此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2次的very计数1次。
因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
此功能完成后你的经验值+10.
功能一的运行截图如下:
小文件的输入,读取test.txt文件 sort函数排序后输出
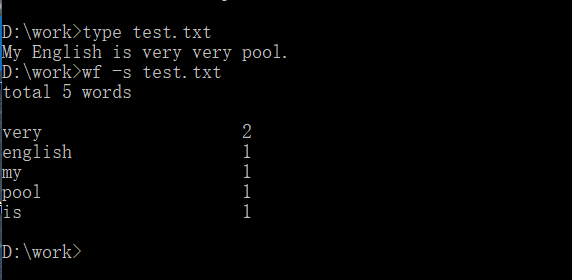
次功能中type 输出test.txt的文本内容
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
读取文章的名字,然后在文章的名字后面加上词缀.txt,然后就和第一个功能一样了,由于单词的数量会很大所以数组要定义的的大一点,
在最开始初步定义不会重复的单词数量不超过1000000的max上届值。
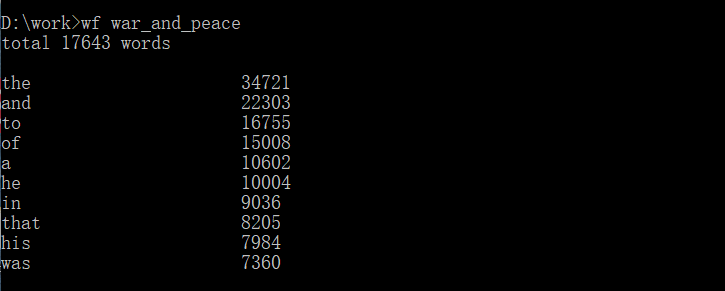
功能二运行截图
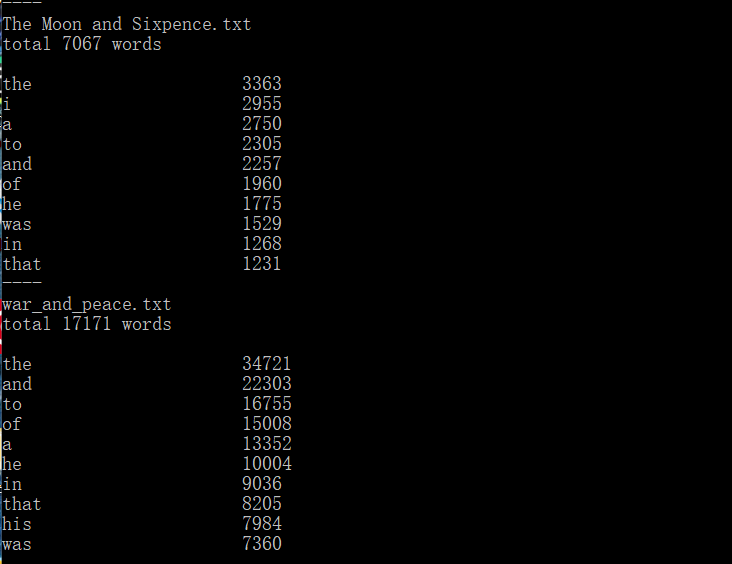
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
因为单词量巨大,只列出出现次数最多的10个单词。
功能三运行截图
读取文件夹的名字,和第二个功能不一样的地方在获得的字符串后面加上.txt的文件后缀,生成fileName,
然后用_findfirst()函数实现文件夹处理,如果返回结果为-1,则说明输入的是文章的名字而不是文件夹的地址
剩下的输出和第一个功能相同,也是sort排序后输出。

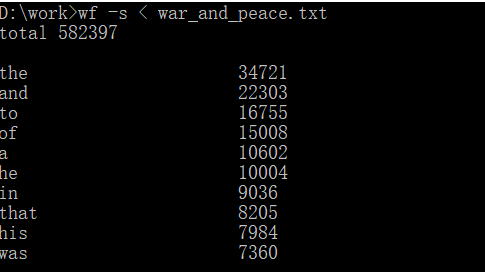
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
功能四运行截图
这个功能的实现上有一些问题还没有解决,在重载<并运行输出后的文章的wordtotal数没有将重复的单词数去掉
发表博客,介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,给出执行效果截图,展示你感觉得意、突破、困难的地方。
首先,要感谢我的师兄在代码实现上的帮助和耐心的讲解,因为自身的能力很差,所以实现的非常困难。
以及在coding和git设置的时候室友的帮助
此处附上我们在完成git相关配置时参考的博客地址:https://blog.csdn.net/gyy930324/article/details/54575246
在读完题目要求以后我查找了很多c和c++相关的内容,首要的就是对文件的取读操作,参考了下面的博客内容
https://blog.csdn.net/naibozhuan3744/article/details/80610476?utm_medium=distribute.pc_relevant.none-task-blog-title-1&spm=1001.2101.3001.4242
https://blog.csdn.net/baidu_29950065/article/details/51659913?yyue=a21bo.50862.201879
https://blog.csdn.net/sub_lele/article/details/78007919?utm_medium=distribute.pc_relevant.none-task-blog-title-1&spm=1001.2101.3001.4242
https://blog.csdn.net/hqw7286/article/details/5603403
对于整个功能实现,首先总结出需要解决的关键点:
文件的取读;单词的大小写转换;对空格和特殊符号的处理;对单词的hash构造;对词频的排序;重定向
1.下面是实现文件取读的重点代码,
首先是定义了单词频率和单词自身的结构体
//结构体WORDS 定义单词和频率,在此重载了"<"
struct WORDS{
int freq;//频率
char content[50];//单词自身
bool operator < (const WORDS &rhs) const {
return freq > rhs.freq;
}
}words[Max];
2.文件输入,用到fopen()函数,定义FILE变量fp,用fgetc()函数读取文件中的内容,
然后用feof()函数判定文件是否遍历结束,最后用fclose()函数关闭
bool定义了一个before的变量用来判断前一个是否是字母
//将输入处理成单个单词
void inputword(char name[])
{
fp=fopen(name, "r");
//用fopen打开文件从而进行输入
before=1;
wordfreq=0;
wordtotal=0;
int i=0;
