https://mp.weixin.qq.com/s/pmJcsRMviJZjMwlwYw6OgA
简单介绍WidthWidget的实现。

1. 基本介绍
用于设定与上游节点连接的数据总线的宽度。根据上下游数据总线宽度的大小关系,在转发消息时进行组合和拆分处理。
类参数innerBeatBytes是指与上游节点连接的数据总线所占的字节数:

2. diplomacy node
diplomacy node用于与上下游节点连接,并协商参数。
TLWidthWidget的diplomacy node是一个适配器节点:

其中:
a. clientFn:用于把TLWidthWidget看到的上游节点的参数,转换为下游节点看到的TLWidthWidget的参数;这里没有变化;
b. managerFn:用于把TLWidthWidget看到的下游节点的参数,转换为上游节点看到的TLWidthWidget节点的参数;这里把beatBytes设定为innerBeatBytes,即上游节点看到TLWidthWidget节点支持的数据总线的宽度是innerBeatBytes个字节;
3. lazy module
lazy module用于实现内部逻辑。这里主要是适配上下游节点数据总线不同导致的问题,即根据上下游数据总线宽度的大小关系,在转发消息时进行组合和拆分处理。
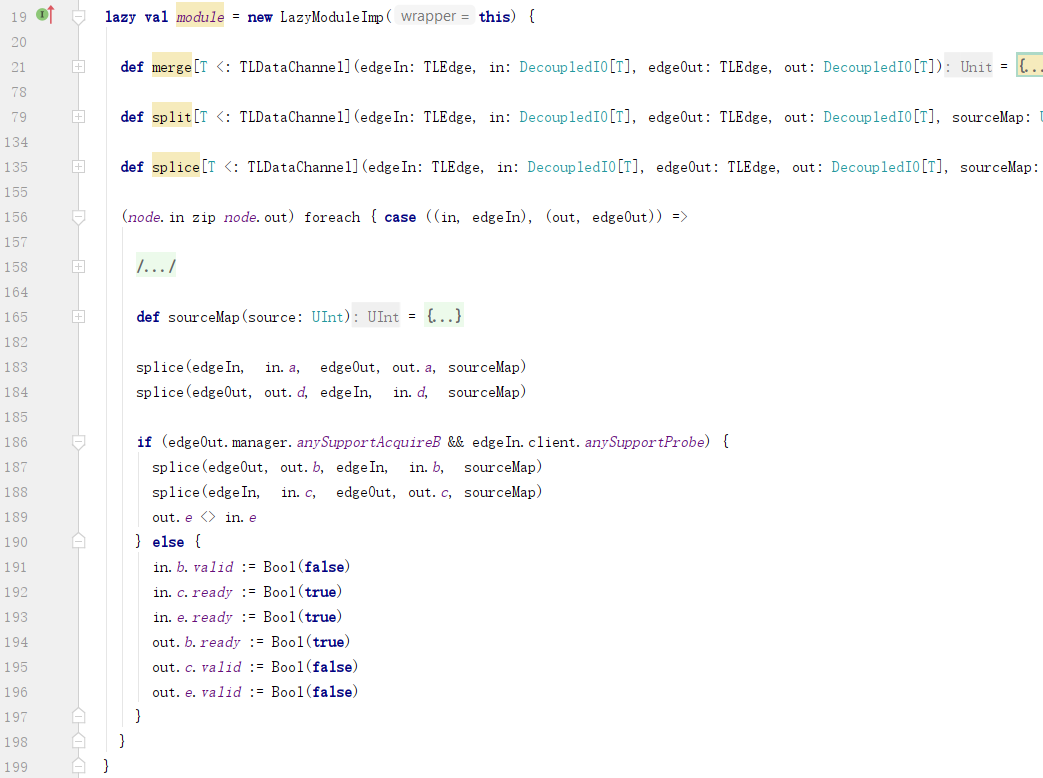
1) 成对的输入边和输出边
2) 处理channel a/d:

3) 处理channel b/c/e:
如果支持Cache,则进行组合或拆分:

4) splice
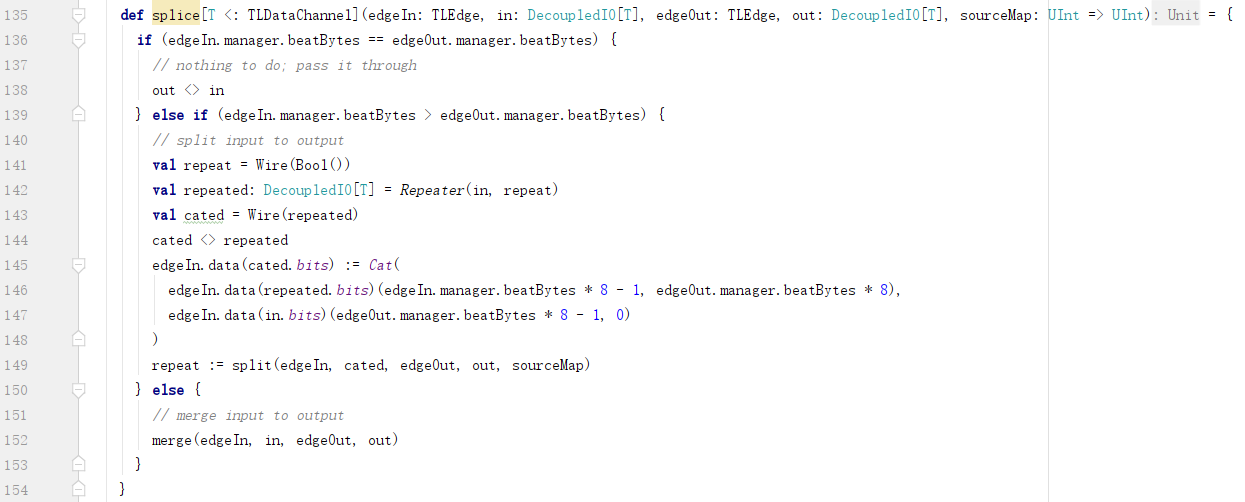
根据上下游连接数据总线宽度的大小关系,分为三种情况:
a. 相等:直连即可,无需适配;
b. 上游大:需要把请求消息拆分成多个小的分片,然后通过下游连接发出去;
c. 上游小:需要把请求消息组合成一个大的消息,然后通过下游连接发出去;
因为beatBytes需要是2的幂,所以如果上下游数据总线的宽度不相等,那么一定是整数倍的关系。
A. 总线宽度与请求的size
数据总线的宽度代表物理能力,实际请求中数据的大小由size域决定:
a. 如果size域大于数据总线宽度,则会分成多个beat而成为burst请求;
b. 如果size域小于数据总线宽度,则数据不会把数据总线占满,而需要使用mask域标识哪些字节包含数据;
所以是否组合或拆分,也由size域参与决定。如果size域比上下游数据总线宽度都小,那么就不需要组合或拆分,而可以直接透传。
B. 上游总线宽度较大

a. edgeIn.manager.beatBytes表示输入边即与上游节点连接的数据总线宽度;edgeOut.manager.beatBytes则表示下游连接的数据总线宽度;
b. repeat决定了Repeater是否重复输出保存的数据,repeat由split的结果决定;
c. cated表示上游节点输入的数据,他默认从repeater中接收数据;进而被拆分成两个部分:首先,直接从in.bits.data中取低的与下游数据总线宽度相同位宽的数据,这部分数据不需要Repeater重复;其次,从repeated中取两者总线宽度差值的数据。至于数据是否有意义,则由mask域决定;
d. repeat:如果没有把所有分片向下游发送完成,则需要repeat;如果已经发送完成则不需要repeat;如果size大小小于下游连接的总线宽度,那么可以在一个时钟周期内发送完成,也不需要repeat;
C. 上游总线宽度较小
需要把上游burst请求的多个beat合并之后,向下游发送:

如果上游是一个单beat请求,则不会等下一个单beat请求进行合并,而是直接透传。
4. merge
用于把上游burst请求的多个beat合并之后,向下游发送。

1) 基本参数
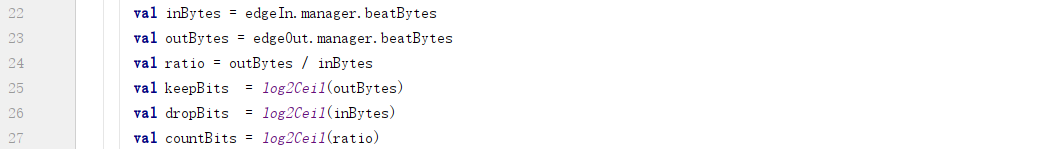
其中:
a. ratio是一个整数值(可以被除尽而没有余数);
b. countBits表示需要多少个位对用来组合的分片进行计数;
2) 请求信息

其中:limit根据当前请求的size域,计算这个请求总共包含多少个可供组合的分片;如果size也大于下游数据总线的宽度,那么这里的limit就限定在下游总线宽度。
3) first/last

其中:
a. count是用于计数的寄存器;
b. first/last表示是第一个和最后一个用于组合的beat;这里last有两种情况:第一,请求size小于下游数据总线宽度,last表示该请求的最后一个beat;第二,请求size大于下游数据总线宽度,last表示下游数据总线宽度可以容纳的最后一个beat;
c. enable是一个位图,与当前beat对应的序号为真,其他位为假;
4) corrupt
用于在多个beat之间holdcorrupt信号:

5) in.fire()
in.fire()表明来了一个请求:

a. 把count加1;
b. 如果是最后一个beat,则把count复位;单beat请求的第一个beat也就是最后一个beat;
6) ready/valid

7) edgeOut.data

a. 如果上游节点不会发起带数据的请求,如Put/Atomic等,那么可以使用默认值0;否则
b. 需要把in.bits.data组合之后装进out.bits.data;
c. out.bits.data的组合跨越了多个beat,也就是多个时钟周期;何时发出由out.valid决定;
8) out.bits.mask

a. 如果请求包含数据,则把in.bits.mask也组合在一起成为下游的mask;
b. 如果请求不包含数据,则直接使用MaskGen生成的mask;
9) helper
完成组装多beat数据的任务:

a. odata:把idata复制多份填满下游数据总线;
b. rdata:已经缓存的数据;
c. pdata:已缓存的数据 + 最后一个beat的数据;
d. mdata:enable中只有当前beat对应的位置的位为1,表示从odata中取出响应位置的idata;其他为0的位从pdata中取值;这样就逐个beat把数据存入rdata中了;
e. 把对应beat的数据存入rdata中,last为真时不需要缓存;
5. split
与merge类似,下面主要介绍不同点。
1) sel
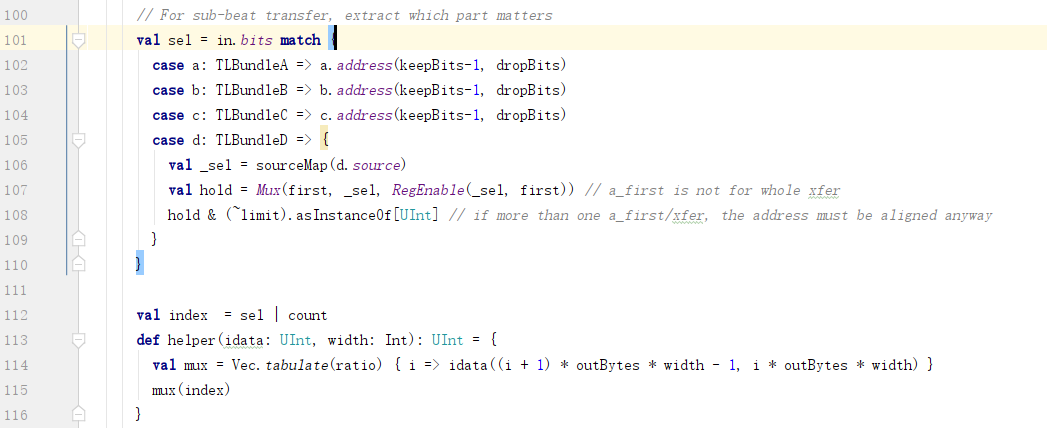
这里的sel用于从in.bits.data中定位数据的正确偏移量。
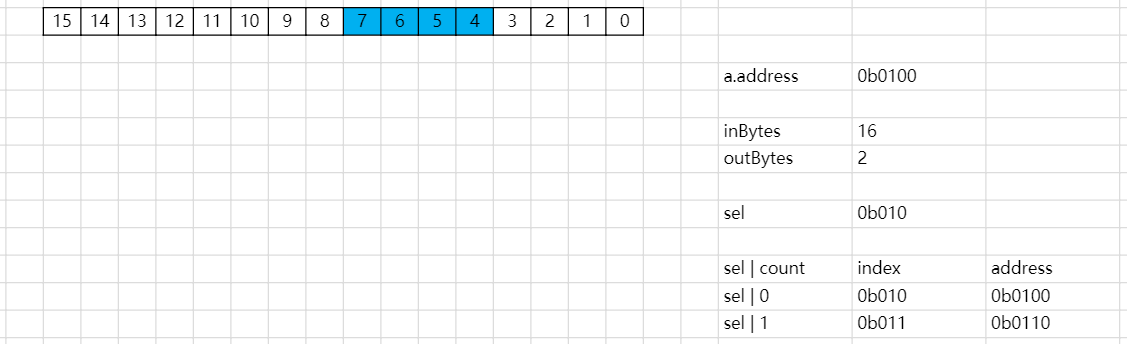
如果in.bits.data中的数据是满的,那么因为对齐的问题,sel == 0。sel | count == count,就从偏移地址0开始取in.bits.data中的数据。
如果in.bits.data中的数据不是满的,那么sel != 0。sel | count 可以定位到正确的偏移量,以从in.bits.data中取数据。下面是一个例子:
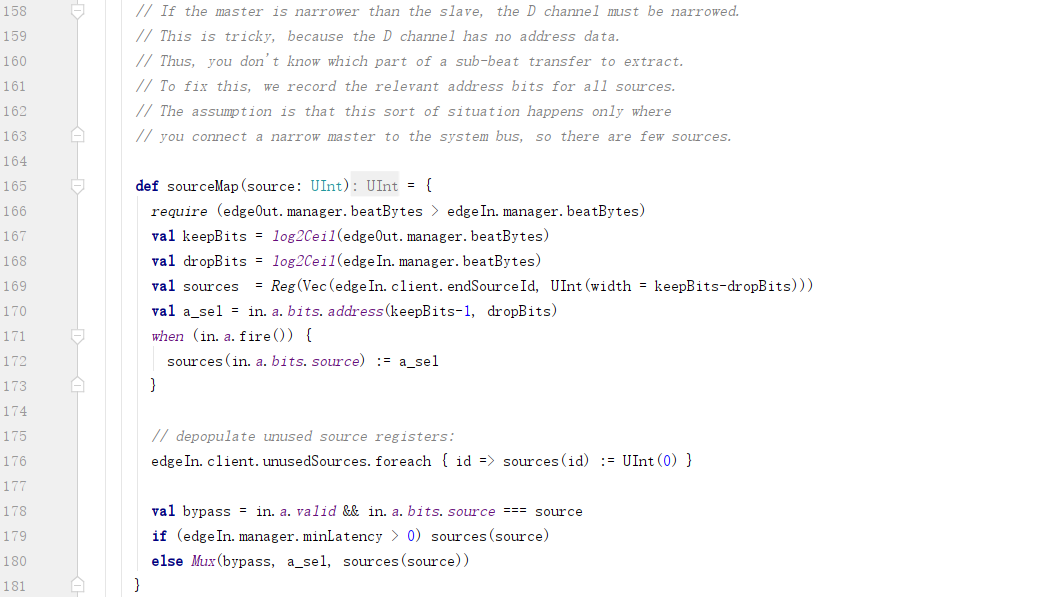
2) sourceMap
因为d中不包含address域,所以需要记录请求消息中的address域: