前面学习了决策树的算法原理,这里继续对代码进行深入学习,并学习ID3的算法实践过程,如果觉得这篇文章太乏味的话,可以直接看前一篇即可。
ID3算法是一种贪心算法,用来构造决策树,ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每一个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美的分类训练样例。
ID3算法的背景知识
ID3算法最早是由罗斯昆兰(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
ID3算法数据描述
所使用的样本数据有一定的要求,ID3是:
ID3决策树概述
ID3决策树是一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益。它通过信息增益的大小,从根节点开始,选择一个分支,如同进入一个IF结构的statement,通过属性值的取值不同进入新的IF结构的statement,直到到达叶子节点,找到它所属的“分类”标签。
它的流程图是一颗无法保证平衡的多叉树,每一个父节点都是一个判断模块,通过判断,当前的向量会进入它的某一个子节点中,这个子节点是判断模块或者终止模块(叶子节点),当且仅当这个向量到达叶子节点,它也就找到了它的“分类”标签。
ID3决策树通过一个固定的训练集是可以形成一颗永久的“树”的,这课树可以进行保存并且运用到不同的测试集中,唯一的要求就是测试集和训练集需要是结构等价的。这个训练过程就是根据训练集创建规则的过程,这也是机器学习的过程。
ID3决策树的一个巨大缺陷是:它将产生过度匹配问题。这里在不讨论信息增益的前提下,有这样一个例子:人的属性中有性别和年龄两个属性,由于人的性别只有男和女两种,年龄有很多种分支,当它有超过两个分支的时候,在用信息增益选择新的属性的时候,会选择年龄而不是性别,因为ID3决策树在使用信息增益来划分数据集的时候会倾向于选择属性分支更多的一个;另外一个缺陷是,人的年龄假定为1~100,如果不进行离散化,即区间的划分,那么在选择年龄这个属性的时候,这棵决策树会产生最多100个分支,这是非常可怕而且浪费空间和效率的,考虑这 样一种情况:两个人的其他所有属性完全相同,他们的分类都是"A",然而在年龄这一个树节点中分支了,而这个年龄下有一个跟这两个人很像,却不属于“A”类别的人,由于ID3决策树无法处理连续性数据,那么这两个人很有可能被划分到两个分类中,这是不合理的,这也是C4.5决策树考虑的问题。
ID3决策树算法推导
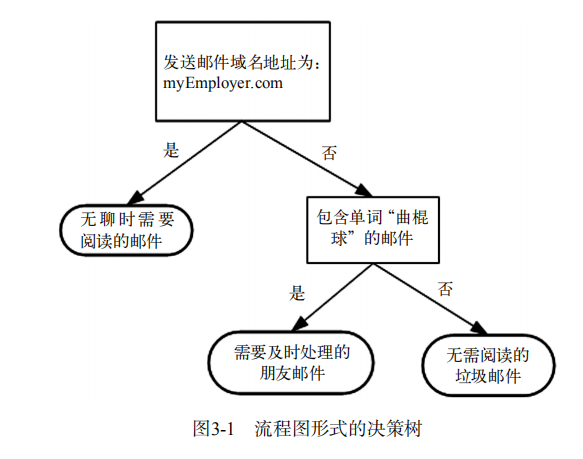
如果以前没有接触过决策树,完全不用担心,它的概念非常简单,即使不知道它也可以通过简单的图像了解其工作原理,下图就是一个决策树,正方形代表判断模型(decision block),椭圆形代表终止模块(terminating block),表示已经得出结论,可以终止运行。从判断模块引出的左右箭头称作分支(branch),它首先检测发送邮件域名地址。如果地址为myEmployer.com,则将其分类“无聊时需要阅读的邮件”中。如果邮件不是来自这个域名,则检查邮件内容里是否包含单词曲棍球,如果包含则将邮件归类到“需要及时处理的盆友邮件”,如果不包含则将邮件归类到“无需阅读的垃圾邮件”。
决策树很多任务都是为了数据中蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列的规则,机器学习算法最终将使用这些机器从数据及中创造的规则。专家系统中经常使用决策树,而且决策树给出结果往往可以匹敌在当前领域具有几十年工作经验的人类专家。
现在我们已经大致了解了决策树可以完成哪些任务,接下来我们将学习如何从一堆原始数据中构造决策树,首先我们讨论构造决策树的方法,以及如何编写决策树的Python代码;接着剔除一些度量算法成功率的方法;最后使用递归建立分类器,并且使用Matplotlib绘制决策树图,构造完成决策树分类器之后,我们将输入一些隐形眼镜的处方数据,并由决策树分类器预测需要的镜片类型。
1,决策树的构造
在一步步地构造决策树算法的时候,首先我们讨论数学上如何使用信息论划分数据集,然后编写代码将理论应用到具体的数据集上,最后编写代码构建决策树。
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集,这些数据子集会分布在第一个决策点的所有分支上,如果某个分支下的数据属于同一类型,则当前无需阅读的垃圾邮件已经正确的划分数据分类,无需进一步对数据集进行分割,如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程,如何划分数据子集的算法和划分原始数据集的方法相同,知道所有具有相同类型的数据均在一个数据子集内。
创建分支的伪代码函数createBranch() 如下所示:
检测数据集中的每个子项是否属于同一分类:
If so retrun 类标签;
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return 分支节点
