抄袭了一片文章,进行少量修改:http://www.gageet.com/2014/09203.php
作者:Christian Szegedy( google ) 刘伟(北卡罗来纳 大学) 贾清扬(Google)
....... (.......)
GoogleNet的研究点是引入了Inception结构,构建网络中的网络,使网络稀疏化,使CNN网络更像一个“神经元-网络”。因此可以实现:看起来更深,其实更稀疏,全局性能更好的网络。在数学上表示为,把稀疏网络转化成局部稠密的网络,加快计算速度。
1.摘要 Abstract:
本文提出了一种新的分类和检测的新网络。该网络最大的特点就是提升了计算资源的利用率。在网络需要的计算不变的前提下,通过工艺改进来提升网络的宽度和深度。最后基于Hebbian Principle( 赫布理论(英语:Hebbian theory) )和多尺寸处理的直觉来提高性能。在ILSVRC-2014中提交了这种网络,叫GoogLeNet有22层。
2.简介 Introduction:
硬件性能的提升是一个主要因素,还有更多的数据集更复杂的模型。更有用的是一系列的想法、算法和网络结构的更新。
在ILSVRC2014上GoogLeNet 只用了比[9](Krizhevsky 两年前)少12倍的参数,但正确率更高。本文最大的工作是通过CNN和普通的计算机视觉结合,类似于R-CNN[6]。因为算法的 ongoing traction of mobile 和嵌入式计算,使算法的效率变得 更高。也导致了本文不会关心绝对的权重比率。
本文将会关注CV的深度神经网络“Inception”。本文既将Inception提升到了一个新的高度,也加深了网络的深度。此文中深度的两个解释:引入一个新的层—以生物学模块的形式——更像一个神经元的结构;并使网络层次直接变深。换句话说,可以把此生物学模块看做 一个逻辑高层, 此方法借鉴于 [2,12] 。
3.近期工作汇总 Related Work:
从最初广泛应用的LeNet-5开始,CNN有了标准结构——堆栈式的卷积层(有选择性的/稀疏 链接层、对比归一化层和 池化层) 随后链接一个或者多个全连接层。这种标准结构天然对应了图像的二维结构,在图像分类上具有优越性。为应对更大的数据集和更广泛的应用场景,主流的方法是通过扩增网络链接层数和 层的大小,并且使用DropOut的方法(网络结构冗余)进行防止网络结构可能出现的过拟合。
