1.
在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎.在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词.
在学习之前,请确认自己的MySQL版本大于5.7.6.我的版本为8.0.同时文中的所有操作都基于InnoDB存储引擎.
查询mysql版本,设置全文索引分词长度
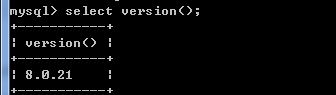
SELECT VERSION();
show variables like 'ft_min_word_len';
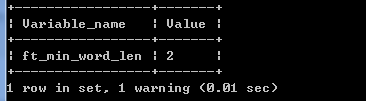
如果 ft_min_word_len 没有设置,停止MySQL,在my.ini中增加 ft_min_word_len = 1,重启MySQL。
2.创建数据表,并插入测试数据
CREATE TABLE students ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, user_name VARCHAR (200), FULLTEXT (user_name) WITH PARSER ngram ) ENGINE = INNODB DEFAULT CHARSET=utf8mb4 COMMENT='students';
WITH PARSER ngram 注意一定要有这个,因为要做中文分词检索。
INSERT INTO `test`.`students` (`user_name`) VALUES ( '李思一'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '李思二'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '李思三'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '李思适当放松的放松'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '王武'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '赵六'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '刘备'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '曹操'); INSERT INTO `test`.`students` (`user_name`) VALUES ( '观月');
3.查询
(1) 自然语言搜索
就是普通的包含关键词的搜索.
(2) BOOLEAN MODE
这个模式和lucene中的BooleanQuery很像,可以通过一些操作符,来指定搜索词在结果中的包含情况.比如 +嘻哈表示必须包含嘻哈, -嘻哈表示必须不包含,默认为误操作符,代表可以出现可以不出现,但是出现时在查询结果集中的排名较高一些.也就是该结果和搜索词的相关性高一些.
使用自然语言搜索如下:
SELECT * from students where MATCH(user_name) AGAINST('李思');
SELECT * from students where MATCH(user_name) AGAINST('李思' IN NATURAL LANGUAGE MODE);
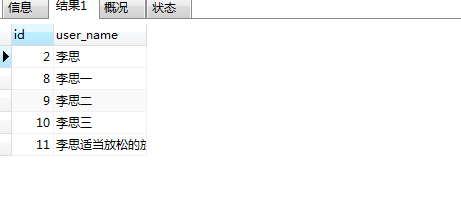
使用boolean搜索如下:
SELECT * from students where MATCH(user_name) AGAINST('李思' IN BOOLEAN MODE);
4.ft_boolean_syntax (+ -><()~*:""&|)使用的例子:
4.1 + : 用在词的前面,表示一定要包含该词,并且必须在开始位置。
eg: +Apple 匹配:Apple123, "tommy, Apple"
4.2 - : 不包含该词,所以不能只用「-yoursql」这样是查不到任何row的,必须搭配其他语法使用。
eg: MATCH (girl_name) AGAINST ('-林志玲 +张筱雨')
匹配到: 所有不包含林志玲,但包含张筱雨的记录
4.3. 空(也就是默认情况),表示可选的,包含该词的顺序较高。
例子:
apple banana 找至少包含上面词中的一个的记录行
+apple +juice 两个词均在被包含
+apple macintosh 包含词 “apple”,但是如果同时包含 “macintosh”,它的排列将更高一些
+apple -macintosh 包含 “apple” 但不包含 “macintosh”
4.4. > :提高该字的相关性,查询的结果会排在比较靠前的位置。
4.5.< :降低相关性,查询的结果会排在比较靠后的位置。
例子:4.5.1.先不使用 ><
select * from tommy.girl where match(girl_name) against('张欣婷' in boolean mode);
 可以看到完全匹配的排的比较靠前
可以看到完全匹配的排的比较靠前
4.5.2. 单独使用 >
select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴' in boolean mode);
 使用了>的李秀琴马上就排到最前面了
使用了>的李秀琴马上就排到最前面了
4.5.3. 单独使用 <
select * from tommy.girl where match(girl_name) against('张欣婷 <不是人' in boolean mode);
 看到没,不是人也排到最前面了,这里使用的可是 < 哦,说好的降低相关性呢,往下看吧。
看到没,不是人也排到最前面了,这里使用的可是 < 哦,说好的降低相关性呢,往下看吧。
4.5.4.同时使用><
select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴 <练习册 <不是人 >是个鬼' in boolean mode);
 到这里终于有答案了,只要使用了 ><的都会往前排,而且>的总是排在<的前面
到这里终于有答案了,只要使用了 ><的都会往前排,而且>的总是排在<的前面
小结一下:1. 只要使用 ><的总比没用的 靠前;
2. 使用 >的一定比 <的排的靠前 (这就符合相关性提高和降低);
3. 使用同一类的,使用的越早,排的越前。