大纲:
算法分类
有监督学习与无监督学习
分类问题与回归问题
生成模型与判别模型
强化学习
评价指标
准确率与回归误差
ROC曲线
交叉验证
模型选择
过拟合与欠拟合
偏差与方差
正则化
半监督学习归类到有监督学习中去。
有监督学习大部分问题都是分类问题,有监督中的分类问题分为生成式模型和判别模型。
分类问题常用的评价指标是准确率,对于回归问题常用的评价指标是回归误差均方误差。
二分类问题中常为它做ROC曲线。
过拟合通用的解决手段是正则化。
算法分类:
监督信号,就是样本的标签值,根据知否有标签值将机器学习分类为有监督学习、无监督学习、半监督学习。
有监督学习与无监督学习:
有监督学习分两个过程:训练和预测。
预测根据输入样本(x,y),训练出一个模型y=f(x)来预测新的样本的标签值。
无监督学习:聚类和数据降维。
数据降维是为了避免维数灾难,高维数据算法处理起来比较困难,数据之间具有相关性。
强化学习:
是从策略控制领域诞生出来的一种算法,它根据环境数据预测动作,目标是最大化奖励值。
分类问题与回归问题:
有监督学习分为分类问题和回归问题,如判断一个水果的类别就是分类问题,根据个人信息预测收入就是回归问题。
分类问题:
Rn-->Z,把n维向量映射为一个整数值,该值对应一个分类。
人脸检测就是而分类问题,图像中某个位置区域是人脸还是不是人脸。
二分类问题最简单办法是找到一个直线方程进行分类,线性分类器sgn(wTx+b),输出+1或-1。
回归问题:
Rn-->R,R是要预测的实数值。
最简单的算法是线性回归f(x)=wTx+b,相比分类问题省去了sgn函数。
损失函数也叫误差函数, ,几乎对于所有的有监督学习,它的目标都是最小化损失函数或者最大化的对数似然函数,在确定了这个优化目标以后,工作就完成一半了,剩下的就是完成最优化求解问题了,可以标准的算法如梯度下降法、牛顿法等,根据自己算法的特点选用一个合适的最优化算法来求解,这是标准化的流程,求解完之后,就求解出了f(x)参数值完成了训练,之后就可以用f(x)来预测新的样本用来做分类或者回归。
,几乎对于所有的有监督学习,它的目标都是最小化损失函数或者最大化的对数似然函数,在确定了这个优化目标以后,工作就完成一半了,剩下的就是完成最优化求解问题了,可以标准的算法如梯度下降法、牛顿法等,根据自己算法的特点选用一个合适的最优化算法来求解,这是标准化的流程,求解完之后,就求解出了f(x)参数值完成了训练,之后就可以用f(x)来预测新的样本用来做分类或者回归。
线性回归:
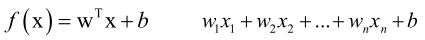 ,是一个线性函数。
,是一个线性函数。
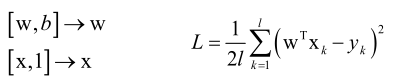
训练的目标是最小化均方误差MSE,训练的时候要求解的是一个无约束条件的凸优化问题(要证明是均方误差损失函数是凸函数,就要证明它的Hession矩阵半正定),凸优化问题就可以找到L的全局极小值点。
证明MSE损失函数是凸函数:
求L的Hession矩阵:
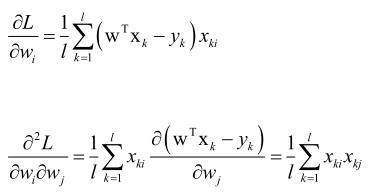
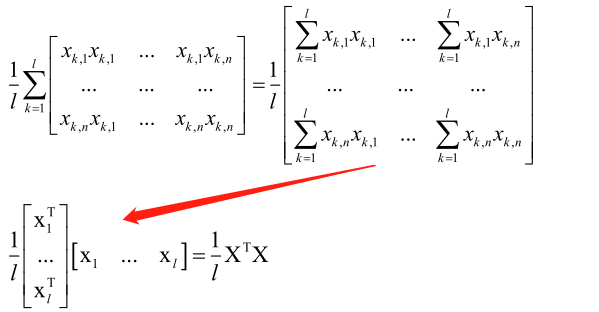