上面的伪代码createBranch是一个递归函数,在倒数第二行直接调用了它自己,后面我们将把上面的伪代码转换为Python代码,这里我们需要了解一下算法是如何划分数据集的。
1.1 决策树的一般流程
- (1) 收集数据:可以使用任何方法
- (2) 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
- (3) 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图像是否符合预期
- (4) 训练算法:构造树的数据结构
- (5) 测试算法:使用经验树计算错误率
- (6)使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好的理解数据的内在含义
1.2 划分特征
一些决策树算法采用二分法划分数据,此处不采用这种方法,本次将使用ID3算法划分数据集,该算法处理如何划分数据集,何时停止划分数据集。如果依据某个属性划分数据将会产生4个可能的值,我们将数据划分为四块,并创建四个不同的分支,每次划分数据集时我们只选取一个特征属性,如果训练集中存在20个特征,第一次我们选择哪个特征作为划分的参考属性呢?
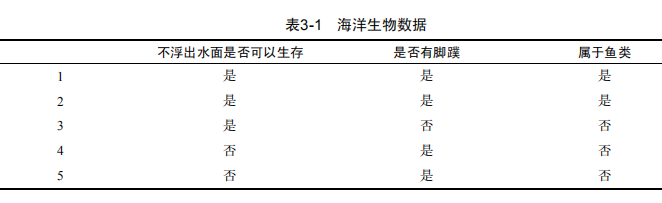
下表的数据包含5个海洋动物,特征包括:不浮出水面是否可以生存,以及是否有脚趾。我们可以将这些动物划分为两类:鱼类和非鱼类,现在我们想要决定依据第一个特征还是第二个特征划分数据,那么那个特征可以作为第一个划分点呢?让我们继续学习。
1.3 信息增益
划分数据集的大原则是:将无序的数据变得更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化成为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测哪种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵(这名字来源于信息论之父克劳德*香农)
熵定义为信息的期望值,在明白这个概念之前,我们必须知道信息的定义,如果待分类的事务可能划分在多个分类之中,则符号Xi的信息定义为:
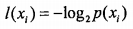
其中P(Xi)是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
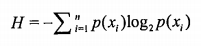
其中n是分类的数目。
代码如下:
此代码是使用Python计算给定数据集的信息熵。
from math import log
# 计算数据的熵(entropy)
def calcShannonRnt(dataSet):
# 数据条数,计算数据集中实例的总数
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
# 每行数据的最后一个类别(也就是标签)
currentLable = featVec[-1]
if currentLable not in labelCounts.keys():
labelCounts[currentLable] = 0
# 统计有多少个类以及每个类的数量
labelCounts[currentLable] += 1
shannonEnt = 0.0
for key in labelCounts:
# 计算单个类的熵值
prob = float(labelCounts[key]) / numEntries
# 累加每个类的熵值
shannonEnt -= prob * log(prob , 2)
return shannonEnt
下面我们创建一个简单的数据集(此处我们使用机器学习实战中的简单鱼鉴定数据集):
# 创建数据集
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
return dataSet,labels
代码执行结果:
myData,labels = createDataSet() print(myData) print(labels) shannonEnt = calcShannonRnt(myData) print(shannonEnt) ''' [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] ['no surfacing', 'flippers'] 0.9709505944546686 '''
从结果来看,熵为0.97,熵越高,则混合的数据也越多,随机变量的不确定性越大,我们可以在数据集中添加更多的分类,观察熵是如何变化的。
2,划分数据集
上面我们学习了如何度量数据集的无序程度,分类算法除了需要测量信息熵,还需要划分数据集,度量划分数据集的熵,以便判断当前是否正确地划分了数据集,我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。想象一个分布在二维空间的数据散点图,需要在数据之间画条线,将他们分成两部分,我们应该按照x轴还是y轴划分呢?
按照给定特征划分数据集代码:
# 按照给定特征划分数据集
def splitDataSet(dataSet,axis,value):
'''
:param dataSet: 待划分的数据集
:param axis: 划分数据集的特征
:param value: 特征的返回值
:return:
'''
retDataSet = []
for featVec in dataSet:
# 如果发现符合要求的特征,将其添加到新创建的列表中
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
我们使用划分数据集测试一下,可以看到划分数据集结果如下:
myData,labels = createDataSet() print(myData) print(labels) splitDataSetVal = splitDataSet(myData,0,1) print(splitDataSetVal) splitDataSetVal = splitDataSet(myData,0,0) print(splitDataSetVal) ''' [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] ['no surfacing', 'flippers'] [[1, 'yes'], [1, 'yes'], [0, 'no']] [[1, 'no'], [1, 'no']] '''
接下来,我们将遍历整个数据集,循环计算香农熵和splitDataSet()函数,找到最好的特征划分方式,熵计算将会告诉我们如何划分数据集是最好的数据组织方式。
选择最好的数据集划分方式代码:
# 选择最好的数据集划分方式
def chooseBestFeatureTpSplit(dataSet):
'''
此函数中调用的数据满足以下要求
1,数据必须是一种由列表元素组成的列表,而且所有列表元素都要具有相同的数据长度
2,数据的最后一列或者实例的最后一个元素是当前实例的类别标签
:param dataSet:
:return:
'''
numFeatures = len(dataSet[0]) - 1
# 原始的熵
baseEntropy = calcShannonRnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 计算每种划分方式的信息熵,并对所有唯一特征值得到的熵求和
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
# 按照特征分类后的熵
newEntropy += prob * calcShannonRnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
# 计算最好的信息增益,信息增益越大,区分样本的能力越强,根据代表性
bestInfoGain = infoGain
bestFeature = i
return bestFeature
测试代码,得到结果:
myData,labels = createDataSet() print(myData) print(labels) bestFeatureRes = chooseBestFeatureTpSplit(myData) print(bestFeatureRes) ''' [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] ['no surfacing', 'flippers'] 0 '''
结果告诉我们第0个特征是最好的用于划分数据集的特征。如果按此特征分类,第一个海洋动物分组将有两个属于鱼类,两个属于非鱼类,另一个分组则只有一个非鱼类。
假设我们按照第一个特征属性划分数据,也就是说第一个特征是1的放在一个组,第一个特征是0的放在另一个组,数据一致性如何?按照上述的方法划分数据集,第一个特征为1的海洋生物分组将有两个属于鱼类,一个属于非鱼类;另一个分组则全部属于非鱼类。
3 递归构建决策树
总结一下构建决策树的工作原理:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据将向下传递到树分支的下一个节点,在这个节点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点护着终止块。任何到达叶子节点的数据必然属于叶子节点的分类,参见下图:
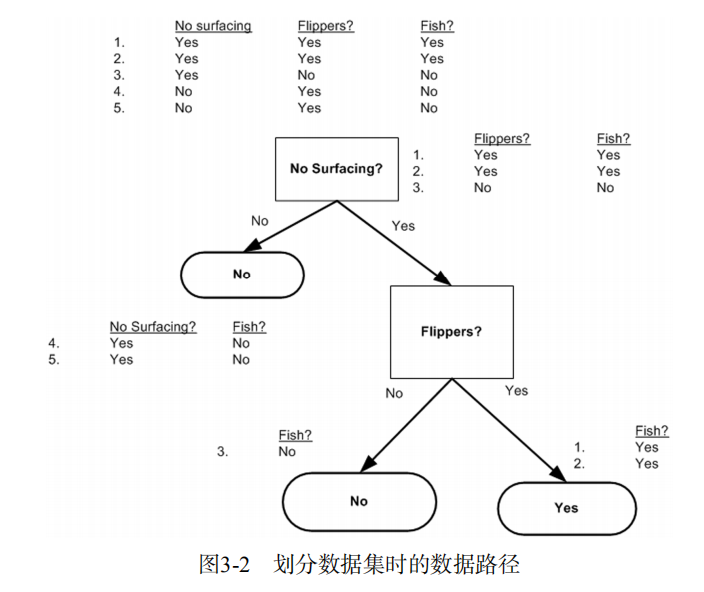
第一个结束条件使得算法可以终止,我们甚至可以设置算法可以划分的最大分组数目。当然目前我们只需要在算法开始运行前计算列的数目,查看算法是否使用了所有属性即可,如果数据集已经处理了所有属性,但是类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常会采用多数表决的方法决定该叶子节点的分类。
按照分类后类别数量排序代码:
# 按照分类后类别数量排序
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
创建树的函数代码:
# 创建树的函数代码
def createTree(dataSet,labels):
'''
:param dataSet: 输入的数据集
:param labels: 标签列表(包含了数据集中所有特征的标签)
:return:
'''
# classList 包含了数据集中所有类的标签
classList = [example[-1] for example in dataSet]
# 类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 遍历完所有特征时返回出现次数最多的
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureTpSplit(dataSet)
bestFeatLabel = labels[bestFeat]
# 字典myTree存储了树的所有信息,这对于后面绘制树形图很重要
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 得到列表包含的所有属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels =labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),
subLabels)
运行代码结果如下:
myData,labels = createDataSet()
print(myData)
print(labels)
myTree = createTree(myData,labels)
print(myTree)
'''
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
['no surfacing', 'flippers']
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
'''
从结果来看,变量myTree包含了很多代表树结构信息的嵌套字典,从左边开始,第一次关键字nosurfacing是第一个划分数据集的特征名称,该关键字的值也是另一个数据字典,第二个关键字是no surfacing特征划分的数据集,这些关键字的值时no surfacing节点的子节点,这些值可能是类标签,也可能是另一个数据字典,如果值时类标签,则该子节点是叶子节点;如果值时另一个数据字典,则子节点是一个判断节点,这种格式结构不断重复就构成了整棵树。
4 使用Matplotlib注解绘制树形图
上面我们学习了如何从数据集中创建树,然而字典的表示形式非常不易于理解,而且直接绘制图形也比较困难,这里我们学习使用Matplotlib库创建树形图。决策树的主要优点就是直观易于理解,如果不能将其直观的显示出来,就无法发挥其优势。
Matplotlib可以对文字着色并提供多种形状以供选择,而且我们还可以反转箭头,将它指向文本框而不是数据点。
使用文本注解绘制树节点代码:
import matplotlib.pyplot as plt
# 定义文本框和箭头格式(树节点格式的常量)
decisionNode = dict(boxstyle='sawtooth',fc='0.8')
leafNode = dict(boxstyle='round4',fc='0.8')
arrows_args = dict(arrowstyle='<-')
# 绘制带箭头的注解
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
createPlot.ax1.annotate(nodeTxt,xy=parentPt,
xycoords='axes fraction',
xytext=centerPt,textcoords='axes fraction',
va='center',ha='center',bbox=nodeType,
arrowprops=arrows_args)
def createPlot():
# 创建一个新图形并清空绘图区
fig = plt.figure(1,facecolor='white')
fig.clf()
createPlot.ax1 = plt.subplot(111,frameon=False)
plotNode('a decision node',(0.5,0.1),(0.1,0.5),decisionNode)
plotNode('a leaf node',(0.8,0.1),(0.3,0.8),leafNode)
plt.show()
if __name__ == '__main__':
createPlot()
结果:

5 构造决策树
绘制一颗完整的树需要一些技巧。我们虽然有x,y坐标,但是如何放置所有的树节点却是个问题,我们必须知道有多少个叶子节点,以便可以正确确定x轴的长度我们还需要知道树有多少层,以便可以正确确定y轴的高度,这里我们定义两个新函数getNumLeafs() 和getTreeDepth(),来获取叶节点数目和树的层数,如下:
获取叶子节点的数目和树的层数代码:
import matplotlib.pyplot as plt
def myTree():
treeData = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
return treeData
# 获取叶子节点的数目
def getNumLeafs(myTree):
# 初始化结点数
numLeafs = 0
firstSides = list(myTree.keys())
# 找到输入的第一个元素,第一个关键词为划分数据集类别的标签
firstStr = firstSides[0]
secondDect = myTree[firstStr]
for key in secondDect.keys():
# 测试节点的数据类型是否为字典
if type(secondDect[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDect[key])
else:
numLeafs +=1
return numLeafs
# 获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstSides = list(myTree.keys())
firstStr = firstSides[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
# 测试节点的数据类型是否为字典
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
if __name__ == '__main__':
myData = myTree()
LeafNum = getNumLeafs(myData)
TreeDepth = getTreeDepth(myData)
print(LeafNum)
print(TreeDepth)
测试结果如下:
3 2
下面我们将前面的方法组合在一起,得到决策树,此时我们需要更新画图的代码:
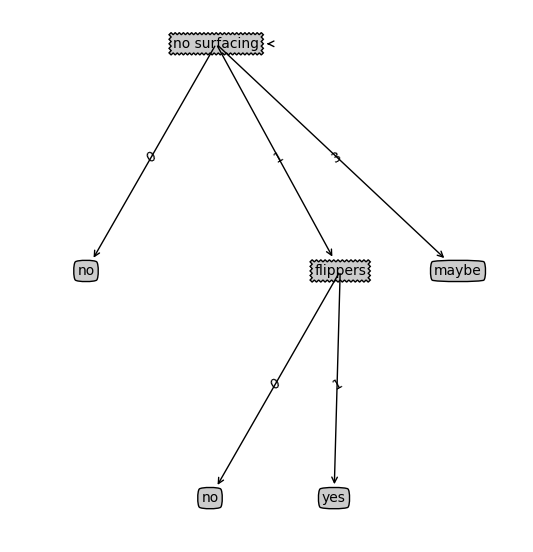
完整代码如下:
import matplotlib.pyplot as plt
# 定义文本框和箭头格式(树节点格式的常量)
decisionNode = dict(boxstyle='sawtooth',fc='0.8')
leafNode = dict(boxstyle='round4',fc='0.8')
arrows_args = dict(arrowstyle='<-')
# 绘制带箭头的注解
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
createPlot.ax1.annotate(nodeTxt,xy=parentPt,
xycoords='axes fraction',
xytext=centerPt,textcoords='axes fraction',