尽管CNN的池化层会导致空间精确信息的损失,传统的相似结构的CNN还用来进行定位、检测、人体姿势估计。
[15]用了不同尺寸的固定Gabor滤波器处理缩放问题。GoogLeNet用了很多相同的层,使得总层数共22层。[12]利用Network in Network用来提高神经网络的power,使网络更容易协调。本文用Network in Network有两方面用途,降低维度来降低计算瓶颈(限制了网络的结构增大),也可以提高网络的深度和宽度。
最近主流的目标检测方法是R-CNN(局部感受——CNN),Girshick[6]所提出的R-CNN将检测分解成两部分:在浅层 利用底层信息如颜色、超像素组成的信息 进行 潜在目标检测,再利用深层的CNN进行分类。作者对这种表现良好的方法再进行了一次提高,使用了多 包围盒的方法等。
4.改进和高层优化 Motivation and High Level Considerations:
为提高网络的分类性能,直观的方法是可以使网络更深更大,但这样造成两个问题。复杂模型容易导致过拟合,且训练时间过长增加计算性能的消耗。
其根本的解决办法是将全连接层变为稀疏链接层[2],甚至卷积层也变成稀疏链接。方法的主要描述为:若数据集致使网络极大、极为稀疏,网络构建和训练过程可以逐层进行,通过分析前一层和 有高响应输出的神经元群 的链接关系统计 。
尽管这种关系的成立性证明 需要强假设,但这种描述与生物学的 赫本原理 是一致的,其描述 为神经元具有结群和缠绕特性, 方法原理是 实验性 无误的。
当下,现在的计算结构,对于非均衡的稀疏数据,计算效率不高。(或许需要神经元计算机来进行加速)。卷积可以被视为网络前期的稠密矩阵收集。结构的统一化、更多的滤波器、更大的批处理尺寸 可以用来提高稠密计算。
[3]提出将多个稀疏矩阵 合并成 相关的稠密子矩阵来解决问题。
……
5.框架细节 Architectural Details:
Inception主要的思想就是如何找出最优的局部稀疏结构并将其覆盖为近似的稠密的组件。[2]提出一个层与层的结构,在结构的最后一层进行相关性统计,将高相关性的聚集到一起。这些簇构成下一层的单元,与上一层的单元连接。假设前面层的每个单元对应输入图像的某些区域,这些单元被滤波器进行分组。低层(接近input层)的单元集中在某些局部区域,意味着在最终会得到在单个区域的大量群,他们能在下一层通过1*1卷积覆盖[12]。然而也可以通过一个簇覆盖更大的空间来减小簇的数量。
为了避免patch-alignment问题,现在滤波器大小限制在1*1,3*3和5*5(主要是为了方便也非必要)。在pooling层添加一个备用的pooling路径可以增强效率。
Inception模块都堆在其他Inception模块的上面(层层堆叠),……
上述模块一个巨大的问题就是,即使是一个合适数量的卷积,也会因为大量的滤波而变得特别expensive。经过pooling层输出的合并,最终可能会导致数量级增大不可避免。处理效率不高导致计算崩溃。
第二种方法:在需要大量计算的地方进行慎重的降维。压缩信息以聚合。1*1卷积不仅用来降维,还用来修正线性特性。
只在高层做这个,底层还是普通的卷积。
GoogleLenet:
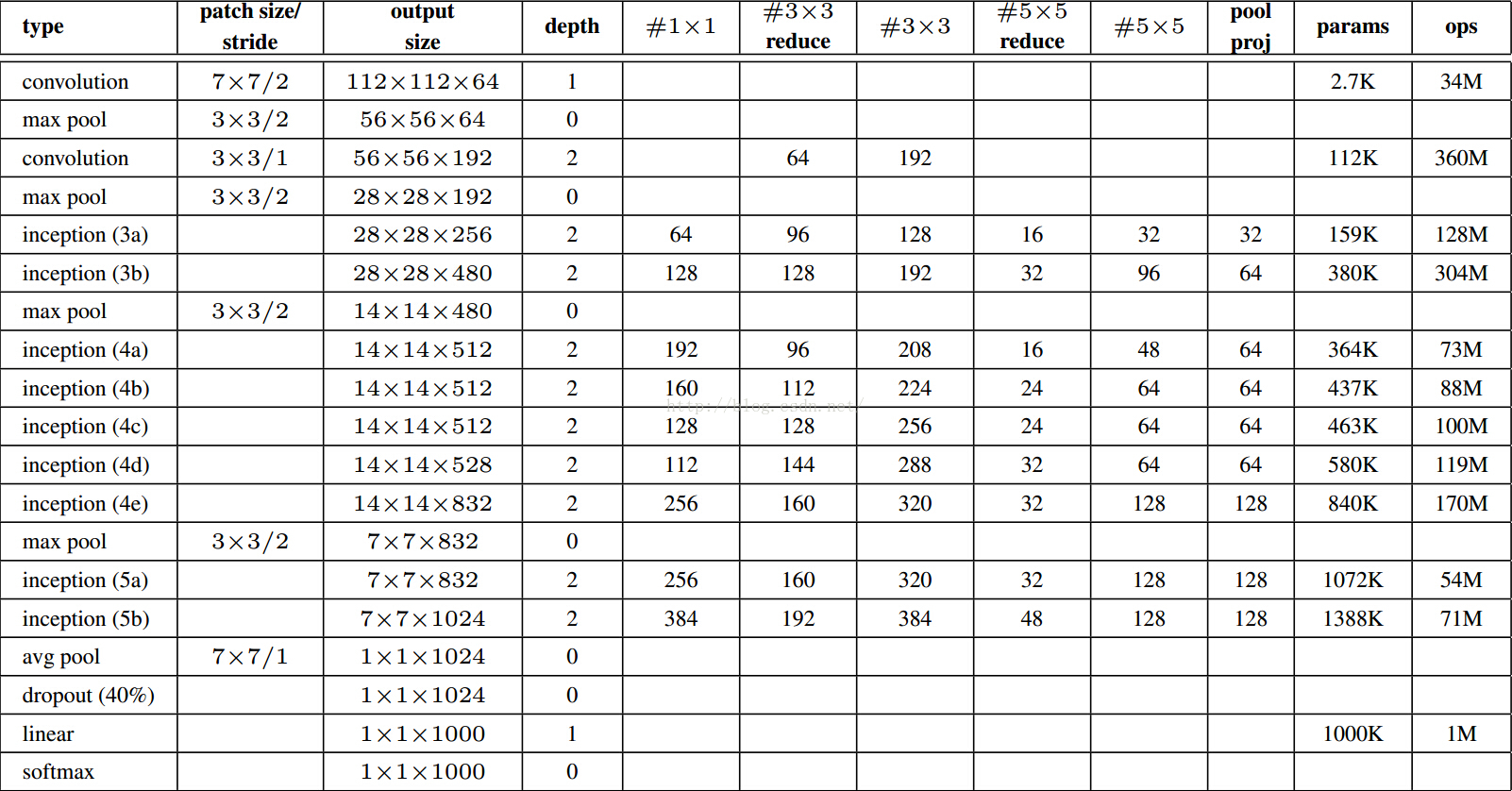
#3*3 reduce代表3*3卷积前1*1滤波器的个数。所有的reduction/projection层都利用了修正线性激活。网络包含22层带参数层和5层不含参数的pooling层。总共有约100层。分类前的pooling是基于[12],只是我们利用了不同的线性层。有利于精细的调节网络,但不期望它有多出色。从全连接层move到下采样会将Top1准确率提高0.6%,但是dropout仍然需要。
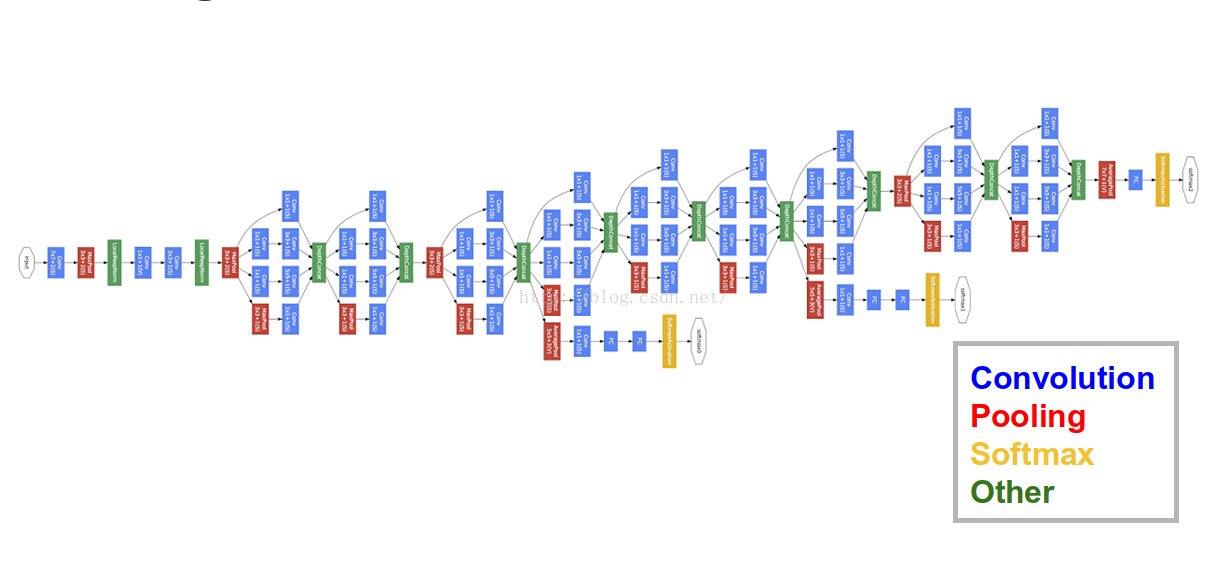
图:
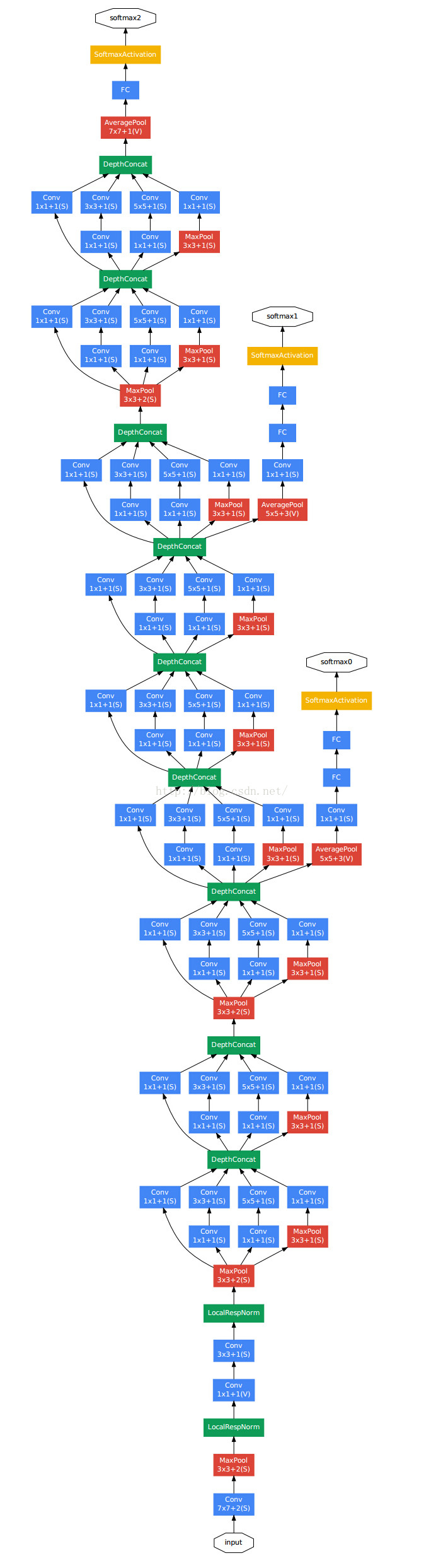
Figure 3: GoogLeNet network with all the bells and whistles
• A 1*1 convolution with 128 filters for dimension reduction and rectified linear activation. 128个1*1的卷积网络,用于降维和线性激活
• A fully connected layer with 1024 units and rectified linear activation. 一个1024个单元的全连接层
• A dropout layer with 70% ratio of dropped outputs. 70%的随机丢弃—意味着70%的网络冗余
• A linear layer with softmax loss as the classifier (predicting the same 1000 classes as themain classifier, but removed at inference time).SoftMax 损失层
在浅层网络来说,相对中间的网络产生的特征非常有辨识力。在这些层中增加一些额外的分类器,能个增加BP的梯度信号和提供额外的正则化。这些分类器将小的卷积网络放在4a和4b的输出上。在训练过程中,损失会根据权重叠加,而在测试时丢弃。
6.Training Methodology:
训练速率:
利用[4]-DistBelief提供的分布式机器学习系统和数据平行。用数个高端GPU,一周达到收敛,短板在于内存。利用[17]异步随机梯度下降,0.9动量,学习率每八个周期下降4%。最后用Polyak averaging [13]来创建最后用来测试的模型。
采样变化/扰动 很大,其中几个月的时间联合调节一些超参数、比如 丢弃 和学习速率,没有一个普遍的指导性原则用于 有效的训练网络。发现:[8]的光度扭曲(添加灰度值干扰/滤波)有助于对付过拟合。还进行了随机插入(bilinear, area, nearest neighbor and cubic, with equal probability),同时并不能准确确定哪些因素影响了最终结果。
7.ILSVRC 2014 Classification Challenge Setup and Results:
①训练了7个版本的 GoogleLeNet 网络,初始化方式保证相同,只是采样方法和随机输入图像不同,取综合值。
②将图像的短边缩放成4中:256,288,320,352。取图像的上中下块。每块取四个角、中间的224*224和将其缩放到224*224以及它们的镜像。结果是4*3*6*2=144,即每个图像采样144块输入图。但可能实际生产中不能应用。
③ 使用maxpooling 和 在分类器平均,最后的结果都不如简单的平均好。
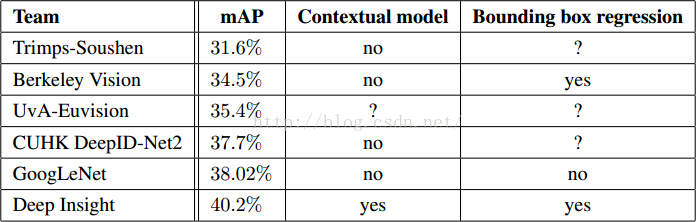
表 2
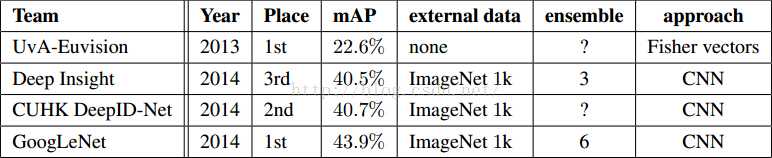
表2
7.ILSVRC 2014 Detection Challenge Setup and Results
方法与[6]的R-CNN很像,但增加了Inception模块。结合了用multi-box [5] 的方法和Selective Search [20] 来提高定位框的召回率。这让从Selective Search [20] 得到的结果减半。再加上200个[6]的方法,总共[6]占60%,可以将覆盖率从92%提高到93%。上述方法可以将准确率相对单一模型提高1%。在分类区域的时候利用6个卷积网络科将准确率从40%提高到43.9%。
表4最后GoogLeNet最好,比去年大了接近一倍。表5表示GoogLeNet在单模型的情况下,只比最好的低0.3%,但那个用了3个模型,而GoogLeNet在多模型的情况下结果好得多。
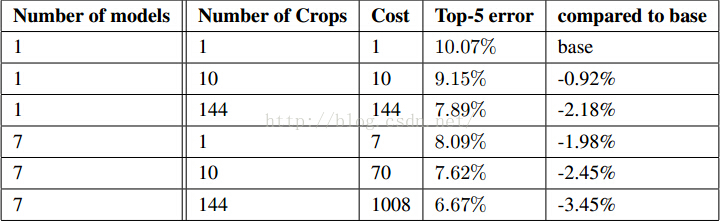
表4
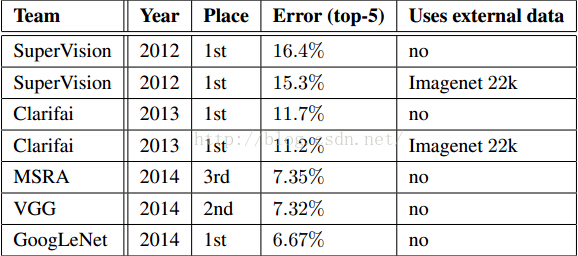
表5
Conclusions
将最佳稀疏结构稠密化是一种有效提高CV神经网络的方法。优点是只适度增加计算量。本文检测方法不利用上下文,不会定位框回归,证明了Inception方法的强壮。本文提供了一个将稀疏变稠密的途径。
[2] Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.
[6] Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition, 2014. CVPR 2014. IEEE Conference on, 2014.
[9] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep con-volutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[12] Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013.
[15] Thomas Serre, Lior Wolf, Stanley M. Bileschi, Maximilian Riesenhuber, and Tomaso Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411–426, 2007.