讲授时间序列预测问题、神经网络的记忆功能、循环层的原理、输出层的原理、深层网络、BPTT算法等
大纲
序列数据建模
让神经网络具有记忆功能
循环层的原理
输出层的原理
完整的网络结构
深层网络
训练算法简介
训练算法的推导
本集内容简介
从今天开始用四节课讲述循环神经网络,这是除卷积神经网络CNN以外另一个被广为使用的深度神经网络结构。RNN它典型的应用有两块大的领域,一块是语音识别,一块是NLP,它们都有一个特点,就是它们要处理的数据都是序列数据,也就是随着时间线变化的数据,等会会细讲。今天这节课讲这些内容,首先简单介绍一下序列数据建模的基本概念,通过一些实际的例子展示,接下来会介绍怎么让人工神经网络具有记忆功能,因为我们之前学的神经网络他都不具有记忆功能,再接下来我们会讲述RNN的结构,整个RNN它主要的层除了输入层以外就是循环层、输出层以及整个网络的结构,再接下来我们会讲述深层网络的结构,也就是把RNN给做深,然后我们会重点介绍RNN它的训练算法即BPTT算法,该算法理解起来的难度比ANN、MLP、CNN要难一些的,因为它是一个递归的东西。
时间序列预测问题
首先我们简单介绍一下时间序列预测的问题,什么是时间序列预测问题呢?
他是这样一类问题,他要处理的数据是一个时间序列,可以认为就是一个数列,由x1,...,xt组成的,t就是时间下表time,这是其中的一个特点,它是数列,第二个特点是,它的各个xi及xj之间不是没有关系的,我们普通的神经网络也可以处理多个输入值,比如x1,...,xt多个向量,但是它每次只接受一个输入产生一个输出,各次输入之间它是没有关系的,但是这个时间序列他有一个特点就是各个时刻的值它们之间是有关联的,比如说以NLP为例,我们说的一句话它其中的每个词就是一个向量,可以采用one-hot编码(若词典中总共6763个词,然后若出现的是第i个词我们就把向量第i位弄成1其他位弄成0,这个向量是6763维的列向量,但程序里边用的是行向量),那我们把一句话拆成多个词以后对应一个序列x1,...,xt,每个词都是一个one-hot编码的向量xi,这样我们就把一个句子表示成这样一个序列了。
我们直到人说话的时候他显然是有上下文语境的,也就是说后边说的词和前边说的词肯定是有关系的,不是凭空乱造出来的,因此这个序列各个时刻的值是有上下文的关联关系的,而我们的时间序列预测问题它是要解决一个问题,依次把x1,...,xt输进来产生一个输出,一般来说各个时刻都可以有一个输出值,当然接收完输入最后产生一个输出值也是可以的。
比如说句子进行褒贬分类即二分类问题,那就把句子每个词依次输到我们的模型里边,完了以后我们最后预测出一个0或1这样的值出来,这就是时间序列的预测问题。
时间序列预测问题它典型的就是语音识别和NLP,语音识别是怎么做的呢,我们前边第一讲里讲过了,它接收的是一个时间序列的信号,每个时刻有一个振幅值声音在时域里边的信号,它最后产生的输出就是各个时刻对应的是一个怎么样的文字,就是根据这样一个时间线的波形信号产生这样一个句子的输出,这就是语音识别。
NLP也是这样的,还是刚才的例子,我们输入一句话,我们输出这句话它要完成的意图,比如说做自动对话客服机器人,你对它说了一句话,它要判断你这段文字你是想干嘛,比如说想维修你的电器还是想退货还是想咨询一个使用的问题等等,那这就是一个时间序列的预测问题,我们说的一句话把它抽象为一个向量的序列作为输入,对它进行分类。
我们想一下,这种序列预测问题我们可不可以用一般的神经网络来做呢?不能。为什么呢?普通的神经网络如ANN、MLP,它要求我们是一个固定长度的输入信号,也就是说输入向量X是固定长度的,它产生一个输出,这显然是不满足,因为它的长度是随时间线变化的,就是把各个时刻的向量拼接起来形成一个更大的向量也是不行的,而标准的CNN也是不行的,因为它接收的是一个图像数据,如果把时间序列向量按行或列摆开成像图一样的二维数据送到CNN里边去处理,但是直接这样送进去也是不行的,因为这个序列长度它是不固定的,因为句子有长有短、声音信号可能有长有短,那要么你用0补齐送到里边去预测,但显然不是一种合适的做法。