memset(words,0,sizeof(*words));
//memset函数的作用在于将后面内容变成ascii码方便后续的大小写转换
while(!feof(fp)) {
//用于构造单词,把大写字母变为小写
ch=fgetc(fp);
if((ch>=65&&ch<=90)||(ch>=97&&ch<=122)) {
if(ch>=65&&ch<=90)
ch+=32;
word[i++]=ch;
before=1;
}
else {
if(before) {
word[i]='�';
Hash(word);
//将构造出来的单词hash插入结构体words中
i=0;
before=0;
}
}
}
fclose(fp);
fp=NULL;
return;
}
3.在对单词的存储的考虑时请教师兄说可以使用哈希的思想来进行实现,用hash的方式将单词存入最开始构建的单词的结构体中,
具体的思想是小于三个的字母就按其字母的数量进行插入,大于三个的单词取前三个字母的值组合成六位数然后对最开始设定的最大上届值取余操作得到的值进行哈希的插入,如果该位置有字母了就后移插入。
//用hash的方法去把每个单词插入到结构体中
void Hash(char word[])
{
int len=strlen(word);
if(len>=6)
len = 6;
int i,t = 0;
for(i=0;i<len;i++) {
t=t*10;
t+=(word[i]-97);
}
t=t%Max;
for(i=t;i<Max;i++) {
if(words[i].freq==0) {
words[i].freq=1;
strcpy(words[i].content,word);
//对单词进行复制
wordtotal+=1;
wordfreq+=1;;
return;
}
else {
if(strcmp(words[i].content,word)==0) {
//比较单词是否相同
words[i].freq+=1;
wordtotal+=1;
return;
}
else
{
if(t==Max-1)
t=0;
else
t+=1;
}
}
}
}
4.再然后是对于功能三中的文件夹处理查找了_finddata_t结构体和_findfirst与_findnext函数的使用
参考了此博客的内容:https://blog.csdn.net/wangqingchuan92/article/details/77979669
//功能三
bool three(char fileName[])
{
strcat(fileName, "\*.txt");
//用strcat函数连接文件名和txt的后缀进行区别
long k=HANDLE=_findfirst(fileName, &file);
if(k==-1)
return false;
//得到的文件夹名字后面加.txt
//如果能找到就说明输入的是文件夹的名字
else {
while (k!=-1) {
printf("%s
", file.name);
solve(file.name);
output();
k=_findnext(HANDLE, &file);
if(k!=-1)
printf("----
");
}
_findclose(HANDLE);
}
return true;
}
5.对于文件输出格式,保证只输出前10个出现频率最高的单词,当单词数不够10个的时候就直接顺序输出,用sort()函数排序后输出。以' '进行空格的控制
//对于结果的输出函数
void output()
{
int i,j,len;
len=strlen(words[i].content);
for(i=0;i<((wordfreq<10)?wordfreq:10);i++)
{
printf("%s",words[i].content);
for(j=0;j<3-(len/8);j++)
{
printf(" ");
printf("%d
",words[i].freq);
}
}
}
PSP
(8分)
在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。
PSP阶段表格第1列分类,如功能1、功能2、测试功能1等。
要求1 估算你对每个功能 (或/和子功能)的预计花费时间,填入PSP阶段表格,时间颗粒度为分钟。
要求2 记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度要求分钟。
要求3 对比要求1和要求2中每项时间花费的差距,分析原因。

代码及版本控制
(5分。虽然只有5分,但此题如果做错,因为教师得不到你的代码,所以会导致“功能实现”为负分。)
本次作业的代码地址:https://mochi0828.coding.net/public/wordfreq/homework/git