1/lXTX矩阵对应的二次型为xT1/lXTXx,即1/l(xTXT)(Xx),即(Xx)T(Xx),由于(Xx)T是一个行向量,(Xx)是列向量,它们两个相乘是向量做内积,大于等于零,所以Hession矩阵半正定,所以MSE损失函数L是凸函数,存在全局极小值点。
生成模型与判别模型:
对于分类问题按照求解思路可以把它分为两种类型:
①判别模型,直接根据函数判断它是属于哪一个模型。
第一种是y=f(x),直接根据一个预测函数sgn(wT+b)预测出标签值y来。
第二种是p(y|x),算它的后验概率,根据特征x计算它属于每个类的概率,根据特征反推它所属的类,这就是后验概率。
②生成模型
对x、y联合分布建模,p(x,y)=p(x|y)p(y),即假设x服从某种分布对p(x|y)、p(y)进行建模。
生成模型的另一种定义是用来生成数据的算法,如GAN。
判别模型和生成模型区别:
判别模型是求p(y|x),生成模型是求p(x|y)。
学习的大部分的分类算法都是判别模型。
生成模型:贝叶斯分类器,高斯混合模型,隐马尔可夫模型,受限玻尔兹曼机,生成对抗网络等。
判别模型:决策树,kNN算法,人工神经网络,支持向量机,logistic回归,AdaBoost算法等(虽然logistic中用到概率了,但是它是直接计算的p(y|x),即样本属于某类的概率,并没有假设x服从某种概率分布对p(x|y)、p(y)进行建模)。
在解决分类问题时是有本质区别的:
判别模型直接找一个分界线出来,至于两边样本服从哪一种分布,哪里密集哪里稀疏并不关注。生成模型是先算出两边样本服从的分布,再来算样本属于某个类的概率的。
评价指标:
因为要比较算法的优劣,所以引入评价指标。对于同一类问题可能有不同的算法都可以解决它,要判断哪一种算法更好,其中衡量的一个依据就是它的准确率或是叫精度,还有另一个指标是算法的速度。
准确率与回归误差:
对于分类和回归问题它的精度的定义是不一样的。
对于分类问题用准确率表示,即正确分类的样本数/测试样本总数,样本分为训练集和测试集,用测试集(和训练集不相交)来统计准确率,因为用训练集统计准确率是没有意义的。
回归误差是回归问题的评价指标,因为分类问题是一个是和否的问题,而回归问题它是一个连续实数值,不能用是和否来回答,所以用回归误差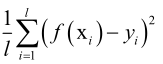 。
。
对于二分类问题:


ROC曲线:
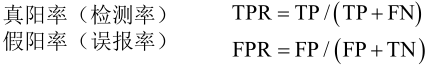
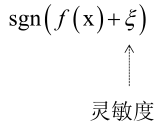
对于二分类问题的评价指标,仅仅用一组精度和召回率的指标还不够,可以调节灵敏度从而改变真阳率和假阳率,从而绘制一个关于假阳率为x轴真阳率为y轴的曲线。即随着灵敏度的增大,误报率越来越大,随着误报率越大真阳率也会越大,即是一个增函数,但是在误报率小的情况下而真阳率大,这才是我们想要的算法,即ROC曲线下的面积越大算法越好。
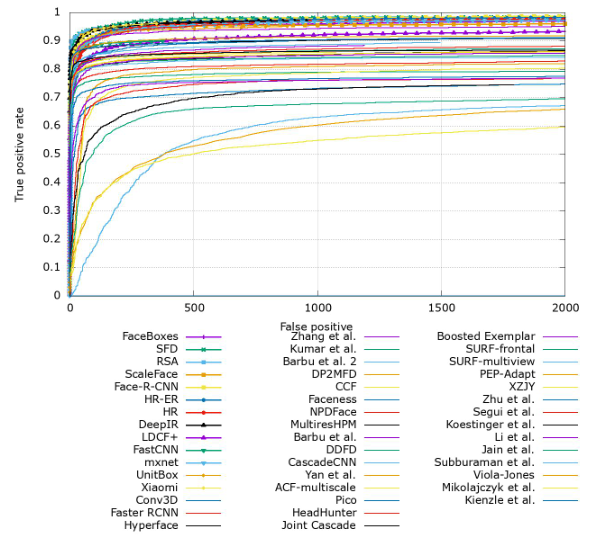
上图ROC曲线来自FDDB官网,FDDB是一个专门用于人脸检测的数据库,来区别算法的好坏,以上图像的x轴用的是误报数,没有归一化,只要除以一个负样本总数就得到误报率,不影响曲线总体趋势,y轴是检测率,取值0~1之间。
混淆矩阵:
是多分类问题的评价指标。

每一行为每一类样本,每一列为被分类器分为的样本类的数目,显然主对角线为正确分类的样本,所以说混淆矩阵主对角线数目越大两边值越小,则分类算法效果越好。
交叉验证:
准确率怎么统计:
把样本分为训练样本集和测试样本集,在训练样本上的为训练准确率,在测试样本集上的为测试准确率,以测试准确率最为准确率来衡量算法的好坏。
k交叉验证就是把样本集分为k份,k-1份为训练集,1份为测试集,计算出一个准确率,然后依次拿其中一份为测试集,这样最终得到k个准确率,然后取均值就得到最终的准确率。这样得到的准确率比把样本一分为二为训练集和测试集得到的准确率更准确一些。交叉验证英文名为CV(cross-validation),和计算机视觉简写是一样的,很多机器学习的开源库中都实现了这种功能。
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证 集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取 2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
模型选择:
算法选择的问题,泛化能力指的是算法在除了测试样本集以外的那些样本集上的准确率或回归误差指标。
欠拟合:
训练得到的模型在训练集上表现差,没有学到数据的规律。引起欠拟合的原因有模型本身过于简单,例如数据本身是非线性的但使用了线性模型;特征数太少无法正确的建立映射关系,就是巧妇难为无米之炊,就是算法再先进,样本本身的特征弄的不好,在训练集上的精度也会非常差的。
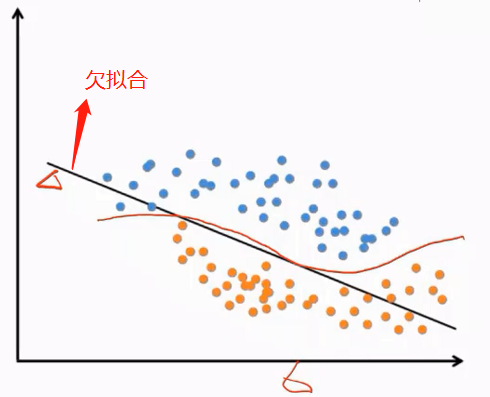
过拟合:
过拟合是和欠拟合相对应的一个概念,直观表现是在训练集上表现好,但在测试集上表现不好,推广泛化性能差。过拟合产生的根本原因是训练数据包含抽样误差,在训练时模型将抽样误差也进行了拟合。所谓抽样误差,是指抽样得到的样本集和整体数据集之间的偏差。
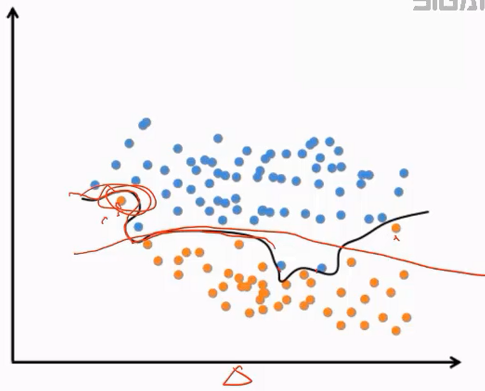
引起过拟合的可能原因有:模型本身过于复杂,拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。
总结:
大多数情况下遇到的是过拟合,欠拟合是非常少的,一般情况下在训练样本集上算法都会收敛掉的。

偏差与方差:
泛化误差的来源究竟在什么地方呢?可以对它进行分解得到偏差和方差分解公式,可以指导我们进行模型复杂度选择。
偏差(bias)是模型本身导致的误差,即错误的模型假设所导致的误差,它是模型的预测值的数学期望和真实值之间的差距。
方差(variance)和概率统计里方差的定义是一样的,是由于对训练样本集的小波动敏感而导致的误差。它可以理解为模型预测值的变化范围,即模型预测值的波动程度。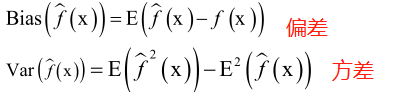
偏差和方差分解公式: ,最后一项是噪声项。
,最后一项是噪声项。
推导:
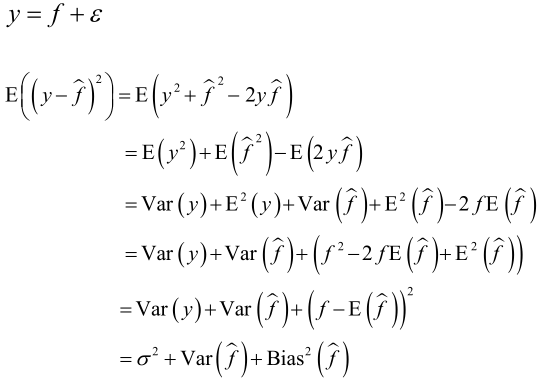
真实的标签值y是由真实的目标函数值(本该预测到的标准的函数f,但实际训练得到的模型是f^,而真实的标签值是y,应该说f和y非常接近)加噪声项,其中噪声项ε服从正态分布N(0, σ2),f^是函数的预测值,E((y-f^)2)是样本真实标签值和预测值的均方误差。
正则化:
机器学习算法要抵抗过拟合问题,过拟合问题是因为模型很复杂所导致的,而模型的复杂度和偏差、方差是有密切关系的。
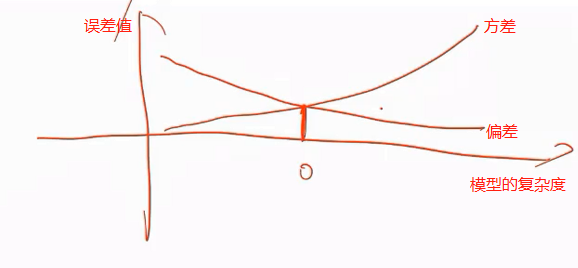
模型越复杂偏差越小,模型越复杂方差越小,需要找一个折中点,使得偏差和方差都比较小,根据这一个指导原则,就诞生了正则化这种技术。
正则化就是对那种复杂的模型进行惩罚,一旦模型f(x; θ)确定之后,能改变的也就是模型的参数,正则化就是控制模型的参数。
对模型进行惩罚,就在它的均方误差后加一个正则化项:
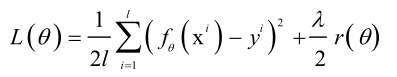
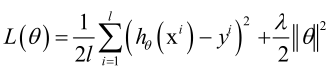
正则化项起到的作用是迫使θ的值比较小,取r(θ)为||θ||2越小模型越简单,这就是L2正则化,也可以用L1正则化,一般L1正则化产生的结果更加稀疏一些。
正则化技术的精髓就是对复杂度模型进行惩罚,迫使在优化的时候不光让前边的目标函数最小化,还要让参数的绝对值平方和最小化,这样就让参数尽可能的小接近于0,这样的话模型就更简单一些。
正则化项的一个具体的例子叫岭回归算法,它就是一个线性回归加上L2的正则化:
先不考虑正则化项,如果只是一个线性回归的损失函数:
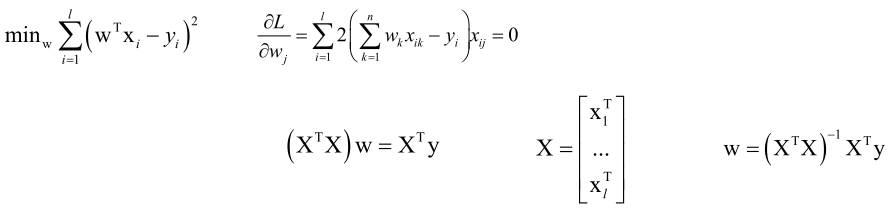
以上就是高等数学中的最小二乘法。
然后加上一个正则化项:
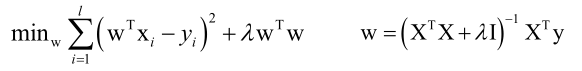
λwTw对w求梯度是2λw,加上正则化项之后对线性回归来说带来什么影响呢?如果λ足够大的话,可以使(XTX+λI)-1为严格对角占优的矩阵(主对角线元素绝对值大于该行其它所有元素之和),只要使严格对角占优矩阵就一定是可逆的。
除了加L2正则化项,还可以加L1正则化项,得到LASSO回归:
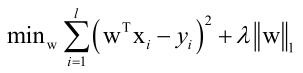
可以证明线性回归加上L2正则化项之后,整个损失函数它还是凸函数,本身线性回归的Hession矩阵半正定,在加上λwTw的Hession矩阵λw,如果λ大于0的话L的Hession矩阵就是严格正定了,所以它是个凸优化问题。
对于L1正则化项的LASSO回归就不能用Hession矩阵算了,只能根据它的严格定义来算,均方误差那一项肯定是半正定的,后边那一项绝对值函数是凸函数,两项加起来之后还是凸函数,所以LASSO回归也是凸优化问题。
由此可看出,线性回归是一个非常好的东西,不管是带L1正则化项还是L2正则化项,它都是一个凸优化问题。在后面一些很多实际的应用中,岭回归和LASSO回归还是会经常被拿来做一些实际的应用的,比如说做目标检测的时候,回归一个目标的位置或者跟踪算法里边,它都用了正则化项的这种线性回归的算法。
本集总结: