最近设计家谱树的时候,找了相关资料,一般都是用的递归模式,其实还有一种SQL Antipatterns 的设计思路,以下会分两章来讲解SQL 反模式。
假设你是一个著名的科技新闻网站的软件开发者。这是一个现代化的网站,读者可以发表评论,甚至互相回复,
形成深层次的讨论线。你可以选择一个简单的解决方案来跟踪这些回复链:每个评论都引用它回复的评论。
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT UNSIGNED,
comment TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id)
);
但是,很快就可以清楚地看到,很难在单个SQL查询中检索到一长串答复。你仅仅能得到直接的子节点或可能要加入的孙节点。
然而这些线可以有无限的深度。你需要运行许多SQL查询才能获得给定那条线上的所有评论。
你的另一个想法是检索所有的评论,并将它们组装到应用程序内存中的树数据结构中,使用你在学校中学到的传统树算法。
但是网站的出版商告诉你,他们每天发表数十篇文章,每篇文章都可以有数百条评论。
每次有人浏览该网站时,都会对数百万条评论进行排序,很显然这是不切实际的。
必须要有更好的方法来存储这些评论线,这样你才能简单有效地检索整条讨论线。
一、目标:存储和查询层次结构
数据具有递归关系是很常见的。数据可以以树状或分层的方式被组织化。
在树状数据结构中,每个条目称为节点。一个节点可能有若干个子节点和一个父节点。
顶部节点没有父节点,称为根节点。底部的节点没有子节点,称为叶子节点。中间的节点叫做非叶节点。
在以前的层次结构数据中,你可能需要查询单个项、集合的相关子集或整个集合。
树型数据结构的实例包括以下:
1、组织结构图:员工与管理者的关系是树型数据结构的典型例子。它出现在和SQL相关的无数书籍和文章中。
在组织结构图中,每个员工有一个管理者,在树型结构中代表员工的父节点,同样管理者也是一名员工。、
2、以线型方式组织的讨论:树型结构可用于评论链,以回应其他评论。在树中,评论节点的子节点是它的答复。
以下我们将以线型方式组织的讨论,来举例展示反模式及其解决方案。
二、反模式:总是依赖于父节点
很多书籍和文章中,常见的解决方案是添加一个parent_id列。此列引用同一表中的另一个评论,
你可以创建一个外键约束以强制执行他的关系。SQL表结构如下:
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT UNSIGNED,
bug_id BIGINT UNSIGNED NOT NULL,
author BIGINT UNSIGNED NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id), FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
实体关系图如下:
#图3.1#
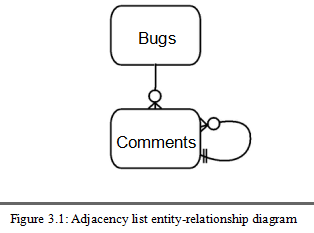
这种设计称为邻接表。它可能是开发人员用来存储分层数据结构最常见的设计方式。
下表是一些显示评论层次结构的示例数据,以及实例的树如下图3.2所示
#表3.2#

#图3.2#
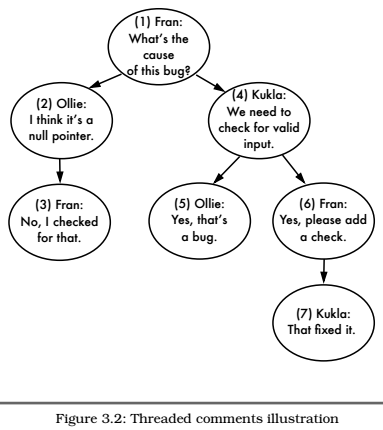
用邻接表查询树
当邻接表是许多开发人员的默认选择时,它可能是反模式的,但它不能解决你需要使用树来执行的最常见任务之一:查询所有后代。
你可以使用一个相对简单的查询,检索一个评论及其直接子节点:
SELECT c1.*, c2.*
FROM Comments c1 LEFT OUTER JOIN Comments c2
ON c2.parent_id = c1.comment_id;
但是,这只查询两层结构的树。树的一个特点是它可以扩展到任意深度,所以你需要能够查询所有后代,而不考虑层次数。
例如,你可能需要计算评论的总数:COUNT() 或 机械组件中部件成本的总和:SUM()
当你使用邻接表时,这种查询是很尴尬的,因为树的每个层级对应于另一个连接,而SQL查询中的连接数必须是固定的。
以下查询检索一棵深度可达四层的树,但不能检索超过此深度的树:
SELECT c1.*, c2.*, c3.*, c4.*
FROM Comments c1 -- 1st level
LEFT OUTER JOIN Comments c2
ON c2.parent_id = c1.comment_id -- 2nd level
LEFT OUTER JOIN Comments c3
ON c3.parent_id = c2.comment_id -- 3rd level
LEFT OUTER JOIN Comments c4
ON c4.parent_id = c3.comment_id; -- 4th level
这个查询也很尴尬,因为它通过添加更多的列,来包含更深层次的后代。这使得计算诸如count()之类的聚合函数变得困难。
从邻接表中查询树型结构的另一种方式,是检索集合中的所有行,然后重建应用程序中的层次结构,才能把它当作树型结构使用。
SELECT * FROM Comments WHERE bug_id = 1234;
在进行分析之前,将大量的数据从数据库复制到应用程序,这是非常低效的。
你可能只需要一个子树,而不是从顶部开始的整个树。你可能只需要数据的集合信息,如评论的计数COUNT()。
用邻接表维护树
诚然,有些操作很容易用邻接表来完成。
