原文:计算机视觉识别简史:从 AlexNet、ResNet 到 Mask RCNN
总是找不到原文,标记一下。
一切从这里开始:现代物体识别随着ConvNets的发展而发展,这一切始于2012年AlexNet以巨大优势赢得ILSVRC 2012。请注意,所有的物体识别方法都与ConvNet设计是正交的(任意ConvNet可以与任何对象识别方法相结合)。 ConvNets用作通用图像特征提取器。
2012年 AlexNet:AlexNet基于有着数十年历史的LeNet,它结合了数据增强、ReLU、dropout和GPU实现。它证明了ConvNet的有效性,启动了ConvNet的光荣回归,开创了计算机视觉的新纪元。

RCNN:基于区域的ConvNet(RCNN)是启发式区域提案法(heuristic region proposal method)和ConvNet特征提取器的自然结合。从输入图像,使用选择性搜索生成约2000个边界框提案。这些被推出区域被裁剪并扭曲到固定大小的227x227图像。 然后,AlexNet为每个弯曲图像提取4096个特征(fc7)。然后训练一个SVM模型,使用4096个特征对该变形图像中的对象进行分类。并使用4096个提取的特征来训练多个类别特定的边界框回归器来改进边界框。

OverFeat:OverFeat使用AlexNet在一个输入图像的多个层次下的多个均匀间隔方形窗口中提取特征。训练一个对象分类器和一个类别不可知盒子回归器,用于对Pool5层(339x339接收域窗口)中每5x5区域的对象进行分类并对边界框进行细化。OverFeat将fc层替换为1x1xN的卷积层,以便能够预测多尺度图像。因为在Pool5中移动一个像素时,接受场移动36像素,所以窗口通常与对象不完全对齐。OverFeat引入了详尽的池化方案:Pool5应用于其输入的每个偏移量,这导致9个Pool5卷。窗口现在只有12像素而不是36像素。
2013 年 ZFNet:ZFNet 是 ILSVRC 2013 的冠军得主,它实际上就是在 AlexNet 的基础上做了镜像调整(mirror modification):在第一个卷积层使用 7×7 核而非 11×11 核保留了更多的信息。
SPPNet:SPPNet(Spatial Pyramid Pooling Net)本质上是 RCNN 的升级,SFFNet 引入了 2 个重要的概念:适应大小池化(adaptively-sized pooling,SPP 层),以及对特征量只计算一次。实际上,Fast-RCNN 也借鉴了这些概念,通过镜像调整提高了 RCNN 的速度。
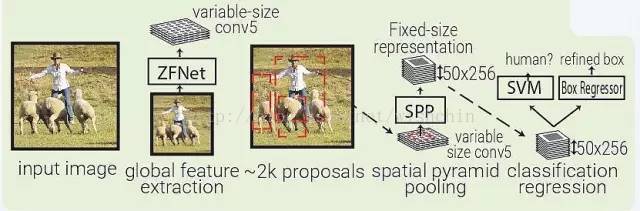
SPPNet 用选择性搜索在每张图像中生成 2000 个区域(region proposal)。然后使用 ZFNet-Conv5 从整幅图像中抓取一个共同的全体特征量。对于每个被生成的区域,SPPNet 都使用 spatial pyramid pooling(SPP)将该区域特征从全体特征量中 pool 出来,生成一个该区域的长度固定的表征。这个表征将被用于训练目标分类器和 box regressor。从全体特征量 pooling 特征,而不是像 RNN 那样将所有图像剪切(crops)全部输入一个完整的 CNN,SPPNet 让速度实现了 2 个数量级的提升。需要指出,尽管 SPP 运算是可微分的,但作者并没有那么做,因此 ZFNet 仅在 ImageNet 上训练,没有做 finetuning。

MultiBox:MultiBox 不像是目标识别,更像是一种基于 ConvNet 的区域生成解决方案。MultiBox 让区域生成网络(region proposal network,RPN)和 prior box 的概念流行了起来,证明了卷积神经网络在训练后,可以生成比启发式方法更好的 region proposal。自此以后,启发式方法逐渐被 RPN 所取代。MultiBox 首先将整个数据集中的所有真实 box location 聚类,找出 200 个质心(centroid),然后用将其用于 prior box 的中心。每幅输入的图像都会被从中心被裁减和重新调整大小,变为 220×220。然后,MultiBox 使用 ALexNet 提取 4096 个特征(fc7)。再加入一个 200-sigmoid 层预测目标置信度分数,另外还有一个 4×200-linear 层从每个 prior box 预测 centre offset 和 box proposal。注意下图中显示的 box regressors 和置信度分数在看从整幅图像中抓取的特征。
2014 年 VGGNet:虽然不是 ILSVRC 冠军,VGGNet 仍然是如今最常见的卷积架构之一,这也是因为它简单有效。VGGNet 的主要思想是通过堆叠多层小核卷积层,取代大核的卷积层。VGGNet 严格使用 3×3 卷积,步长和 padding 都为1,还有 2×2 的步长为 2 的 maxpooling 层。

2014 年 Inception:Inception(GoogLeNet)是2014 年 ILSVRC 的冠军。与传统的按顺序堆叠卷积和 maxpooling 层不同,Inception 堆叠的是 Inception 模块,这些模块包含多个并行的卷积层和许多核的大小不同的 maxpooling 层。Inception 使用 1×1 卷积层减少特征量输出的深度。目前,Inception 有 4 种版本。
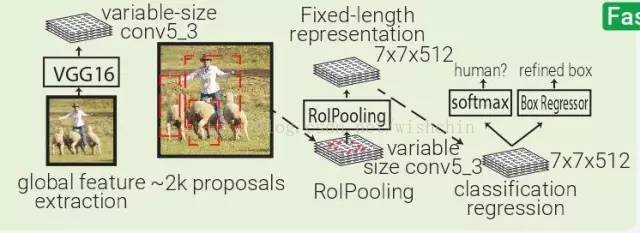
Fast RCNN:Fast RCNN 本质上 SPPNet,不同的是 Fast RCNN 带有训练好的特征提取网络,用 RolPooling 取代了 SPP 层。
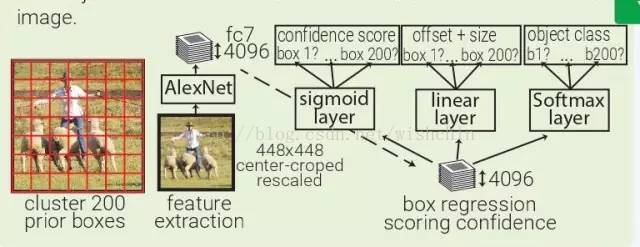
YOLO:YOLO(You Only Look Once)是由 MultiBox 直接衍生而来的。通过加了一层 softmax 层,与 box regressor 和 box 分类器层并列,YOLO 将原本是区域生成的 MultiBox 转为目标识别的方法,能够直接预测目标的类型。
2015 ResNet:ResNet以令人难以置信的3.6%的错误率(人类水平为5-10%)赢得了2015年ILSVRC比赛。ResNet不是将输入表达式转换为输出表示,而是顺序地堆叠残差块,每个块都计算它想要对其输入的变化(残差),并将其添加到其输入以产生其输出表示。这与boosting有一点关。
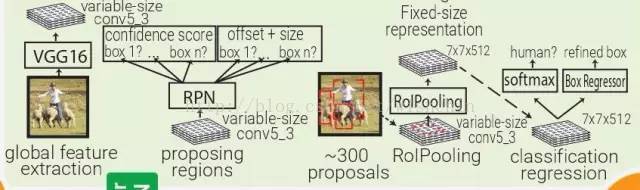
Faster RCNN:受 Multibox 的启发,Faster RCNN 用启发式区域生成代替了区域生成网络(RPN)。在 Faster RCNN 中,PRN 是一个很小的卷积网络(3×3 conv → 1×1 conv → 1×1 conv)在移动窗口中查看 conv5_3 全体特征量。每个移动窗口都有 9 个跟其感受野相关的 prior box。PRN 会对每个 prior box 做 bounding box regression 和 box confidence scoring。通过结合以上三者的 loss 成为一个共同的全体特征量,整个管道可以被训练。注意,在这里 RPN 只关注输入的一个小的区域;prior box 掌管中心位置和 box 的大小,Faster RCNN 的 box 设计跟 MultiBox 和 YOLO 的都不一样。

2016 年 SSD:SSD 利用 Faster RCNN 的 RPN,直接对每个先前的 box 内的对象进行分类,而不仅仅是对对象置信度(类似于YOLO)进行分类。通过在不同深度的多个卷积层上运行 RPN 来改善前一个 box 分辨率的多样性。
2017 年 Mask RCNN:通过增加一支特定类别对象掩码预测,Mask RCNN 扩展了面向实例分割的Faster RCNN,与已有的边界框回归量和对象分类器并行。由于 RolPool 并非设计用于网络输入和输出间的像素到像素对齐,MaskRCNN 用 RolAlign 取代了它。RolAlign 使用了双线性插值来计算每个子窗口的输入特征的准确值,而非 RolPooling 的最大池化法。