第5章, 复制.
概览
几个问题
- 复制会有多台服务器, 就有主次之分. 单主, 多主, 无主?
- 复制是采用同步还是异步?
- 复制是为可用性做准备, 主库宕机, 如何切换, 从库宕机, 如何追赶?
- 复制的实现方式, 是基于语句的复制, 还是基于行的复制?
- 复制是有延时的, 读写是否分离, 如何避免幻读?
复制会有多台服务器, 就有主次之分. 单主, 多主, 无主?
单主, 数据只会写入一个主服务器, 主服务器会将数据变化发给所有的从服务器, 数据可以从主服务器读取, 也可从从服务器读取.
多种数据库内置这种模式, PostgreSQL, MySQL, Oracle Data Guard, SQL Server的AlwaysOn, MongoDB, RethinkDB, Espresso. 还有Kafka, RabbitMQ等.
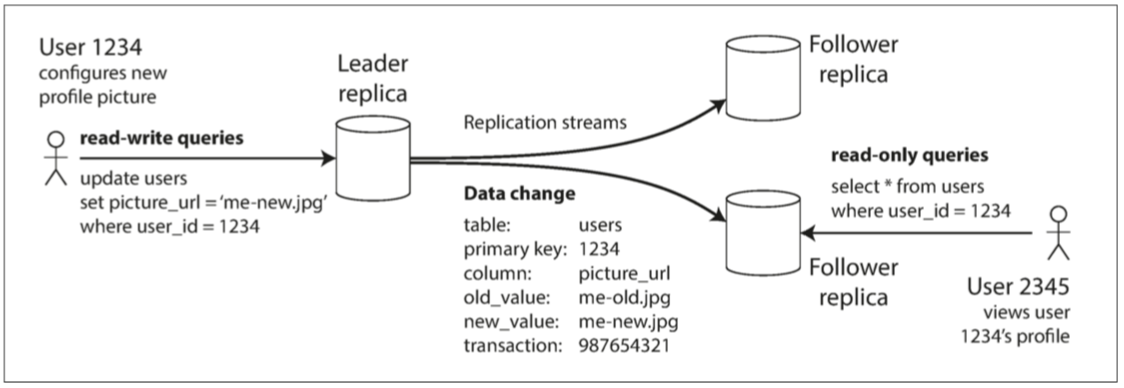
多主, 在单个数据中心内部使用多主比较少见, 一般用于跨数据中心的场景. 多个主库都可以允许写入数据, 然后主库之间进行数据同步.

无主, 每个库都允许写入和读取, 每次写入都需要写入到多个库, 读取也要读多个库, 其中写入成功 + 读取成功 > 总库数才能保证读到最新版本的数据.
读取到旧数据后, 会将新数据更新到旧库保证数据统一性.
主要了解单主的情况即可. 后面几个问题主要分析单主的情况.
复制是采用同步还是异步?
同步的好处是能实时确定执行失败还是成功, 从库数据能实时保持最新, 坏处是如果从库未响应, 会阻塞主服务器. 异步的话, 好的情况下延迟1秒左右, 不好的情况下延迟几分钟或者几小时都有可能.
所有的从库都采用同步不现实, 两种实现
- 单个从库同步, 其他从库异步
- 所有从库异步.
一般采用第2种实现
复制是为可用性做准备, 主库宕机, 如何切换, 从库宕机, 如何追赶?
从库宕机比较简单, 先确定从库的恢复进度, 然后继续后面的恢复即可.
主库宕机比较麻烦, 可以采用手动切换和自动切换两种方式.
自动切换有以下几个步骤:
- 确定主库失效, 一般用超时来判断, 如超时30秒判断宕机. 对库采用心跳检测的方式, 定时执行查询, 超时则判断宕机.
- 选择新的主库.
- 重新配置系统以使用新的主库, 让写操作执行到新的主库, 其他从库从新主库进行复制.
复制的实现方式, 是基于语句的复制, 还是基于行的复制?
基于语句的复制, 主库记录所有的写入语句, 发送给从库, 从库执行这些语句. 有几个问题:
- 非确定性函数导致主从不一致, 例如now(), rand()等
- 自增列在并发条件下不一致
- 有副作用的语句可能不一致, 如触发器, 存储过程, 用户定义的函数等
基于行的复制, 用一个特殊的逻辑日志存储写入记录:
- 对于插入的行, 日志包含所有列的新值, 包括自增列
- 对于删除的行, 日志包含足够的信息来唯一标识已删除的行. 通常是主键, 如果没有主键, 则记录所有列
- 对于更新的行, 日志包含足够的信息来唯一标识更新的行, 及所有列的新值
MySQL的binlog是这样的实现方式.
传输预写式日志(WAL)
- 日志结构存储引擎, 如SSTables和LSM树, 存储日志
- 对于覆写单个磁盘块的B树, 每次修改都先写入预写式日志(Write Ahead Log), 以便崩溃后索引可以恢复.
PostgreSQL和Oracle使用这种方式, 缺点是日志记录的数据非常底层, WAL包含哪些磁盘块中的哪些字节发生了更改. 使得复制与存储引擎紧密偶尔, 使得从库必须与主库拥有同样的存储引擎版本, 导致从库升级必须要停机升级.
复制是有延时的, 读写是否分离, 如何避免幻读?
