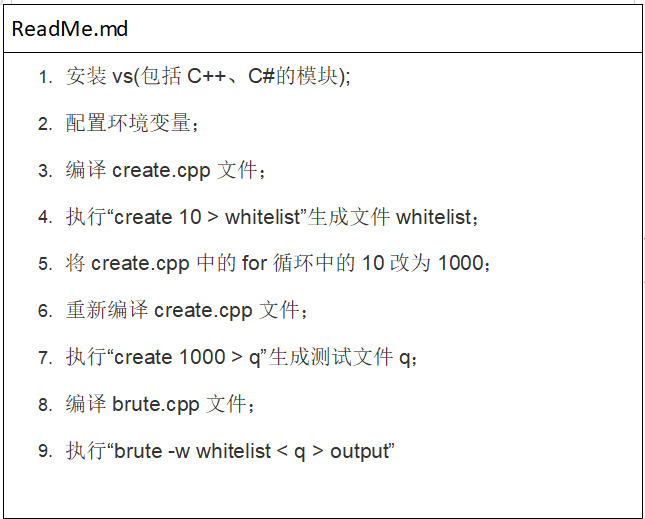
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11207
此次作业首先要感谢李思源同学对我在使用vs过程中的细心帮助。
作业0(5分)
修改create.cpp文件,改成由命令行参数确定生成的数据的数据量。修改readme.md的对应部分。(要求贴出修改之后的代码和read.md。)
修改后的代码,查找了atoi()函数的用法
//create.cpp
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main(int argc, char* argv[])
{
int num = atoi(argv[1]);
//atoi()函数将数字格式的字符串转换为整数类型
srand((unsigned)time(NULL));
for (int i = 0; i < num; i++)
{
cout << rand()<< "
";
}
cout << endl;
return 0;
}
作业1(10分)
对上面两段老杨写的代码任选其一进行profile,观察现象(要求有截图记录)。
你是一个好人,为了让老杨知道为什么要对代码进行profile,于是你在原来的题目的基础上做出了修改,修改之后的题要求如下:
1) 读入两个文件,一个用控制台,一个用命令行参数指出文件名。
文件 biggerwhitelist,包含1列整数1M个,随机生成(要求老杨自己想办法),通过命令行参数指出文件名。
文件 biggerq,包含1列整数10M个,随机生成(也要求老杨自己想办法),通过控制台读入。
2) 在文件biggerq中查找所有不在biggerwhitelist中的整数,重定向输出到一个文件中。
3) 写一份如何部署运行代码的readme。
我是用的是vs2019版本 选择对C++代码进行profile
执行完成的结果如下图
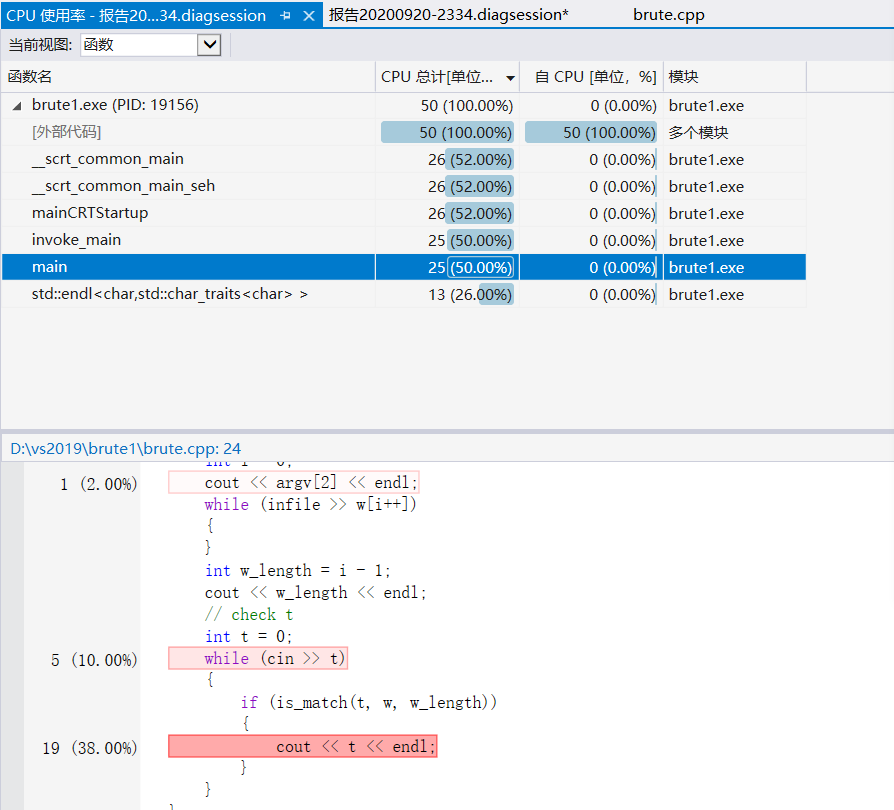
由于上几个部分的占比几乎相差不多无法做出判断,所以我得出的结论是main函数所占用的时间比较多,并点开代码行发现是对于数据的输出部分占的百分比最大。
1) 读入两个文件,一个用控制台,一个用命令行参数指出文件名。
文件 biggerwhitelist,包含1列整数1M个,随机生成(要求老杨自己想办法),通过命令行参数指出文件名。

文件 biggerq,包含1列整数10M个,随机生成(也要求老杨自己想办法),通过控制台读入

2) 在文件biggerq中查找所有不在biggerwhitelist中的整数,重定向输出到一个文件中。

3) 写一份如何部署运行代码的readme。

作业2(10分)
以biggerwhitelist和biggerq作为输入,对作业1中选择的代码再次进行profile,找到代码执行最“慢”的地方,截图为证并文字说明。
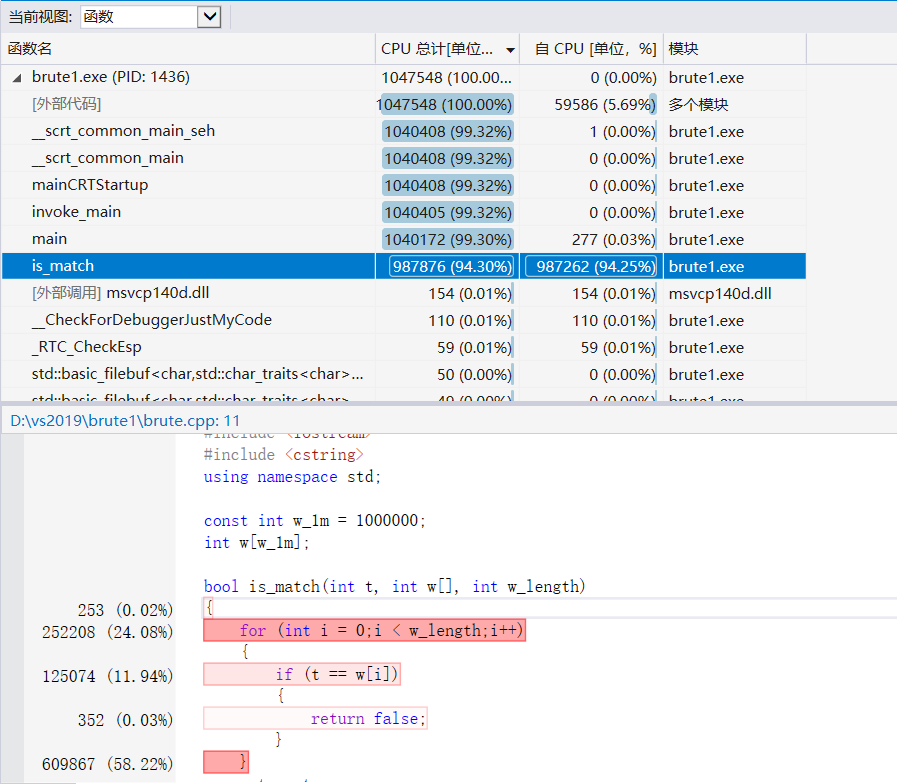
profile大的数据以后发现了问题的所在不是输出的问题,而是ismatch的复杂度太高,导致占用了大量的空间。
作业3(10分)
根据作业2找到的最慢的地方,优化作业1中你选择的代码,在保证输出结果正确的前提下,减少老杨程序运行的时间。(优化后的代码需要你提交到git上,作为教师的判断依据。优化后的程序的名字应该是better.cpp或者better.cs。)
//better.cpp
#include <algorithm>
#include <fstream>
#include <iostream>
#include <cstring>
using namespace std;
const int w_1m = 1000000;
int w[w_1m];
bool binarysearch(int t, int low,int high)
{
int mid;
mid = (high + low) / 2;
//对排序后的有序数据进行二分查找
if (w[mid] == t)
{
return false;
}
else if (low >= high)
{
return 1;
}
else if (w[mid] > t)
{
return binarysearch(t,low, mid - 1);
}
else if (w[mid] < t)
{
return binarysearch(t,mid + 1, high);
}
return true;
}
// brute -w whitelist < T
int main(int argc, char* argv[])
{
if (argc != 3 || strcmp(argv[1], "-w"))
{
return 1;
}
// init w
//// for(int i=0;i<w_1m)
//// {
//// w[i]=-1; //填充非法数据
//// }
ifstream infile;
infile.open(argv[2]);
int i = 0;
cout << argv[2] << endl;
while (infile >> w[i++])
{
}
int w_length = i - 1;
cout << w_length << endl;
// check t
int t = 0;
sort (w, w + w_length);
//对w中的数据进行排序
while (cin >> t)
{
if (binarysearch(t, 0, w_length))
{
cout << t << endl;
}
}
}
代码地址:https://mochi0828.coding.net/public/profile/better/git/files
作业4(5分)
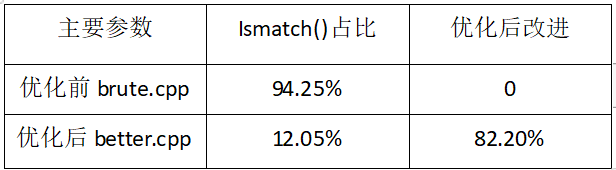
对作业3优化后的代码进行profile,结果与作业2的结果做对比。画表格并文字说明。
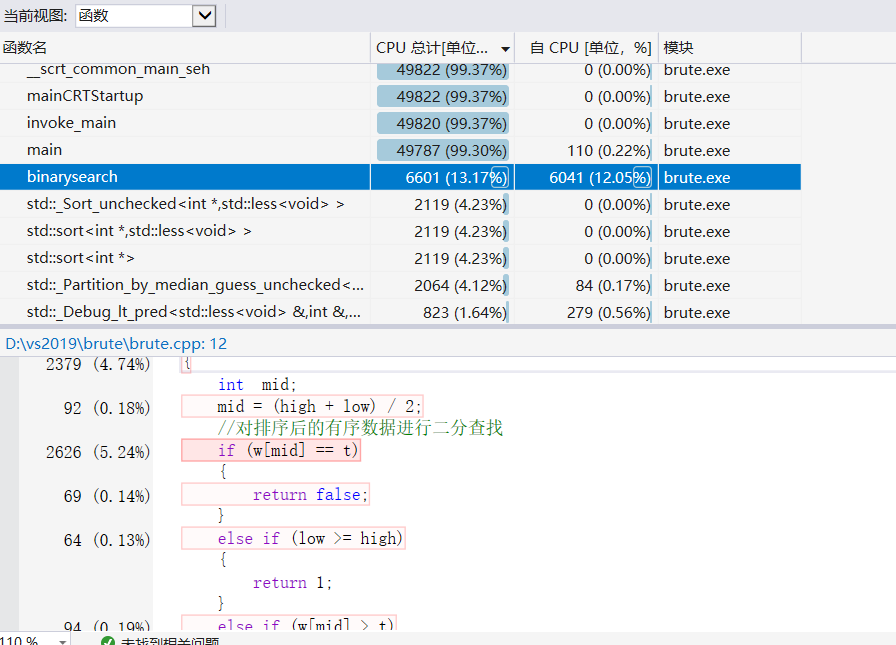
优化后的代码再次进行了profile 通过排序后递归的进行二分查找 降低复杂度至log n也加快了时间。
做业5(5分)
你觉得老杨的文档(readme),注释和代码风格又哪些问题,该如何改进?
首先我觉得readme的内容需要写的更加详细,比如功能的用途,操作的方式等
其次操作步骤也应该写得更为详细,像是create和brute是否需要重新再新建一个解决方案?还是在同一个解决方案里就可以完成?如果新建需要在新的项目目录下添加什么文件信息?
在进行whitelist和q的操作后应该会生成什么样的文件,在什么地方生成?这些都是会产生疑问的地方,也是我遇到的问题。
在这次给出的代码中,也产生了对于ismatch()函数的逻辑的疑问,我依然保持我和师兄讨论的观点。对于这个逻辑的疑问,我在优化后的代码中进行了改正。因为如果是判断!=的逻辑然后返回了true值,那么等于并没有进行判断的逻辑。

应改为
