=m-1;i>=0;--i)//从均值最大的房间开始兑换 { if(n>=s[i].f)//如果剩余的猫粮多余房间所需猫粮 { n-=s[i].f; sum+=s[i].j; } else if(n<s[i].f&&n>0)//如果剩余猫粮少于房间所需猫粮 { sum+=s[i].avg*n; break; } } printf("%.3lf ",sum); } }
[小船过河问题]有n个人想过河,每个人过河都有自己的过河时间,但只有一只小船,最多只能装2个人,每一次过河,过河时间为用时最多的那人过河时间,如果还有人没有过河,那么过去一个用时最少的送回船。问n人过河最少要多少时间。
分析:POJ-1700是一道经典的贪心算法例题,在这道题中可以先将所有人过河所需的时间按照升序排序,我们考虑把单独过河所需要时间最多的两个旅行者送到对岸去,有两种贪心策略:
(1)最快的和次快的过河,然后最快的将船划回来;最慢的和次慢的过河,然后次快的将船划回来,所需时间为:t[0]+2*t[1]+t[n-1]
(2)最快的和最慢的过河,然后最快的将船划回来;最快的和次慢的过河,然后最快的将船划回来,所需时间为:2*t[0]+t[n-2]+t[n-1]
代码:
#include<bits/stdc++.h> using namespace std;
int main() { int a[1000],t,n,sum; cin>>t; while(t--) { cin>>n; sum=0; for(int i=0;i<n;i++)cin>>a[i]; while(n>3) {
sum=min(sum+a[1]+a[0]+a[n-1]+a[1],sum+a[n-1]+a[0]+a[n-2]+a[0]);//选则两种贪心策略中数值较小的一个 n-=2;//一次可以送走两个人 } if(n==3)sum+=a[0]+a[1]+a[2];//当剩余人数等于3时,0和1过河,0反回,然后0和2过河 else if(n==2)sum+=a[1]; else sum+=a[0]; printf("%d ",sum); } }
五 结论
贪心算法既然被列为五大常用算法之一,肯定在算法中占据了不小的地位,虽然贪心思想比较简单,但熟练应用贪心思想绝对是我们必备的技能,在一些最优化问题中常常需要运用贪心思想,像数据结构中的Huffman编码,Dijkstra算法,Kruskal算法和Prim算法都能看见贪心思想的身影,所以千万一定不能小觑贪心算法!