Query子类
TermQuery:根据域和关键词进行搜索
/**
* termQuery根据域和关键词进行搜索
*/
@Test
public void termQuery() throws IOException {
//1.创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\Luene资料\Index").toPath());
//2.创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//3.创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//4.创建Query查询对象
Query query=new TermQuery(new Term("fieldContent","spring"));
//5.执行查询,获取到文档对象
TopDocs topDocs = indexSearcher.search(query, 10);
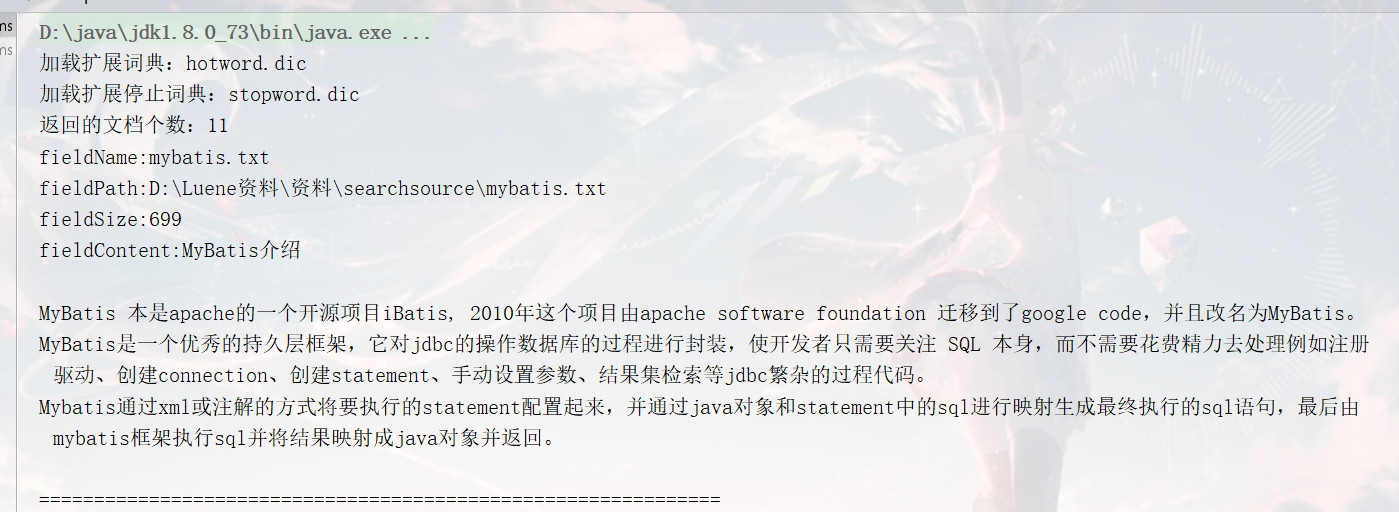
System.out.println("共获取:"+topDocs.totalHits+"个文档~~~~~~~~~~~~~~~~~~~~~");
//6.获取文档列表
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc item:scoreDocs) {
//获取文档ID
int docId=item.doc;
//取出文档
Document doc = indexSearcher.doc(docId);
//获取到文档域中数据
System.out.println("fieldName:"+doc.get("fieldName"));
System.out.println("fieldPath:"+doc.get("fieldPath"));
System.out.println("fieldSize:"+doc.get("fieldSize"));
System.out.println("fieldContent:"+doc.get("fieldContent"));
System.out.println("==============================================================");
}
//7.关闭资源
indexReader.close();
}
结果
RangeQuery:范围搜索
/**
* RangeQuery范围搜素
*/
@Test
public void RangeQuery() throws IOException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\Luene资料\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//设置范围搜索的条件 参数一范围所在的域
Query query= LongPoint.newRangeQuery("fieldSize",0,50);
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
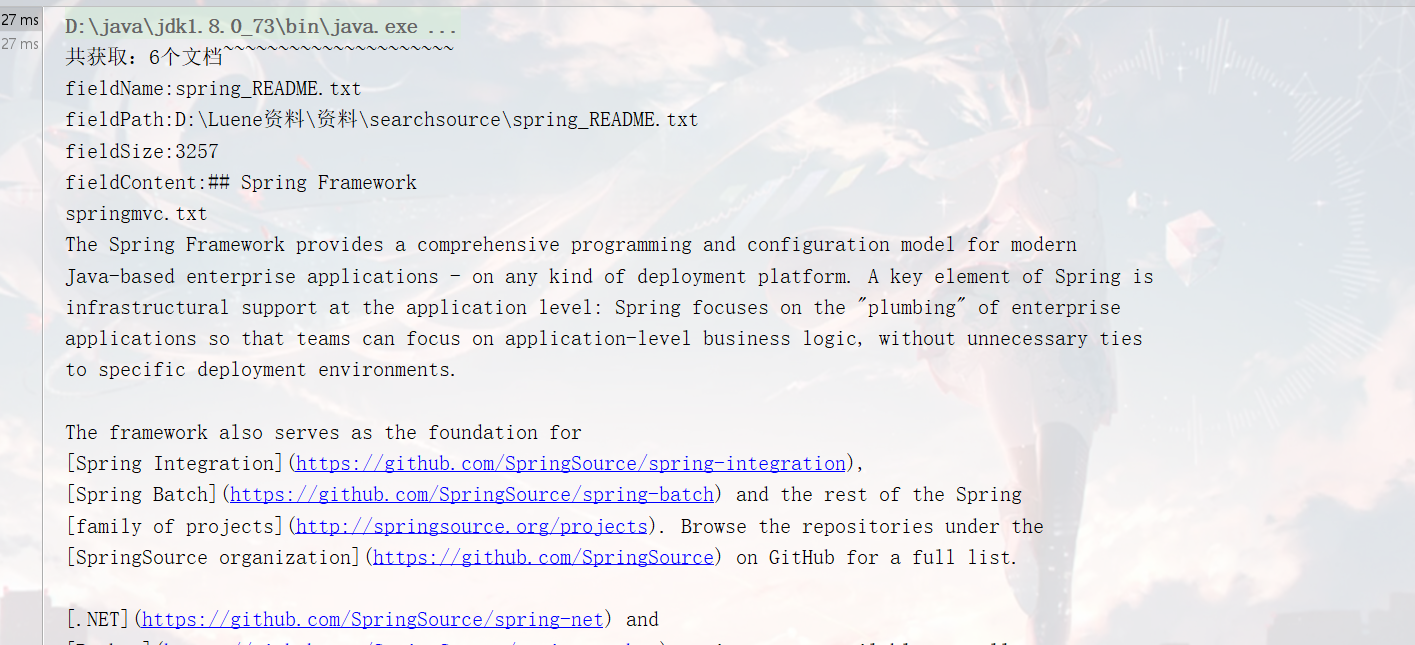
System.out.println("返回的文档个数:"+topDocs.totalHits);
//获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
结果

QueryParser:匹配一行数据,这一行数据会自动进行分词
/**
* queryparser搜素,会将搜索条件分词
*/
@Test
public void queryparser() throws IOException, ParseException {
//创建Directory对象,指定索引库位置
Directory directory = FSDirectory.open(new File("D:\Luene资料\Index").toPath());
//创建IndexReader对象,读取索引库内容
IndexReader indexReader= DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建一个QueryParser对象 参数一:查询的域 参数二:使用哪种分析器
QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer());
//设置匹配的数据条件
Query query = parser.parse("Lucene是一个开源的基于Java的搜索库");
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits);
//获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
结果