所以说我们的时间序列预测问题它会遇到两个问题,第一个就是序列长度他不是固定的,即x1,...,xt这个t是多少是不固定的,第二个问题是各个时刻的值即xt、xt+1它们之间是有关系的,句子里说的下一个词显然是由前边几个词共同决定的与其有关的,因此它各个时刻之间存在依赖关系,这样就需要我们的神经网络,如果依次输入每个词来处理的话,那他就要具有记忆功能,也就是它要能记住前边那些时刻从1时刻到t-1时刻它输入的是什么东西,把它记在脑子里边,然后再接收t时刻输入的时候他要和前边1到t-1时刻输入的信息共同的来决定一个输出值。一个实际的例子,让神经网络或其他的机器学习模型做句子填空题。
现在已经下午2点了,我们还没有吃饭,非常饿,赶快去餐馆__。
神经网络具有记忆功能
下面我们来解决这样一个核心问题,怎样让人工神经网络它具有记忆功能。
前边讲的典型的神经网络,如全连接神经网络MLP,它的输入值是一个向量X,比如说它先对第一个样本X1进行预测,再对X2进行预测,它两次运行之间是没有任何关系的,即x1运行产生y1这样一个输出,x2预测的时候产生y2这样一个输出,y1、y2之间没有任何关联,也就是说我们预测y2没有用x1这个值,因此神经网络它是每次运行时独立的,他每运行一次产生一次输出值,就是里边没有记忆任何上一时刻的信息,而CNN也是类似,它接收的是一张输入图像I这样一个张量或矩阵、二维数组这样的数据,最后产生一个输出,它和全连接神经网络一样,它也没有记忆功能,比如说你对第一张图象进行识别和对第二张图像进行识别,它们两个之间是没有任何关系的,它运行一次就预测一次,自动编码器也是一样的,其实它本质上就是一个全连接的神经网络,而受限玻尔兹曼机也是这样的,我们输入一个可见变量的向量V,然后产生一个隐变量Z即V的状态值,两次运行之间也没有任何关系。
因此我们归纳一下,前边讲的人工神经网络它每次运行做预测推理的时候,它是独立的,就是第一次预测和第二次预测之间没有任何关系,因此这样的神经网络它不具有任何的记忆功能。那我们想,怎样才能让人工神经网络具有记忆功能呢?显然你要记住上面一个时刻的值,神经网络它运行中间会出现一些值,中间值或输出值,我们把这些值记下来,供下一个时刻使用不就可以了吗?但是直接把最后的输出值记下来供下一个时刻使用,这个是不灵活的,因为它都已经产生了一次输出了,再供下一个时刻使用的话,本质上还和前边的神经网络是一样的,只是把输出值进行运算,本质上我们的神经网络还是不具有记忆功能,只是外边记录了它的上个时刻的输出值,而我们现在要的是神经网络能记住上个时刻或更早时刻它里边的那些神经元的状态值,这就是我们的循环神经网络要做的事情。
循环层的原理
我们说RNN它具有记忆功能,它是怎么实现的呢?刚才已经说了他只要把上面一个时刻运行的中间结果状态值记忆下来就可以了,这个功能是由循环层来实现了。假设上个时刻某一个层它的神经元输出值(称为状态值)为ht-1,本时刻神经网络还要接收一个输入值xt,它们两个共同作用产生一个输出值ht,ht-1就体现了记忆功能,这样就定义了一个递推的数列,这就像我们的高中的等差、等比数列一样,而这种简单递推数列只由上时刻值决定而本时刻他还没有接收输入值,我们本时刻也可以接收一个输入值即an=an-1+xn,就达到了我们想要的目的了,即每个时刻接收一个输入值注入新的东西,而且我们还利用了更早时刻的值,所以RNN它的核心灵魂就是这样一个递推公式ht=f(ht-1,xt),即上一个时刻的记忆值和本时刻的输入值来决定本时刻的输出值,那这个f该怎么构造呢?