例如添加一个新的叶子节点:
INSERT INTO Comments (bug_id, parent_id, author, comment) VALUES (1234, 7, 'Kukla' , 'Thanks!' );
迁移单个节点或子树也很容易:
UPDATE Comments SET parent_id = 3 WHERE comment_id = 6;
但是,从树中删除节点要复杂得多。如果要删除整个子树,则必须要多个查询才能找到所有后代节点。
然后从最底层删除后代节点,以满足外键的完整性。
SELECT comment_id FROM Comments WHERE parent_id = 4; -- returns 5 and 6
SELECT comment_id FROM Comments WHERE parent_id = 5; -- returns none
SELECT comment_id FROM Comments WHERE parent_id = 6; -- returns 7
SELECT comment_id FROM Comments WHERE parent_id = 7; -- returns none
DELETE FROM Comments WHERE comment_id IN ( 7 );
DELETE FROM Comments WHERE comment_id IN ( 5, 6 );
DELETE FROM Comments WHERE comment_id = 4;
你可以使用外键与ON DELETE CASCADE 修饰符自动匹配,只要你知道你总是想删除后代节点,而不是提升或重新定位他们。
如果你想要删除一个非叶节点并提升它的子节点,或者将它们移动到树中的另一个位置,那么首先需要更改子节点的parent_id,然后删除所需的节点。
SELECT parent_id FROM Comments WHERE comment_id = 6; -- returns 4
UPDATE Comments SET parent_id = 4 WHERE parent_id = 6;
DELETE FROM Comments WHERE comment_id = 6;
以上是在使用邻接表设计时需要多个步骤的操作示例。这是你为了让数据库应该更简单、更高效,而必须要编写的代码。
三、如何辨别是否使用反模式?
如果你听到下面这样的问题,那么这是一个树的反模式正在被使用的线索:
--我们需要在树模型中支持多少层?
在不使用递归查询的情况下,你很难查询某个节点的所有祖先或者所有子后代节点,你可能妥协地仅支持有限深度的一棵树,
但是自然联想到下一个问题,多深是足够深?
--我害怕碰到管理树数据结构的代码。
你已经采用了一种更复杂的管理层次结构解决方案,但你使用的是错误的解决方案。
每种技术都使一些任务更容易,但通常以其他任务变得更复杂为代价。
对于在应用中使用层次结构的方式,你可能选择了一个不是最佳选择的解决方案。
--我需要定期运行一个脚本来清理树中孤立的行。
你的应用程序在树中删除非叶节点时,会创建断开连接的节点。当你在数据库中存储复杂数据结构时,
在进行任何更改后,你需要将结构保持在一个一致并且有效的状态。你可以使用后面介绍的解决方案之一,
以及触发器和级联外键约束。来存储具有弹性的数据结构,而不是脆弱的数据结构。
四、合理使用反模式
邻接表设计可以很好地支持你在应用程序中需要做的工作。它的强大之处是检索指定节点的直接父节点或子节点。
插入行也很容易。如果这是你对分层数据所需要的全部操作,那么邻接表可以很好地处理。
一些RDBMS支持对SQL的扩展,来支持存储在邻接表格式中的层次结构。SQL99标准在普通表语法后使用with关键字来定义递归查询。
WITH CommentTree
(comment_id, bug_id, parent_id, author, comment, depth)
AS (
SELECT *, 0 AS depth FROM Comments WHERE parent_id IS NULL
UNION ALL
SELECT c.*, ct.depth+1 AS depth FROM CommentTree ct
JOIN Comments c ON (ct.comment_id = c.parent_id)
)
SELECT * FROM CommentTree WHERE bug_id = 1234;
MicrosoftSQLServer 2005、Oracle11g、IBMDB 2和PostgreSQL8.4支持使用公共表表达式的递归查询,如前面所示。
MySQL、SQLite和Informix是不支持这种语法的数据库品牌的例子。
对于仍然被广泛使用的Oracle 10g也是如此。我们可能会假设递归查询语法将能用于所有流行品牌,然后使用邻接表将不会有如此限制。
Oracle 9i和10g支持With 语句,但不是递归查询。然后,有专用的语法:START WITH 和 CONNECT BY PRIOR。可以使用此语法执行递归查询::
SELECT * FROM Comments
START WITH comment_id = 9876
CONNECT BY PRIOR parent_id = comment_id;
本文翻译自 Bill_Karwin-SQL_Antipatterns-EN 书籍第三章
如有转载,请标明来源:http://www.cnblogs.com/wjq310/p/8849852.html