从库的延迟, 从1秒到几分钟甚至几小时都有可能, 看应用场景, 如何不介意延迟时间, 那么从库读是完全可以的, 否则可以采用以下方法:
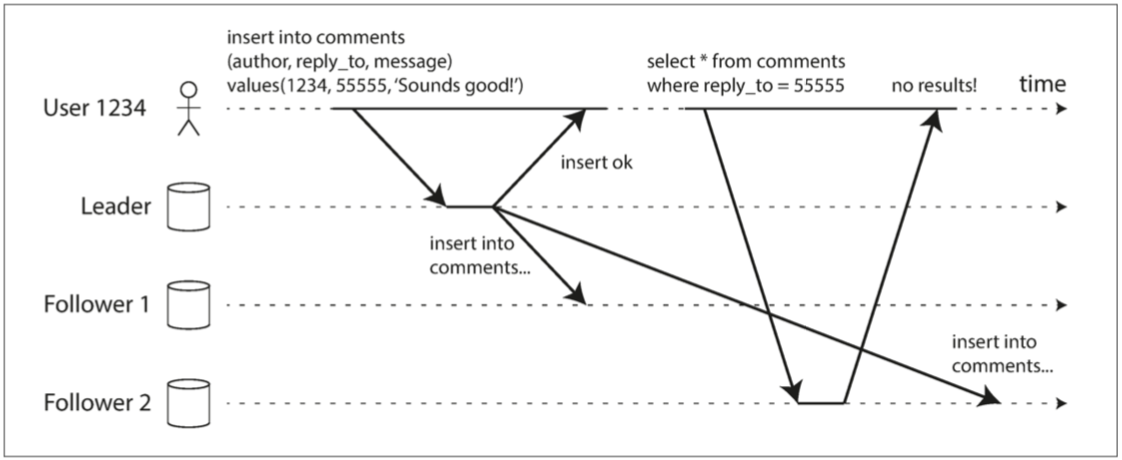
读己之写
又称读写一致性, 保证用户重新加载, 可以看到自己提交的内容正确的更新, 别人提交的内容可能延后更新.
单调读
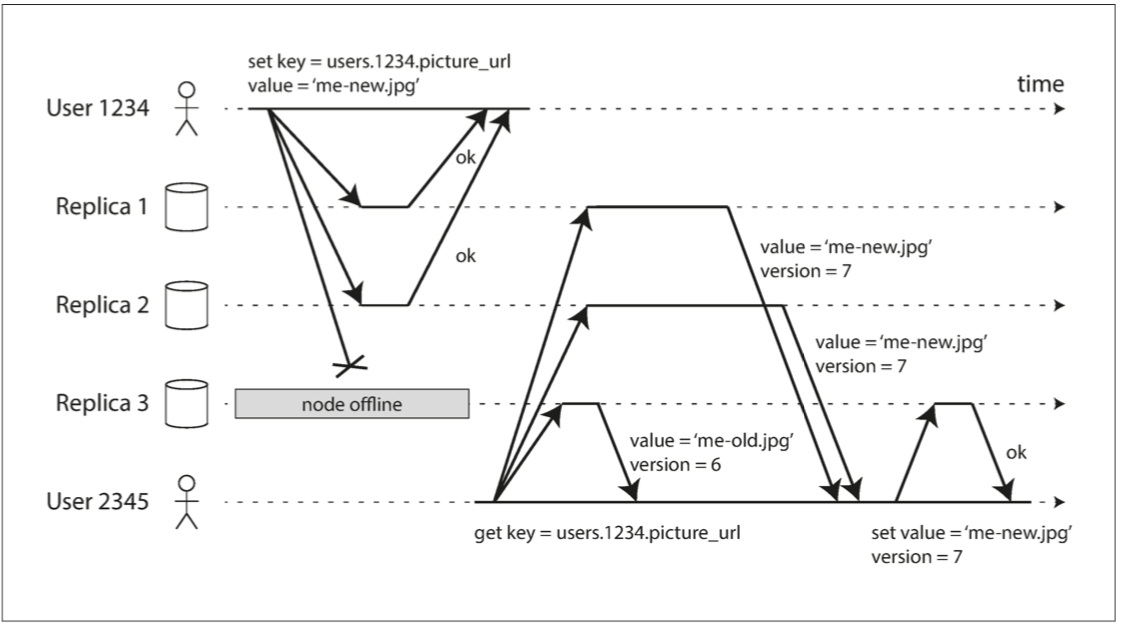
单调读, 保证如果一个用户顺序地进行多次读取,则他们不会看到时间后退,即,如果先前读取到较新的数据,后续读取不会得到更旧的数据.
读多个从库时会发生, 时光倒流现象, 先查了一个延迟较小的库, 看到了新加数据, 再刷新页面, 查了一个延迟较大的库, 新加数据没了, 就比较困惑.

一种解决方式是, 确保每个用户总是从同一个副本进行读取(不同的用户可以从不同的副本读取)。例如,可以基于用户ID的散列来选择副本,而不是随机选择副本
一致性前缀读
一致性前缀读, 保证如果一系列写入按某个顺序发生,那么任何人读取这些写入时,也会看见它们以同样的顺序出现.
这在分区数据库中发生, 不同的分区独立运行,因此不存在全局写入顺序:当用户从数据库中读取数据时,可能会看到数据库的某些部分处于较旧的状态,而某些处于较新的状态.
一种解决方式是, 确保任何因果相关的写入都写入相同的分区.