va='center',ha='center',bbox=nodeType,
arrowprops=arrows_args)
# 在父子节点间填充文本信息
def plotMidText(cntrPt,parentPt,txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid,yMid,txtString, va="center", ha="center", rotation=30)
def plotTree(myTree,parentPt,nodeTxt):
# 求出宽和高
numLeafs = getNumLeafs(myData)
depth = getTreeDepth(myData)
firstStides = list(myTree.keys())
firstStr = firstStides[0]
# 按照叶子结点个数划分x轴
cntrPt = (plotTree.xOff + (0.1 + float(numLeafs)) /2.0/plotTree.totalW,plotTree.yOff)
plotMidText(cntrPt,parentPt,nodeTxt)
plotNode(firstStr,cntrPt,parentPt,decisionNode)
secondDict = myTree[firstStr]
# y方向上的摆放位置 自上而下绘制,因此递减y值
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW # x方向计算结点坐标
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) # 绘制
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) # 添加文本信息
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD # 下次重新调用时恢复y
def myTree():
treeData = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
return treeData
# 获取叶子节点的数目
def getNumLeafs(myTree):
# 初始化结点数
numLeafs = 0
firstSides = list(myTree.keys())
# 找到输入的第一个元素,第一个关键词为划分数据集类别的标签
firstStr = firstSides[0]
secondDect = myTree[firstStr]
for key in secondDect.keys():
# 测试节点的数据类型是否为字典
if type(secondDect[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDect[key])
else:
numLeafs +=1
return numLeafs
# 获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstSides = list(myTree.keys())
firstStr = firstSides[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
# 测试节点的数据类型是否为字典
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
# 主函数
def createPlot(inTree):
# 创建一个新图形并清空绘图区
fig = plt.figure(1,facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
if __name__ == '__main__':
myData = myTree()
myData['no surfacing'][3] = 'maybe'
print(myData)
# LeafNum = getNumLeafs(myData)
# TreeDepth = getTreeDepth(myData)
# print(LeafNum)
# print(TreeDepth)
createPlot(myData)
6 测试算法:使用决策树执行分类
依靠训练数据构造了决策树之后,我们可以将它用于实际数据的分类,在执行数据分类时,需要决策树以及用于构造树的标签向量。然后,程序比较测试数据与决策树上的数值,递归执行该过程直到进入叶子节点,最后将测试数据定义为叶子节点所属的类型。
使用决策树的分类函数代码:
from math import log
import operator
# 计算数据的熵(entropy)
def calcShannonRnt(dataSet):
# 数据条数,计算数据集中实例的总数
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
# 每行数据的最后一个类别(也就是标签)
currentLable = featVec[-1]
if currentLable not in labelCounts.keys():
labelCounts[currentLable] = 0
# 统计有多少个类以及每个类的数量
labelCounts[currentLable] += 1
shannonEnt = 0.0
for key in labelCounts:
# 计算单个类的熵值
prob = float(labelCounts[key]) / numEntries
# 累加每个类的熵值
shannonEnt -= prob * log(prob , 2)
return shannonEnt
# 创建数据集
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing','flippers']
# dataSet = [['Long', 'Think', 'male'],
# ['Short', 'Think', 'male'],
# ['Short', 'Think', 'male'],
# ['Long', 'Thin', 'female'],
# ['Short', 'Thin', 'female'],
# ['Short', 'Think', 'female'],
# ['Long', 'Think', 'female'],
# ['Long', 'Think', 'female']]
# labels = ['hair', 'voice']
return dataSet,labels
# 按照给定特征划分数据集
def splitDataSet(dataSet,axis,value):
'''
:param dataSet: 待划分的数据集
:param axis: 划分数据集的特征
:param value: 特征的返回值
:return:
'''
retDataSet = []
for featVec in dataSet:
# 如果发现符合要求的特征,将其添加到新创建的列表中
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
# 选择最好的数据集划分方式
def chooseBestFeatureTpSplit(dataSet):
'''
此函数中调用的数据满足以下要求
1,数据必须是一种由列表元素组成的列表,而且所有列表元素都要具有相同的数据长度
2,数据的最后一列或者实例的最后一个元素是当前实例的类别标签
:param dataSet:
:return:
'''
numFeatures = len(dataSet[0]) - 1
# 原始的熵
baseEntropy = calcShannonRnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 计算每种划分方式的信息熵,并对所有唯一特征值得到的熵求和
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
# 按照特征分类后的熵
newEntropy += prob * calcShannonRnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
# 计算最好的信息增益,信息增益越大,区分样本的能力越强,根据代表性
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 按照分类后类别数量排序
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
# 创建树的函数代码
def createTree(dataSet,labels):
'''
:param dataSet: 输入的数据集
:param labels: 标签列表(包含了数据集中所有特征的标签)
:return:
'''
# classList 包含了数据集中所有类的标签
classList = [example[-1] for example in dataSet]
# 类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 遍历完所有特征时返回出现次数最多的
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureTpSplit(dataSet)
bestFeatLabel = labels[bestFeat]
# 字典myTree存储了树的所有信息,这对于后面绘制树形图很重要
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 得到列表包含的所有属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels =labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),
subLabels)
return myTree
# 使用决策树的分类函数
def classify(inputTree ,featLabels,testVec):
firstSides = list(inputTree.keys())
firstStr = firstSides[0]
secondDict = inputTree[firstStr]
# print('featLables:',featLabels)
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
# 若该特征值等于当前key,yes往下走
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel
#使用决策树来分类
def classify11(inputTree,featLabels,testVec):
#python3.X
firstSides = list(inputTree.keys())
firstStr = firstSides[0] # 找到输入的第一个元素
# python3.X
secondDict=inputTree[firstStr] #baocun在secondDict中
featIndex=featLabels.index(firstStr) #建立索引
for key in secondDict.keys():
if testVec[featIndex]==key: #若该特征值等于当前key,yes往下走
if type(secondDict[key]).__name__=='dict':# 若为树结构
classLabel=classify(secondDict[key],featLabels,testVec) #递归调用
else: classLabel=secondDict[key]#为叶子结点,赋予label值
return classLabel #分类结果
def retrieveTree(i):
listOfTrees = [
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head':{0:'no', 1: 'yes'}},1:'no'}}}}
]
return listOfTrees[i]
测试结果如下:
if __name__ == '__main__':
myData,labels = createDataSet()
# print(myData)
# print(labels)
myTree = createTree(myData,labels)
# print(myTree0)
myTree1 = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
# print(type(myTree1))
# myTree = retrieveTree(0)
myData, labels = createDataSet()
print(myData)
print(labels)
res1 = classify(myTree,labels,[1,1])
print(res1)
res2 = classify(myTree,labels,[1,0])
print(res2)
'''
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
['no surfacing', 'flippers']
yes
no
'''
7 使用算法:决策树的存储
构造决策树是很耗时的任务,即使处理很小的数据集,如前面的样本数据,也要花费几秒的时间,如果数据集很大,将会耗费很多计算时间,然而使用创建好的决策树解决问题,则可以很快完成。所以为了节省时间,最好能够在每次执行分类时调用已经构造好的决策树,为了解决这个问题,需要使用pickle序列化对象。序列化对象可以在磁盘上保存对象,并在需要的时候读取出来,任何对象都可以执行序列化操作,字典对象也不例外。
使用pickle模块存储决策树代码:
# 使用pickle模块存储决策树
def storeTree(inputTree,filename):
import pickle
fw =open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename,'rb')
return pickle.load(fr)
通过上面的代码,我们可以将分类器存储在硬盘上,而不是每次对数据分类时重新学习一边,这就是决策树的优点之一。
验证上面代码,测试结果如下:
if __name__ == '__main__':
myData,labels = createDataSet()
myTree = createTree(myData,labels)
print(myTree)
print(type(myTree))
myTree1 = {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
storeTree(myTree1,'classifierStorage.txt')
res = grabTree('classifierStorage.txt')
print(res)
'''
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
<class 'dict'>
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
'''
8 示例:使用决策树预测隐形眼镜类型
此处通过一个例子学习决策树如何预测患者需要佩戴的隐形眼镜类型,使用小数据集,我们就可以利用决策树学到很多知识:眼科医生是如何判断患者需要佩戴的镜片类型;
(隐形眼镜数据集时非常著名的数据集,它包含很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型,隐形眼镜类型包括硬材质,软材质以及不适合佩戴隐形眼镜。数据来源于UCI数据库,为了更容易显示数据,机器学习实战将数据做了简单的更改,数据存储在文本文件中)
lenses.txt内容可以去我的GitHub上拿(GitHub地址:https://github.com/LeBron-Jian/MachineLearningNote)
程序如下:
# _*_coding:utf-8_*_
import operator
from math import log
import matplotlib.pyplot as plt
# 计算香农熵 度量数据集无序程度
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for fearVec in dataSet:
currentLabel = fearVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob,2)
return shannonEnt
# 划分数据集
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducesFeatVec = featVec[:axis]
reducesFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducesFeatVec)
return retDataSet
# 选择最好的数据集划分方式
def chooseBestFeatureTpSplit(dataSet):
'''
此函数中调用的数据满足以下要求
1,数据必须是一种由列表元素组成的列表,而且所有列表元素都要具有相同的数据长度
2,数据的最后一列或者实例的最后一个元素是当前实例的类别标签
:param dataSet:
:return:
'''
numFeatures = len(dataSet[0]) - 1
# 原始的熵
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# 计算每种划分方式的信息熵,并对所有唯一特征值得到的熵求和
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
# 按照特征分类后的熵
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
# 计算最好的信息增益,信息增益越大,区分样本的能力越强,根据代表性
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# 按照分类后类别数量排序
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
# 创建树的函数代码
def createTree(dataSet,labels):
'''
:param dataSet: 输入的数据集
:param labels: 标签列表(包含了数据集中所有特征的标签)
:return:
'''
# classList 包含了数据集中所有类的标签
classList = [example[-1] for example in dataSet]
# 类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 遍历完所有特征时返回出现次数最多的
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureTpSplit(dataSet)
bestFeatLabel = labels[bestFeat]
# 字典myTree存储了树的所有信息,这对于后面绘制树形图很重要
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 得到列表包含的所有属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels =labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),
subLabels)
return myTree
# 获取叶子节点的数目
def getNumLeafs(myTree):
# 初始化结点数
numLeafs = 0
firstSides = list(myTree.keys())
# 找到输入的第一个元素,第一个关键词为划分数据集类别的标签
firstStr = firstSides[0]
secondDect = myTree[firstStr]
for key in secondDect.keys():
# 测试节点的数据类型是否为字典
if type(secondDect[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDect[key])
else:
numLeafs +=1
return numLeafs
# 获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstSides = list(myTree.keys())
firstStr = firstSides[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
# 测试节点的数据类型是否为字典
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
# 定义文本框和箭头格式(树节点格式的常量)
decisionNode = dict(boxstyle='sawtooth',fc='0.8')
leafNode = dict(boxstyle='round4',fc='0.8')
arrows_args = dict(arrowstyle='<-')
# 绘制带箭头的注解
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
createPlot.ax1.annotate(nodeTxt,xy=parentPt,
xycoords='axes fraction',
xytext=centerPt,textcoords='axes fraction',
va='center',ha='center',bbox=nodeType,
arrowprops=arrows_args)
# 在父子节点间填充文本信息
def plotMidText(cntrPt,parentPt,txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid,yMid,txtString, va="center", ha="center", rotation=30)
def plotTree(myTree,parentPt,nodeTxt):
# 求出宽和高
numLeafs = getNumLeafs(myData)
depth = getTreeDepth(myData)
firstStides = list(myTree.keys())
firstStr = firstStides[0]
# 按照叶子结点个数划分x轴
cntrPt = (plotTree.xOff + (0.1 + float(numLeafs)) /2.0/plotTree.totalW,plotTree.yOff)
plotMidText(cntrPt,parentPt,nodeTxt)
plotNode(firstStr,cntrPt,parentPt,decisionNode)
secondDict = myTree[firstStr]
# y方向上的摆放位置 自上而下绘制,因此递减y值
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW # x方向计算结点坐标
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) # 绘制
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) # 添加文本信息
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD # 下次重新调用时恢复y
# 主函数
def createPlot(inTree):
# 创建一个新图形并清空绘图区
fig = plt.figure(1,facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()
if __name__ == '__main__':
fr = open('lenses.txt')
lenses = [inst.strip().split(' ') for inst in fr.readlines()]
lensesLabels = ['age','prescript','astigmatic','tearRate']
print(lenses)
myData = createTree(lenses, lensesLabels)
print(myData)
createPlot(myData)
结果如下:
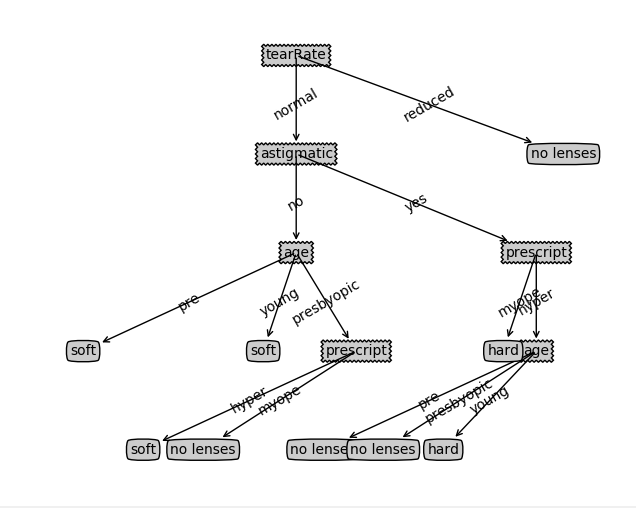
上图所示的决策树非常好的匹配了实验数据,然而这些选项可能太多了。我们将这种问题称为过度匹配,为了减少过度匹配问题,我们可以裁剪决策树,去掉一些不必要的叶子节点,如果叶子节点只能增加少许信息,则可以删除该节点,将它并入到其他叶子节点中。
ID3算法无法直接处理数值型数据,尽管我们可以通过量化的方法将数值型数据转化为标称型数值,但是如果存在太多的特征划分,ID3算法仍然会面临其他问题。
9 总结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。开始处理数据集时,我们首先需要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。ID3算法可以用于划分标称型数据集。构建决策树时,我们通常采取递归的方法将数据集转化为决策树。一般我们并不构造新的数据结构,而是使用字典存储树节点信息。
完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
参考文献:机器学习实战