1. 流量控制 - Flow Control
序言:数据的传送与接收过程当中很可能出现收方来不及接收的情况,这时就需要对发方进行控制以免数据丢失。利用滑动窗口机制可以很方便的在TCP连接上实现对发送方的流量控制。TCP的窗口单位是字节,不是报文段,发送方的发送窗口不能超过接收方给出的接收窗口的数值。

说明:使发送方暂停发送的状态将持续到主机B重新发出一个新的窗口值为止。B向A发送的三个报文段都设置了ACK=1。
考虑一种特殊的情况,接收方若没有缓存足够使用,就会发送零窗口大小的报文,此时发送放将发送窗口设置为0,停止发送数据;之后接收方有足够缓存,发送了非零窗口大小的报文,但是这个报文中途丢失,那么发送方的发送窗口就一直为0导致死锁。为此,TCP为每一个连接设有一个持续计时器(Persistence Timer)。当TCP连接的一方收到对方的零窗口通知时就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口探测报文段(携有1字节的数据),那么收到这个报文段的一方就重新设置持续计时器,给出现在的窗口值。
TCP规定,即使设置为零窗口,也必须接收以下几种报文段:零窗口探测报文段、确认报文段和携带紧急数据的报文段。
1.1 传输效率问题
可以用不同的机制控制TCP报文段的发送时机:
[1]. TCP维持一个变量MSS,等于最大报文段长度。只要缓冲区存放的数据达到MSS字节时,就组装成了一个TCP报文段发送出去。
[2]. 由发送方的应用进程指明要发送的报文段,即:TCP支持推送操作。
[3]. 发送方的一个计时器期限到了,这时就把当前已有的缓存数据装入报文段(但长度不能超过MSS大小)发送出去。
1.2 Nagle算法
发送方把第一个数据字节发送出去,把后面到达的数据字节缓存起来。当发送方接收对第一个数据字符的确认后,再把发送缓存中的所有数据组装成一个报文段再发送出去,同时继续对随后到达的数据进行缓存。只有在收到对前一个报文段的确认后,才继续发送下一个报文段。规定一个TCP连接最多只能有一个未被确认的未完成的小分组,在该分组的确认到达之前不能发送其他的小分组。当数据到达较快而网络速率较慢时,用这样的方法可明显地减少所用的网络带宽。
Nagle算法还规定:当到达的数据已达到发送窗口大小的一半或已经达到报文段的最大长度时,就可立即发送一个报文段。
1.3 糊涂窗口综合症
TCP接收方的缓存已满,而交互式的应用进程一次只从接收缓存中读取1字节(这样就使接收缓存空间仅腾出1字节),然后向发送方发送确认,并把窗口设置为1个字节(但发送的数据报为40字节的的话)。然后,发送方又发来1个字节的数据(发送方的IP数据报是41字节),接收方发回确认,仍然将窗口设置为1个字节。这样,网络的效率很低。要解决这个问题,可让接收方等待一段时间,使得或者接收缓存已有足够空间容纳一个最长的报文段或者等到接收方缓存已有一半的空闲空间。只要出现这两种情况,接收方就发回确认报文,并向发送方通知当前的窗口大小。此外,发送方也不要发送太小的报文段,而是把数据报积累成足够大的报文段,或达到接收方缓存的空间的一半大小。
2. 拥塞控制 - Congestion Control
序言:网络拥塞现象是指到达通信子网中某一部分的分组数量过多,使得该部分网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时导致网络通信业务陷入停顿出现死锁现象。拥塞控制是通过拥塞窗口处理网络拥塞现象的一种机制。
发送报文段速率确定:
[1]. 全局考虑防止拥塞 <- - 拥塞窗口 (Congestion Window) - -> 发送端流量控制,发送端根据自己估计的网络拥塞程度而设置的窗口值;
[2]. 接收端的接收能力 <- - 接收窗口 (Reciver Window) - -> 接收端流量控制,接收端根据目前的接收缓存大小所许诺的最新窗口值;发送方窗口的上限值 = Min [ rwind, cwind ]
当rwind < cwind 时,接收方的接收能力限制发送方窗口的最大值。
当cwind < rwind 时,网络的拥塞限制发送方窗口的最大值。
因特网建议标准RFC2581定义了拥塞控制的四种算法:慢开始(Slow-start),拥塞避免(Congestion Avoidance),快重传(Fast Restrangsmit)和快恢复(Fast Recovery)。我们假定
- 数据单方向传送,而另外一个方向只传送确认;
- 接收方总是有足够大的缓存空间,因为发送窗口的大小由网络的拥塞程度来决定。
2.1 慢启动 - (Slow Start) 和 拥塞避免 - (Congestion Avoidance)
慢启动:
发送方维护一个拥塞窗口cwind的状态变量。拥塞窗口的大小取决于网络的拥塞程度,动态变化。通过逐渐增加cwind的大小来探测可用的网络容量,防止连接开始时采用不合适的发送量导致网络拥塞。
- 当主机开始发送数据时,如果通过较大的发送窗口立即将全部数据字节都注入到网络中,由于不清楚网络情况,有可能引起网络拥塞;
- 较好方法是试探,从小到达逐渐增大发送端拥塞控制窗口的cwind数值;
- 开始发送报文段时,先将拥塞窗口cwind设置为一个最大报文段MSS值。每收到一个对新报文段的ACK确认后,将拥塞窗口cwind增加至多一个MSS的数值。当rwind足够大的时候,为防止拥塞窗口cwind的增长引起网络拥塞,还需要另外一个变量,慢开始门限ssthresh。
- 当 cwind < ssthresh时,使用上述慢启动算法;
- 当 cwind > ssthresh时,停止使用慢启动算法,改用拥塞避免算法;
慢启动局限性:
- 需要获得网络内部流量分布的信息,浪费可用的网络容量,额外开销;
- 估算合理的ssthresh值并不容易,可能耗时较长;
慢启动的“慢”并不是指cwind的增长速度慢,而是指在TCP开始发送报文段时先设置cwind=1,使得发送方在开始时只发送一个报文段(目的是探测一下网络的拥塞情况),然后再逐渐增大cwind。
拥塞避免:
让拥塞窗口cwind缓慢地增大,每经过一个往返时间RTT就把发送方的拥塞窗口cwind加1,而不是加倍。这样拥塞窗口cwind线性缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
无论慢启动开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认),就要把慢启动门限ssthresh设置为出现拥塞时的发送方窗口值的一半(但不能小于2)。然后把拥塞窗口cwind重新设置为1,执行慢启动算法。目的是迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
控制过程:
- TCP连接初始化,将拥塞窗口cwind设置为1个报文段,即cwind=1;
- 执行慢开始算法,cwind按指数规律增长,直到cwind == ssthresh时,开始执行拥塞避免算法,cwind按线性规律增长;
- 当网络发生拥塞,把ssthresh值更新为拥塞前ssthresh值的一半,cwind重新设置为1,再按照 [2] 执行。
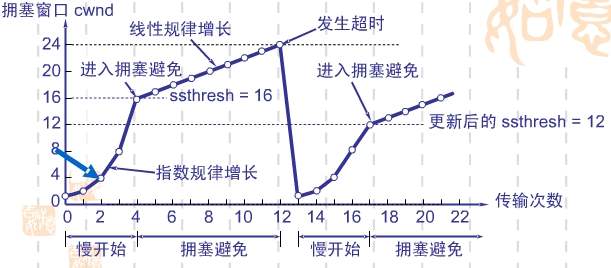
说明:由指数增长拉低到线性增长,降低出现拥塞的可能。“拥塞避免”并非指完全能够避免拥塞,利用以上的措施要完全避免网络拥塞还是不可能的。
慢开始算法只是在TCP连接建立和网络出现超时时才使用。
2.2 快重传 - (Fast Retransmission) 和 快恢复 - (Fast Recover)
基本原理:
一条TCP连接有时会因等待重传计时器的超时而空闲较长的时间,慢开始和拥塞避免无法很好的解决这类问题,因此提出了快重传和快恢复的拥塞控制方法。
为使发送方及早知道有报文段没有达到对方,快速重传算法首先要求接收方每收到一个报文段后就立即发出重复确认。快重传算法并非取消了重传机制,只是在某些情况下更早的重传丢失的报文段,即:当TCP源端收到到三个相同的ACK确认时,即认为有数据包丢失,则源端重传丢失的数据包,而不必等待 RTO(Retransmission Timeout)超时。由于发送方尽早重传未被确认的报文段,因此,采用快重传后可以使整个网络吞吐量提高约20%。
控制过程:
与快重传配合使用的还有快恢复算法,具体地:
- 当发送方连续收到三个重复确认时,执行“乘法减小”算法,慢启动门限减半,为了预防网络发生拥塞。
- 由于发送方现在认为网络很可能没有发生拥塞,因此现在不执行慢启动算法,而是把cwind值设置为慢启动门限减半后的值,然后开始执行拥塞避免算法,拥塞窗口cwind值线性增大。避免了当网络拥塞不够严重时采用”慢启动”算法而造成过大地减小发送窗口尺寸的现象。
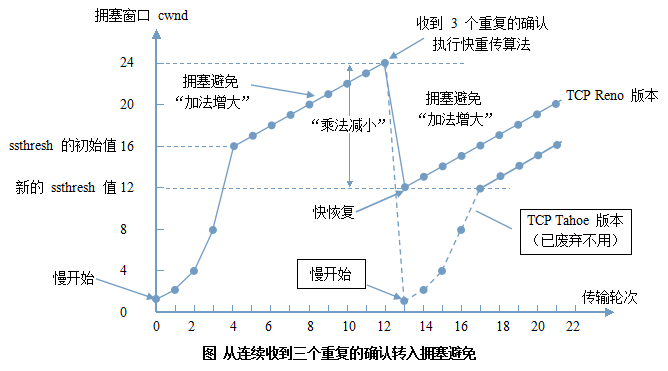
说明:新的 TCP Reno 版本在快重传之后采用快恢复算法而不是采用慢启动算法。从接收方对发送方的流量控制的角度考虑,发送方的发送窗口一定不能超过对方给出的接收窗口rwind 。
两者简单比较:
相同:提高网络性能。
不同:
[1].流量控制:采用滑动窗口机制,在TCP连接上实现对发送流量的控制,考虑点对点之间对通信量的控制,端到端,即:控制发送端的数据发送速率,使接收端可以来得及接收,保证网络高效稳定运行。
[2].拥塞控制:采用拥塞窗口机制,处理网络拥塞现象,考虑网络能够承受现有的网络负荷,全局性变量,涉及所有的路由器、主机以及与降低网络传输性能有关的因素。防止过多的数据注入到网络,使网络中的路由器或链路不致过载,确保通信子网可以有效为主机传递分组。