我们的人工神经网络,前边讲的时候它是有加权加上偏置项最后用激活函数激活一下,那我们RNN也可以这样用,因为这样是一种最简单标准的模式,
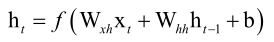
激活函数f保证非线性,()里边的是线性运算,这样实现起来是比较简单的,比如说训练的时候求导或者正向传播的时候预测都非常简单很统一规整。其中Wxh是当前层输入值的权重矩阵,Whh是状态的权重,b是偏置项,f是激活函数,神经元不光由当前时刻的输入向量xt,还和上一个时刻所有的神经元都有关系,在计算的时候,每个神经元它在计算的时候都利用了所有的神经元在上一个时刻的状态值,这样我们就定义了这样的一个递推数列,根据这个数列展开的话,算ht的时候它是体现了从x1,...,xt所有时刻的输入值的,因此它具有记忆功能,如果抛掉Whhht-1这一项的话,这个式子和我们的全连接神经网络、CNN其实是一样的,它多就多了这样一个记忆项。
如果我们把RNN用图画出来的话是比较形象的:
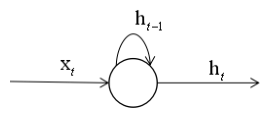
中间的⚪表示循环层所有的神经元不是一个神经元,在t时刻它接收当前时刻的输入向量xt,还接收这些所有神经元的上个时刻的记忆值ht-1,然后共同作用产生这样一个ht的输出值,而ht-1这一块就体现了记忆功能。如果我们把RNN它的输出值按照时间线一字排开,从1时刻到t时刻为止,我们可以形成这样一张图:
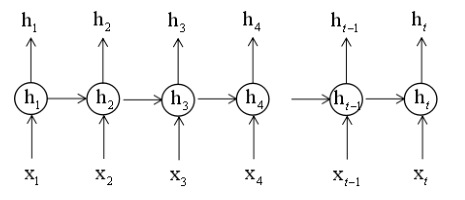
强调一点,权重矩阵Wxh它肯定是所有时刻都一样的,因为我们的人工神经网络它的权重值不会随着运行的时候变化的,一旦训练出来以后它就是固定的。
还要强调一点Whh由上一个时刻隐含层的状态值到本时刻隐含层的输出状态值的这样一个权重矩阵,它各个时刻也是固定死的不会动的,不管什么时刻用的都是这样一个值。这样做的好处是减少参数的数量,如果Whh随时间变化的话,他会每个时刻有一个矩阵,神经网络它接受的输入序列长度是不固定的,到底有多少个Whh根本就不知道,输入的句子可能有100个词、1000个词都是有可能的,每个Whh不一样的话参数也会太多,这是第一个原因,第二个原因就是它体现了记忆功能,如果Whh随着时间变化的话,它就失去了一部分记忆功能去了,因为不管在任何时刻,我碰到这个词都要产生这样一个输出值,因此各个时刻到RNN它的Whh权重矩阵的值都是一样的。
还有一点强调,循环层的每个神经元当前时刻的状态值与本层其他所有神经元上一时刻的状态值都有关系,而不只和本神经元上一时刻的状态值有关。
循环层的激活函数是要保证非线性的,因此它的作用和全连接神经网络、CNN是相同的,而且在RNN里边,我们激活函数会使用tanh,当然用sigmoid、ReLU也是可以的,但很多时候我们会用tanh这个函数。
输出层的原理
在介绍了循环层的工作原理以后,接下来我们来介绍输入层的原理,输入层很简单,如果有几个分量的话就有几个神经元,输出层是从循环层接收输出值,每个时刻接收一个输出值ht,然后来产生一个最终的输出Y来,因此它是不具有记忆功能的,记忆功能是由循环层来实现的,循环层给它什么值它就输出什么值,它这里没有记住上一时刻的值,因此他的变换和我们的普通神经网络是一样的,它的权重矩阵叫Wo,o是output,偏置项是bo,再用一个激活函数g来映射一下,当然选用softmax函数也是可以的,其实我们在用的时候很多时候都用的softmax函数,这样它的输出就是一个概率向量了,即这个时刻把前边这些信息预测成K个类中每个类的概率值,严格来说softmax和一般的激活函数还不太一样,因为它实现变化的时候,输入是一个向量输出还是一个向量,输出向量里边每个值它由输入向量的每个值来共同决定,因此它和前边我们讲的一对一的映射即对输入向量逐元素映射是不一样的。
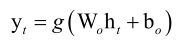
总之,对RNN来说,一般我们的输出层它的映射函数是softmax函数,这样我们的RNN在每个时刻接收一个输入值x1,...,xt,每个时产生一个输出值y1,...,yt来,y表示的是概率向量,比如说这个句子到目前为止判定为某种意图的概率,每个时刻都会输出这样一个概率值来,这就是输出层的原理。
一个简单的RNN
前边说的可能有一点抽象,下面我们来看一个简单的RNN,麻雀虽小五脏俱全。
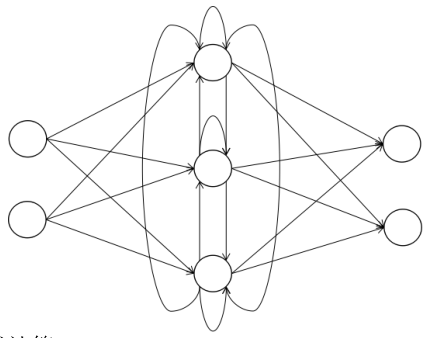
这个RNN它由3个层组成,即输入层,它的输入值是x,隐含层,它的状态输出值是h,最后输出层它的值是y,用这三个向量来表示。
输入层它有两个神经元,它的分量分别是x1,x2,隐含层有3个神经元,h写成分量的形式就是(h1,h2,h3),而输出层有两个神经元,它接收的是循环层的输出值,即h这个向量的输入产生y向量的输出,它有两个分量y1,y2,我们可以给x、h、y加上时间下标t。
循环层也就是隐含层,他从输入层接收数据,它除了从输入层接收数据以外,循环层的每个神经元它还和循环层所有神经元之间有连接关系,也就是说循环层每个神经元它本时刻的输出值和上个时刻的记忆值ht-1有关还和该层其他神经元上个时刻的记忆值都是有关系的,它们共同决定的ht,把ht送到输出层里边去映射,比如说通过softmax函数映射一下得到一个输出值,整个工作过程就是这个样子的。
循环层的计算公式: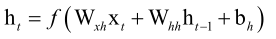
即当前时刻的输入值、上个时刻的记忆值各自乘以一个权重矩阵Wxh、Whh,再加上一个偏置向量bn产生一个循环层的输出值,又把这个输出值送到输出层里边来进行处理,
输出层计算公式: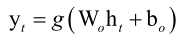
乘以一个权重矩阵Wo,加上一个偏置向量bo,用另外一个映射函数g映射一下,最后产生一个输出值yt,这就是这个简单的循环神经网络它工作的过程。
将数据按照时间线展开
如果我们把RNN按照时间轴展开的话,看得更清楚一些,当t=1时刻,输入值为x1,循环层拿x1映射一下得到h1,输出层拿h1映射一下得到y1,
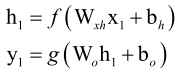
t=2时刻就更复杂一些了,我们用递推公式,h2由x2、h1得到的,
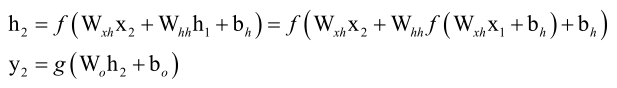
最终y2由h2决定,即最终还是x2、x1决定。
最终会发现t=3,4,...时刻对应的y3,y4,...yn是由x1,...,xt决定的,这也就体现了记忆功能,即每个时刻的输出值它不光利用了当前时刻的输入值xt,它还利用了x1,...,xt-1这些值,因此它就完整的记住了之前所有的输入序列的信息了,所以说我们的RNN通过这样的一个递推的数列来实现了记忆的功能。
深层网络
前面我们介绍的都是浅层网络,只有一个输入层、一个隐含层、一个输出层来构成的,其实我们可以把网络造的更深一些,和RNN、全连接神经网络一样的,这里有三种方案,当前把它们混合起来也是可以的。
第一种方案称为Deep Input-to-Hidden Function,它在循环层之前加入多个普通的全连接层,将输入向量进行多层映射之后再送入循环层进行处理。
第二种方案是Deep Hidden -to-Hidden Transition,它使用多个循环层,这和前馈型神经网络类似,唯一不同的是计算隐含层输出的时候需要利用本隐含层上一时刻的值。
第三种方案是Deep Hidden -to-Output Function,它在循环层到输出层之间加入多个全连接层,这和第一种情况类似。
这里强调的是,只有循环层具有记忆功能,其他层均无记忆功能。
由于循环层一般用tanh作为激活函数,因此层数过多之后会导致梯度消失问题,因为把循环层记忆单元拿掉之后,他就和全连接神经网络是一样的,那怎么办呢?
我们一般不换成ReLU函数,所以我们可以像残差网络一样,采用跨层连接的方案,就是循环层之间可以相互跨,即一个循环层可以直接跨到下下个循环层,把中间的循环层给垮掉,这样也是可以的,做语音识别、机器翻译等等任务的时候很多网络采用的这种跨层连接的结构。
BPTT算法简介
前边我们介绍了RNN它的结构和原理,以及它的正向传播算法,它的正向传播算法每次接收的是一个输入序列x1,...,xT这样一个向量的序列,每个时刻会产生一个输出值y1,...,yT,这个y一般是通过softmax回归映射出来的一个概率向量,每个时刻都有这样一个概率向量,整个这样一个过程成称为一个样本,就是它的一个样本是由多个向量构成的,这和前边的神经网络是有本质的区别的,而且这个序列长度是不固定的。
我们知道,RNN它的循环层有参数权重矩阵Wxh、Whh、bh,输出层参数Wo、bo,那这些参数和普通的神经网络一样,它也是通过训练得到的,这个训练算法称为BPTT算法,即时间抽上的反向传播算法。
和普通的神经网络有很大的区别是它的每一个训练样本是一个时间序列构成的,然后它包含多个相同维数的向量,然后每个时刻到输入值它对应的一个输出值,然后我们根据这个预测出来的输出值和真实的标签值yi,i从1到t,他们之间构造一个误差损失函数。
所以说RNN它的每个训练样本是一个时间序列,同一个训练样本它前后时刻的输入值之间是有关联的,每个样本的序列长度还可能不一样。
训练的时候是怎么做的呢?先用这样一个样本它每个时刻的输入值x1,...,xt放到网络里边去预测一下,正向传播产生输出值y1,...,yt,再通过反向传播根据这个预测出来的y1^,...,yt^和真实的标签值y1,...,yt它们之间来构造一个损失函数或误差函数,来计算这个损失函数或L对这些权重矩阵W即隐含层的权重和偏置以及输出层的权重和偏置的梯度来更新这些参数就OK了。
损失函数
在推导之前,我们首先看一下只有一个循环层和一个输出层RNN,它正向传播的时候是怎么做的。首先对输入数据xt以及上个时刻的记忆值做一个线性映射再用激活函数激活一下,
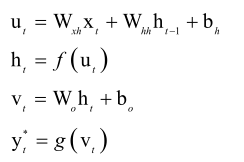
这里边我们用了一个临时变量u,我们在前边推导RNN以及全连接神经网络的反向传播算法的时候,我们都用了这样的一个u来表示线性映射后的临时值,这个u它是激活函数的自变量,得到h以后再用输出层再来映射一下,也是先乘以权重矩阵加上偏置向量,做完以后得到一个临时向量V,再把V送到映射函数里边去映射一下得到y*,t时刻的预测值叫yt*,这是神经网络预测出来的值。
然后它和我们真实的标签值一减,当然可以直接减或用softmax交叉熵之类的,我们一般使用softmax的交叉熵来构造这样一个具体时刻的损失函数,Lt=L(yt*,yt),而前边我们说了RNN它的单个样本是一个时间序列构成的,每个时刻它的预测值都和真实标签值会产生一个损失,因此我们要把各个时刻加起来,定义这样一个损失函数,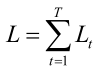
注意这个T他可能对每个样本来说长度是不一样,因此我们这里先考虑单个样本的情况,每次我们的反向传播先用单个样本正向传播一遍再来反向传播一遍,所以它和普通的神经网络相比,它的一个本质区别在它损失函数是各个时刻加起来的,对单个样本就是这个样子的,而且各个时刻的值是有关联的,x1,...,xt及y1,...,yt它们之间是有联系的。
我们前边讲过普通的神经网络,无论是RNN还是全连接网络,它正向传播的时候都是根据x1来算x2,x2来算x3,...,一直到xL,xL是最后的输出值,它和真实的标签值y相减算交叉熵也好欧氏距离也好,产生一个损失函数L,然后我们算这个损失函数L对各层的参数的偏导数,也就是梯度值,它通过反向传播算法来实现,定义一个δ(L)这样一个损失函数临时变量u(L)的梯度值,我们把它定义为误差项,根据后一层的误差项算前层的误差项,反复这样前传播,每一层先把δ(L)算出来以后,再算对权重矩阵W以及偏置向量的梯度值,然后用梯度下降来更新,而这个反向传播它是在层之间进行的,也就是它是在空间结构上进行的,由后一层传到前边一层上边去,而我们的BPTT算法它和这个类似,但是他不是在空间结构上进行的,它是在时间轴上进行的,x1,...,xt,我们输进去以后会得到h1,...,ht,进一步得到y1,...,yt,然后它算误差项的时候是沿着时间轴方向进行传播的,先把对ut的梯度值算出来,再往前传播算前一个时刻的δ项,这个时候它的δ定义的是损失函数L对ut的梯度值,把它算出来以后就可以把循环层的权重矩阵Wxh以及偏置向量bh的梯度算出来,然后进行梯度更新,所以说它的反向传播算法是沿着时间来进行的,也就是从t时刻开始到t-1时刻到t-2时刻...到1时刻为止这样来算的。
这里边还有另外一个本质区别就是普通的神经网络,比如全连接神经网络和CNN它各层的权重W它是不一样的,而我们的RNN循环层的Whh各个时刻用的是同样一个值,所以说它处理起来更麻烦一些。
我们先按照时间轴展开一下,到3时刻为止:
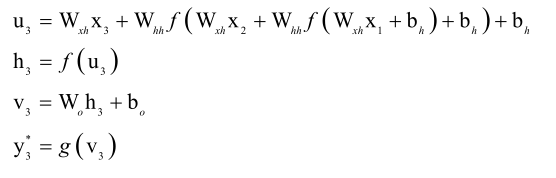
可以看到临时变量u3它和x1、x2、x3都有关系,并且它和每个x相关的时候,乘的都是Wxh这个矩阵,它每一层还乘了一个Whh,而Whh在各个时刻是一样的,对比一下全连接神经网络的损失函数:
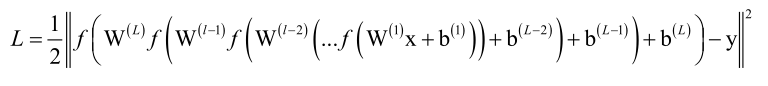
它每一层乘的是不一样的一个矩阵,而RNN每层乘的是同意给矩阵Whh。RNN的损失函数是关于yt*与yt的,而y*又是Vt的函数,Vt是ht的函数,ht是ut的函数,归根结底L是ut的函数,所以每个时刻都与Whh、Wxh有关,因此它计算起来会更麻烦一些,也就是说我们要对Whh求偏导的话,每一层都和它有关系,它都是同样一个矩阵,下面就来看这个问题怎么解决。
输出层求导
首先来看输出层,因为输出层比较简单,他没有记忆功能,因此我们可以先算输出层的梯度值,就是损失函数L对Wo、bo的梯度值,就是损失函数L对Wo、bo的梯度值,这时候我们利用了V这个临时变量,这个时候我们只要计算出损失函数L对任一时刻Vt的梯度值的话,那我们就可以算出它对Wo、bo的梯度值,那我们看怎么弄。
首先计算输出层偏置项的梯度:
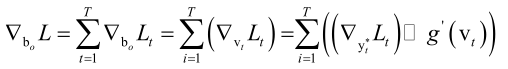
损失函数对偏置项bo的梯度值,它是由各个时刻的损失函数Lt对bo的梯度值加起来共同构成的,而每个时刻它对bo的梯度值等于每个时刻损失函数对V的梯度值,因为Vt=Woht+bo,根据对y*的梯度值算对V的梯度值。
如果选用softmax作为输出层的映射函数,用交叉熵来做损失函数的话,则刚才的梯度就可以写成:
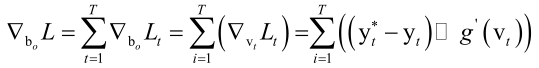
那我们可以很方便的把整个损失函数L对输出层的偏置向量bo的梯度值给算出来,类似的我们可以算对Wo的梯度值,也是一样的,把各个时刻的损失函数对Wo梯度值加起来,即
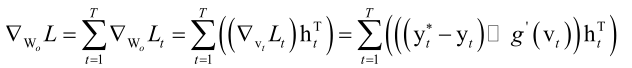
这里利用了一个以前已经证明过的结论,即Y=WX,则▽WL=▽Y*XT,这样我们就解决了输出层它的权重矩阵以及偏置项的求导,核心的就是两点,第一点就是我们前边推导的基本公式,第二点就是softmax交叉熵它的损失函数对于神经网络的预测值yt*求偏导就等于yt*-yt。
这样我们就解决了输出层的求导问题了,接下来我们来看循环层,比这复杂多了。
循环层求导
先回忆一下循环层,它正向传播的时候临时变量是这样的
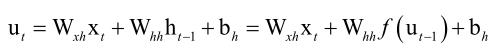
这样就建立了ut和ut-1之间的递推关系,假设我们已经算出了t时刻的损失函数对ut的梯度值了,那怎么算损失函数对ut-1的梯度值呢?这里经过两次复合即Whh、f(),根据以前的结论,则
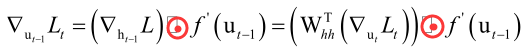
这其实和前边的全连接神经网络是一样的。
这里定义一个误差项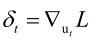 ,即整个损失函数对ut的梯度值,如果算出来▽utL那么我们就可以很容易的把▽WhhL给算出来了,我们怎么来看这个问题呢?我们把损失函数按照时间线展开L1,...,Lt,我们在求对任何一个ut偏导数的时候,(注意T表示时间序列长度,t表示变化的那个下标),如果我们要算整个加起来的损失函数L1+L2+...+LT,对ut的梯度值的话,这里有三种情况,比t还小的那些时刻的损失函数它里边根本就不含ut,而Lt的话就刚好和ut直接关联,然后Lt+1,...,LT都是和ut有关的,因为它被带进去反复的复合,就像L3它和u2、u1是有关的,因此我们把损失函数分成三段,即比t时刻小的与ut无关对ut梯度值为0,Lt直接与ut相关,比t晚的时刻每一个L都和ut有关系,这样我们就便于理解了。
,即整个损失函数对ut的梯度值,如果算出来▽utL那么我们就可以很容易的把▽WhhL给算出来了,我们怎么来看这个问题呢?我们把损失函数按照时间线展开L1,...,Lt,我们在求对任何一个ut偏导数的时候,(注意T表示时间序列长度,t表示变化的那个下标),如果我们要算整个加起来的损失函数L1+L2+...+LT,对ut的梯度值的话,这里有三种情况,比t还小的那些时刻的损失函数它里边根本就不含ut,而Lt的话就刚好和ut直接关联,然后Lt+1,...,LT都是和ut有关的,因为它被带进去反复的复合,就像L3它和u2、u1是有关的,因此我们把损失函数分成三段,即比t时刻小的与ut无关对ut梯度值为0,Lt直接与ut相关,比t晚的时刻每一个L都和ut有关系,这样我们就便于理解了。
基于这样一个考量,我们整个损失函数对ut的梯度值ft可以写成当前时刻对ut的梯度值▽utLt再加上比它更晚的所有时刻的损失函数加起来对ut的梯度值![]() (由上述的式子可得),由于
(由上述的式子可得),由于
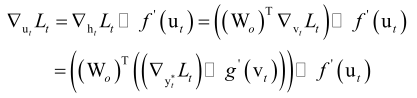
因此有
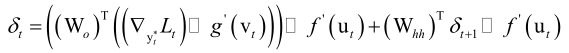
这样我们就完成了误差项它的递推公式的建立,这里比我们全连接神经网络绕了,因为全连接网络是在层之间进行复合的,而这是在时间轴上反复递归重用复合的。
一旦我们把δ算出来就简单了,全连接神经网络中δ是损失函数对该层临时变量u的梯度值,而RNN中δ是损失函数对该时刻临时变量u的梯度值,即δt=▽utL,前边说了RNN的隐含层是怎么做的呢,ut=WxhXt+Whhht-1+bn,这个ut是Wxh、Whh的函数,因此我们只要把对ut的梯度值算出来以后,我们就很容易把对Wxh、Whh的梯度值给算出来,因为各个时刻的u它都和Whh、Wxh有关,因此我们要把各个时刻的▽utL加起来再对Whh、Wxh即求导的链式法则,这样就求出L对Whh、Wxh的梯度值了,即
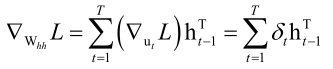
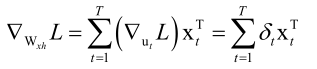
,而对bn的梯度值可以直接算出来,即
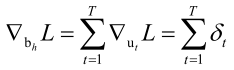
理解BPTT的核心是Whh它是反复的使用的,一次一次的重用迭代,然后就是损失函数它是有多个时刻构成的,只要知道了这样一个递推公式的建立以及每个u都和Whh、Wxh、bn有关,这样就很容易的把这个事情给理解了。
BPTT算法的流程
得到这些公式以后,我们再看一下BPTT算法它的流程是怎样的,它是先正向传播,1时刻开始到T时刻为止,x1,...,xT放到神经网络里算一把,每个时刻都运行一遍,得到Y1*,...,YT*,根据Y1*,...,YT*和Y1,...,Yt标签值来构造损失函数,这时候正向传播就结束了。
接下来反向传播,先计算输出层权重和偏置的梯度值,这个可以直接算出来的,因为它不具有记忆功能,就相当于一个单层的神经网络可以把它直接算出来,接下来用梯度下降法更新输出层权重和偏置的值。
然后开始反向传播,从T时刻开始到1时刻为止,算每个δt,算完以后可以根据δt来算对循环层的权重矩阵和偏置的梯度值,算出来以后再对循环层的权重和偏置的值进行更新,用梯度下降法进行更新,反复这样做就可以了,所以说它的反向传播是从时间轴上进行的,从T时刻到T-1,...,一直到1时刻为止,算δ,根据δ来算对循环层的权重矩阵以及偏置向量的梯度值,这就是反向传播算法的流程。
本集总结
首先我们介绍了时间序列的预测问题,并且通过语言识别还有NLP里边的一些例子进行了说明,接下来我们考虑了一个核心的问题,怎么样让人工神经网络具有记忆功能,也就是用上一层运行的值来构造下一层的输出值,再接下来的核心是,讲解了RNN的原理,包括它的循环层、输出层、还有整个网络的结构,讲完这些以后我们介绍了怎么构造一个DNN即多层的循环神经网络,到这里为止,我们的RNN它的工作原理已经讲完了,再接下来我们讲一下核心的问题就是BPTT算法,它是怎么训练出来的,时间轴上的反向传播算法,这里特别强调的是它的损失函数是由各个时刻的损失函数来构造的,即∑Lt,这里边也要算误差项δt,全连接神经网络、RNN里边是各层的误差项δ(l),而这里是各个时刻的误差项,它是由损失函数L对循环层临时变量ut来计算的,然后根据δt我们可以算出RNN它的损失函数对我们循环层的权重矩阵Wxh、Whh的梯度值及对bh的梯度,然后再用梯度下降法进行更新就可以了。