论文地址: https://pdos.csail.mit.edu/6.824/papers/gfs.pdf
为了满足 google快速增长的数据处理需求,我们设计实现了 google文件系统(GFS)。GFS 与传统的分布式文件系统具有很多相同的目标比如性能、可扩展性、可靠性、可用性.
设计
GFS主要为大文件设计, 想到一个小文件系统, 淘宝文件系统(TFS), 后面有空研究对比一下.
假设
- 系统由廉价的服务器组合而成, 失败是常事, 必须由系统进行处理
- 系统主要存储大文件, 以chunk的方式存储, 默认64MB, 也支持小文件
- 读操作主要分为2种: 大的顺序读, 小的随机读
- 写操作主要分为2种: append, 随机写
- 持续的高带宽比低延时更重要.
架构
介绍以下几个概念
Master: 整个集群有一台Master服务器, 所有的元数据保存在这里, 有操作日志, 配有影子服务器, 保证Master的可用性. 存储了3个主要类型的元数据, 文件和chunk namespace, 文件到chunk的映射信息, 每个chunk备份的位置. 元数据保存在内存中, 前2种可以通过日志进行恢复, chunk位置通过启动Master时轮询chunkserver得到.
ChunkServer: 文件以chunk的形式保存, 默认64MB. 每个chunk默认保存3份在不同的chunkserver上, 这个值可以根据namespace进行配置.
GFS Clinet: 提供了一套API供应用程序调用, 包括常用的文件操作: create, delete, open, close, read, write. 还具有snapshot和append操作. snapshot以很低的开销创建一个文件或者目录树的拷贝. append允许多个client同时向一个文件写入.
租约管理
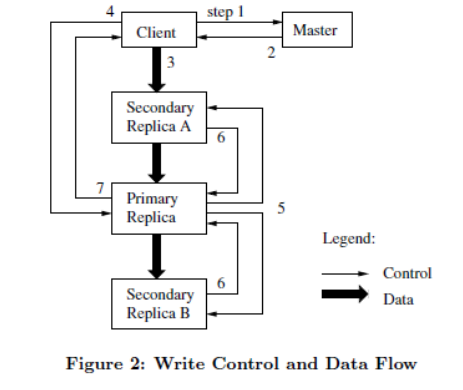
当需要修改一个文件的内容或者元数据时, 需要租约来确定一个主副本, 由主副本来指定多个变更的顺序, 其他副本按照这个顺序来执行变更, 保证副本的一致性.
整个过程, client与master只做一次交互, 即拿到所有副本的chunk信息, 其他的操作都是与chunkserver进行, 操作分为2种, control和data, 注意data的传送不是以client向多个chunkserver传送的方式, 这种方式会造成client 3倍的上行带宽且对不同子网间的速度有要求, GFS采用的是链路的方式, 由client发送数据到最近的chunkserver, 再由这台server逐个向相近的chunkserver发送数据, 这样减少了单点输出数据的带宽影响, 且利用了网络距离的优势. 真是不错的设计, 如下图:
垃圾回收
文件删除后, GFS不立即释放可用的物理存储. 它根据文件和chunk的映射, 可以确定哪些是垃圾chunk, 等到垃圾回收程序运行时, 再统一进行回收. 这样系统会更简单更可靠.