一、hadoop解决的两大问题
- 解决海量数据的存储
- 解决海量数据的计算
二、两大问题
1.解决海量数据的存储问题
由于海量数据在服务器上的存储需要极大的硬件资源,而在某种情况下可能需要对急剧增加的数据进行存储(该种情况可能已经超出了预期的最大内存范围)。而hadoop提供的分布式文件系统在保障数据的可靠性与安全性的前提下可以实现对硬件存储块的扩展。如下:

即在客户端要存储数据时,需要向Namenode发送请求,NameNode接收到请求时就会向DataNode进行查询,对内存等信息进行查询;然后NameNode将查询出的数据返回给客户端。如若有足够的存储空间,NameNode会将距离客户端最近的节点存储返回给客户端。在客户端将数据上传到NameNode指定的节点后,该节点会自动向其他节点水平扩散存储备份,从而实现数据的安全性。而在数据的传输中会将该数据分成多个部分进行存储传输从而提高系统的性能。
2.解决海量数据的计算问题
由于大数据时代的来临,自然大量的数据计算处理便是面对的最大的问题了,而hadoop提出了MapReduce的处理方法。如下:
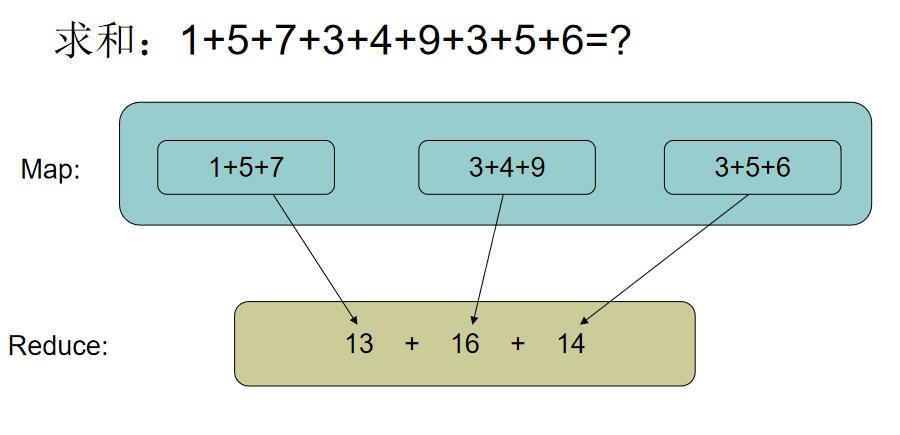
将数据通过分发到不同的服务器上进行并行处理,然后统一返回进行合并计算,并且对计算结果进行校验,如若出现错误则再次部署执行。