- 导读
- 一、数据标注
- 二、模型评价
- 三、源码解读
- 四、Libtorch部署
- 五、性能分析
- 六、问题记录
导读
U2-Net模型分为两种:
- U2NET---173.6 MB (参数量:4千万)
- U2NEP---4.7 MB (参数量:1 百万)
(5s为700万个参数,VGG-16有4000万,ResNet 1.3亿个参数)
项目地址:https://github.com/xuebinqin/U-2-Net
1、人类分割模型:u2net_human_seg.pth ,下载上述模型到文件夹下./saved_models/u2net_human_seg/,没有就自己建,
2、把图片复制到./test_data/test_human_images/ 目录下
3、运行脚本python u2net_human_seg_test.py,效果图自动保存在./test_data/u2net_test_human_images_results/
(注:这个模型训练的时候(基于U2Net做了一些改进,比如数据增强),样本标注精度不是那么高,但是也比官方U2Net基于DUST-TR数据集训练得出的效果好,话说回来
这个模型用于通用人类检测分割,效果也是很牛逼,这个模型是基于数据集(Supervisely Person Dataset)预训练,数据集由5711张图片组成,有6884个高质量的标注的人体实例)
有很多人将U2-Net活学活用,比如:人类肖像绘画[1],素描,去除背景等等。其余的不多逼逼,自己去看github介绍
咱们这里仅讨论语义分割,不是实例分割。
一、数据标注
labelImg,标注完是json格式,自己完成json文件 -> mask图片功能
U2-Net主要测试多组数据集:
训练数据集:在DUTS-TR上训练的网络,它是DUTS数据集的一部分。DUTS-TR包含共10553张图片。目前,它是最大的用于显著目标检测的常用训练数据集。训练之前,做了平翻转来扩充这个数据集,也就是21106张图像。
评估数据集:六个常用测试数据集用于测试我们的模型,包括:DUT-OMRON、DUTS-TE、HKU-IS、ECSSD,PASCAL-S,SOD。
DUT-OMRON:包括5168图像,其中大多数包含一个或多个前景。
DUTS:数据集由两部分组成:DUTS-TR(训练集)和DUTS-TE(测试集)。DUTS-TE有5019张图像,用于测试。
HKU-IS:有4447张图片,其中有多张图片地面物体。ECSSDContains1000结构复杂图像和其中许多包含大型前景对象。
PASCAL-S:包含850幅前景复杂的图像物体和杂乱的背景。草皮只含300图像。但这是一个巨大的挑战。因为它本来就是专为图像分割而设计,很多图像都很低对比度或包含重叠的复杂前景对象图像边界。
SOD:只含300图像。但这是一个巨大的挑战。因为它本来就是专为图像分割而设计,很多图像都很低对比度或包含重叠的复杂前景对象
二、模型评价(请参考原文)
2.1、损失函数
首先讨论语义分割的loss计算,其实就是逐像素计算交叉熵,(二分类:语义分割,多分类:实例分割),
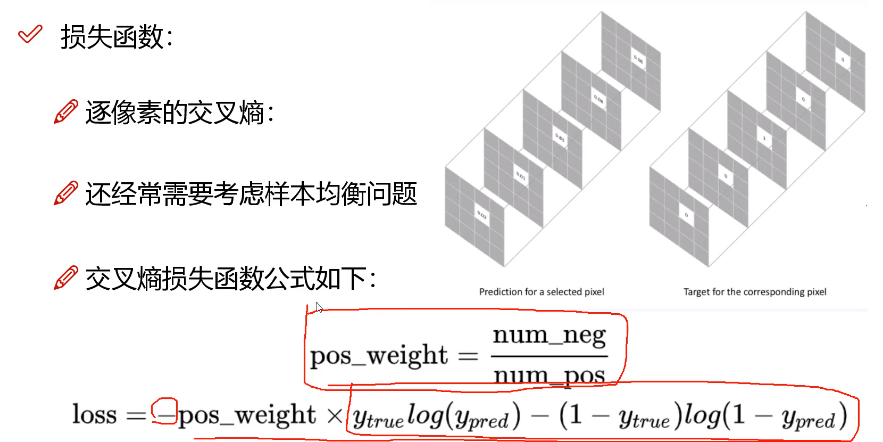
上式中,权重项pos_weight作用是:平衡正负样本不均衡问题,YOLOV1目标函数中有提过,不多说。下面只讨论语义分割,不讨论实例分割。
在计算loss过程中,都是逐像素计算loss,进行二分类。但是,对于一个区域分割、识别,边界外边的是负样本(背景),边界里边的是正样本(前景),一般都很好区分,唯独边界上的像素难以区分,那怎么解决呢?请看下面Focal loss类型损失函数。
下式中的r(读:gamma),一般取值2,例如:当正样本标注概率为0.95的时候,采用公式(1 - p)^r降低其概率值为0.0025,这么做的初衷是:希望这种容易识别的样本像素别对最终模型产生太大贡献;再如:像素标注概率为0.5的时候,同理得出概率值为0.25,意思是:本来0.5就不高,降为0.25,相对前面0.0025,对网络贡献大得多,那么网络会对“概率为0.5”这类不易识别的像素更加重视。
下图最后一个公式中α = 负样本/正样本

2.2、评价指标
IOU:如下图右边,Y轴表示标注类别,X轴表示网络预测类别,中间网络中数字表述各类别像素数量。例如:绿色框表示当前标注区域ROI1(记为true_dog)包含像素总数,黄色框表示预测区域ROI2(记为predict_dog)像素总数,所以iou_dog计算公式如下:
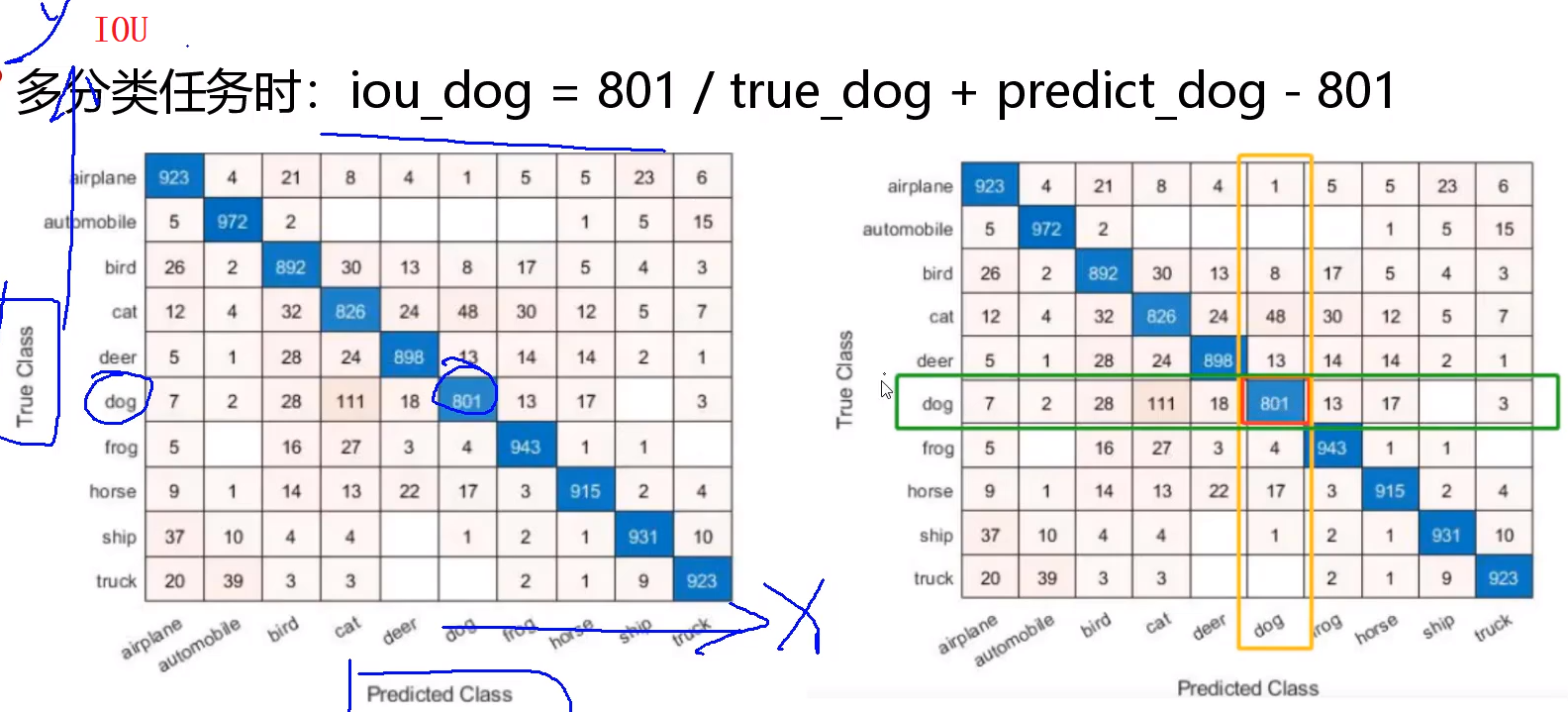
如下图,坐标是人像标注区域,右边是模型预测区域。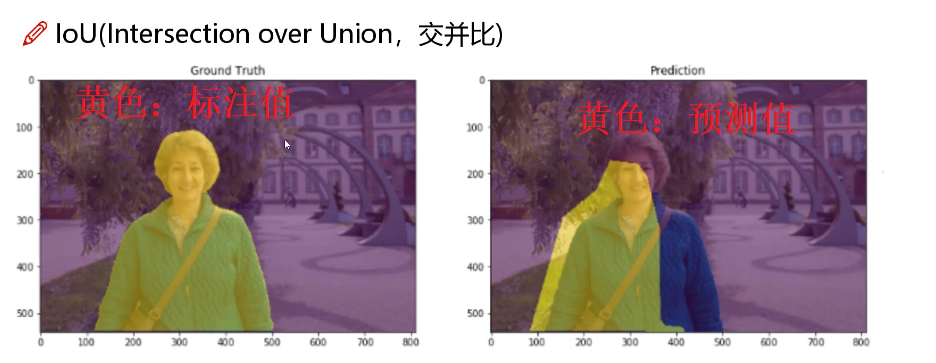
下面左图就是上述两图的交基、并集。

一般地,在实例分割中,多余多个类别:a、b、c等类别,会分别计算IOU,然后取平均值,得到MIOU
在U2-Net中(注:咱们这里不是实例分割!),有如下评价指标:
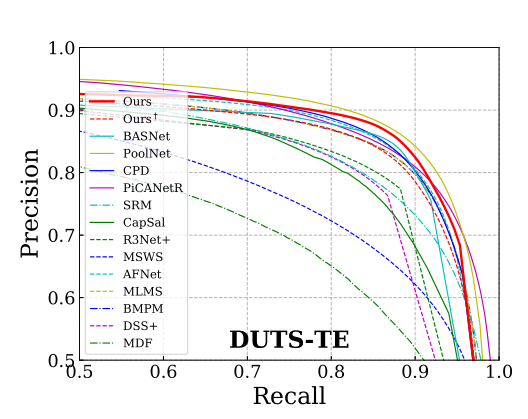
PR curve:通过对比网络输出Mask和标记图Mask,计算acc(TP/(TP + FP))、recall(TP/(TP+FN))
MAE: Mean Absolute Error,平均结对
![]() 还有几个懒得讲。
还有几个懒得讲。
三、源码解读
3.0、环境:pytoch1.7.1_cu110(和yolov5.4环境一样,直接拿来用,pytorch1.7.1+CU11.0)
3.1、准备工作
下载源码:git clone https://github.com/NathanUA/U-2-Net.git
下载预训练模型: u2net.pth (176.3 MB) or u2netp.pth (4.7 MB) 分别放到 './saved_models/u2net/' and './saved_models/u2netp/'文件夹下面,没有就自己建
训练与测试:python u2net_train.py or python u2net_test.py
3.2、训练代码解读
u2net_train.py(遇到报错请参考第六节、问题记录,我这里已经改好了):


1 import os 2 3 os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # OMP:Error 4 import torch 5 from torch.autograd import Variable 6 import torch.nn as nn 7 8 from torch.utils.data import DataLoader 9 from torchvision import transforms 10 import torch.optim as optim 11 12 import glob 13 import os 14 15 from data_loader import RescaleT 16 from data_loader import RandomCrop 17 from data_loader import ToTensorLab 18 from data_loader import SalObjDataset 19 20 from model import U2NET 21 from model import U2NETP 22 23 # ------- 1. define loss function -------- 24 25 bce_loss = nn.BCELoss(size_average=True) 26 27 # loss1-6:输出层上采样得到6张图,对应的loss 28 # loss0:最终特征图的loss 29 def muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v): 30 loss0 = bce_loss(d0, labels_v) 31 loss1 = bce_loss(d1, labels_v) 32 loss2 = bce_loss(d2, labels_v) 33 loss3 = bce_loss(d3, labels_v) 34 loss4 = bce_loss(d4, labels_v) 35 loss5 = bce_loss(d5, labels_v) 36 loss6 = bce_loss(d6, labels_v) 37 38 loss = loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6 39 print("l0: %3f, l1: %3f, l2: %3f, l3: %3f, l4: %3f, l5: %3f, l6: %3f " % ( 40 loss0.data.item(), loss1.data.item(), loss2.data.item(), loss3.data.item(), loss4.data.item(), loss5.data.item(), 41 loss6.data.item())) 42 43 return loss0, loss 44 45 46 # ------- 2. set the directory of training dataset -------- 47 48 model_name = 'u2net' # 'u2netp' 49 50 data_dir = os.path.join(os.getcwd(), 'train_data' + os.sep) 51 # tra_image_dir = os.path.join('DUTS', 'DUTS-TR', 'DUTS-TR', 'im_aug' + os.sep) 52 # tra_label_dir = os.path.join('DUTS', 'DUTS-TR', 'DUTS-TR', 'gt_aug' + os.sep) 53 54 tra_image_dir = os.path.join('APDrawingGAN_test', 'im' + os.sep) 55 tra_label_dir = os.path.join('APDrawingGAN_test', 'gt' + os.sep) 56 57 image_ext = '.jpg' 58 label_ext = '.png' 59 60 model_dir = os.path.join(os.getcwd(), 'saved_models', model_name + os.sep) 61 62 #epoch_num = 100000 63 # batch_size_train = 12 # error: RuntimeError: CUDA out of memory. 64 epoch_num = 4000 65 batch_size_train = 4 # 8G显存有点不够用 66 batch_size_val = 1 67 train_num = 0 68 val_num = 0 69 70 tra_img_name_list = glob.glob(data_dir + tra_image_dir + '*' + label_ext) 71 72 tra_lbl_name_list = [] 73 for img_path in tra_img_name_list: 74 img_name = img_path.split(os.sep)[-1] 75 76 aaa = img_name.split(".") 77 bbb = aaa[0:-1] 78 imidx = bbb[0] 79 for i in range(1, len(bbb)): 80 imidx = imidx + "." + bbb[i] 81 82 tra_lbl_name_list.append(data_dir + tra_label_dir + imidx + label_ext) 83 84 print("---") 85 print("train images: ", len(tra_img_name_list)) 86 print("train labels: ", len(tra_lbl_name_list)) 87 print("---") 88 89 train_num = len(tra_img_name_list) 90 91 # 数据预处理 92 salobj_dataset = SalObjDataset( 93 img_name_list=tra_img_name_list, 94 lbl_name_list=tra_lbl_name_list, 95 transform=transforms.Compose([ 96 RescaleT(320), # 将原图缩放至 320*320 97 RandomCrop(288), # 从320*320中截取为288*288 98 ToTensorLab(flag=0)])) 99 # dataloader 100 salobj_dataloader = DataLoader(salobj_dataset, batch_size=batch_size_train, shuffle=True, num_workers=1) 101 102 # ------- 3. define model -------- 103 # define the net 104 if (model_name == 'u2net'): 105 net = U2NET(3, 1) 106 elif (model_name == 'u2netp'): 107 net = U2NETP(3, 1) 108 109 if torch.cuda.is_available(): 110 net.cuda() 111 112 # ------- 4. define optimizer -------- 113 print("---define optimizer...") 114 # 学习率搞小点,Momentum 中beta1 = 0.9,RMSprop 中 beta2 = 0.999, 分母常数项设置为1e-8, 衰减率 = 0 115 optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0) 116 117 # ------- 5. training process -------- 118 print("---start training...") 119 ite_num = 0 120 running_loss = 0.0 121 running_tar_loss = 0.0 122 ite_num4val = 0 123 save_frq = 2000 # save the model every 2000 iterations 124 125 if __name__ == '__main__': # error:The "freeze_support()" line can be omitted if the progra 126 for epoch in range(0, epoch_num): 127 net.train() 128 129 for i, data in enumerate(salobj_dataloader): 130 ite_num = ite_num + 1 131 ite_num4val = ite_num4val + 1 132 133 inputs, labels = data['image'], data['label'] 134 135 inputs = inputs.type(torch.FloatTensor) 136 labels = labels.type(torch.FloatTensor) 137 138 # wrap them in Variable 139 if torch.cuda.is_available(): 140 inputs_v, labels_v = Variable(inputs.cuda(), requires_grad=False), Variable(labels.cuda(), requires_grad=False) 141 else: 142 inputs_v, labels_v = Variable(inputs, requires_grad=False), Variable(labels, requires_grad=False) 143 144 # y zero the parameter gradients 145 optimizer.zero_grad() 146 147 # forward + backward + optimize 148 d0, d1, d2, d3, d4, d5, d6 = net(inputs_v) 149 # 可以看到,7张mask都是直接和label图计算交叉熵 150 # loss2:最终mask图的loss 151 # loss:其余6个输出mask的loss之和 152 loss2, loss = muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v) 153 154 loss.backward() 155 optimizer.step() 156 157 # # print statistics 158 running_loss += loss.data.item() 159 running_tar_loss += loss2.data.item() 160 161 # del temporary outputs and loss 162 del d0, d1, d2, d3, d4, d5, d6, loss2, loss 163 164 print("[epoch: %3d/%3d, batch: %5d/%5d, ite: %d] train loss: %3f, tar: %3f " % ( 165 epoch + 1, epoch_num, (i + 1) * batch_size_train, train_num, ite_num, running_loss / ite_num4val, 166 running_tar_loss / ite_num4val)) 167 168 if ite_num % save_frq == 0: 169 torch.save(net.state_dict(), model_dir + model_name + "_bce_itr_%d_train_%3f_tar_%3f.pth" % ( 170 ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val)) 171 running_loss = 0.0 172 running_tar_loss = 0.0 173 net.train() # resume train 174 ite_num4val = 0
3.3、测试代码解读
u2net_test.py
1 import os 2 from skimage import io, transform 3 import torch 4 import torchvision 5 from torch.autograd import Variable 6 import torch.nn as nn 7 import torch.nn.functional as F 8 from torch.utils.data import Dataset, DataLoader 9 from torchvision import transforms # , utils 10 # import torch.optim as optim 11 12 import numpy as np 13 from PIL import Image 14 import glob 15 16 from data_loader import RescaleT 17 from data_loader import ToTensor 18 from data_loader import ToTensorLab 19 from data_loader import SalObjDataset 20 21 from model import U2NET # full size version 173.6 MB 22 from model import U2NETP # small version u2net 4.7 MB 23 24 25 # normalize the predicted SOD probability map 26 def normPRED(d): 27 ma = torch.max(d) 28 mi = torch.min(d) 29 30 dn = (d - mi) / (ma - mi) 31 32 return dn 33 34 35 def save_output(image_name, pred, d_dir): 36 predict = pred 37 predict = predict.squeeze() 38 predict_np = predict.cpu().data.numpy() 39 40 im = Image.fromarray(predict_np * 255).convert('RGB') 41 img_name = image_name.split(os.sep)[-1] 42 image = io.imread(image_name) 43 imo = im.resize((image.shape[1], image.shape[0]), resample=Image.BILINEAR) 44 45 pb_np = np.array(imo) 46 47 aaa = img_name.split(".") 48 bbb = aaa[0:-1] 49 imidx = bbb[0] 50 for i in range(1, len(bbb)): 51 imidx = imidx + "." + bbb[i] 52 53 imo.save(d_dir + imidx + '.png') 54 55 56 def main(): 57 # --------- 1. get image path and name --------- 58 model_name = 'u2net' # u2netp 59 60 image_dir = os.path.join(os.getcwd(), 'test_data', 'test_images') 61 prediction_dir = os.path.join(os.getcwd(), 'test_data', model_name + '_results' + os.sep) 62 model_dir = os.path.join(os.getcwd(), 'saved_models', model_name, model_name + '.pth') 63 64 img_name_list = glob.glob(image_dir + os.sep + '*') 65 print(img_name_list) 66 67 # --------- 2. dataloader --------- 68 # 1. dataloader 69 test_salobj_dataset = SalObjDataset(img_name_list=img_name_list, 70 lbl_name_list=[], 71 transform=transforms.Compose([RescaleT(320), # 缩放到了320 72 ToTensorLab(flag=0)]) 73 ) 74 test_salobj_dataloader = DataLoader(test_salobj_dataset, 75 batch_size=1, 76 shuffle=False, 77 num_workers=1) 78 # --------- 3. model define --------- 79 if (model_name == 'u2net'): 80 print("...load U2NET---173.6 MB") 81 net = U2NET(3, 1) 82 elif (model_name == 'u2netp'): 83 print("...load U2NEP---4.7 MB") 84 net = U2NETP(3, 1) 85 86 if torch.cuda.is_available(): 87 net.load_state_dict(torch.load(model_dir)) 88 net.cuda() 89 else: 90 net.load_state_dict(torch.load(model_dir, map_location='cpu')) 91 net.eval() 92 93 # 统计参数量级(by shiruiyu) 94 num_params = 0 95 for param in net.parameters(): 96 num_params += param.numel() 97 print("numbers of parameters: ", num_params / 1e6, "百万") 98 99 # --------- 4. inference for each image --------- 100 for i_test, data_test in enumerate(test_salobj_dataloader): 101 102 print("inferencing:", img_name_list[i_test].split(os.sep)[-1]) 103 104 inputs_test = data_test['image'] 105 inputs_test = inputs_test.type(torch.FloatTensor) 106 107 if torch.cuda.is_available(): 108 inputs_test = Variable(inputs_test.cuda()) 109 else: 110 inputs_test = Variable(inputs_test) 111 112 d1, d2, d3, d4, d5, d6, d7 = net(inputs_test) 113 114 # normalization 115 pred = d1[:, 0, :, :] # 这里是推理,所以仅处理最终特征图 116 pred = normPRED(pred) 117 118 # save results to test_results folder 119 if not os.path.exists(prediction_dir): 120 os.makedirs(prediction_dir, exist_ok=True) 121 save_output(img_name_list[i_test], pred, prediction_dir) 122 123 del d1, d2, d3, d4, d5, d6, d7 124 125 126 if __name__ == "__main__": 127 main()
3.4、网络模型解读
记得连带参考上图4,u2net.py
先看有哪些函数,如下截图:
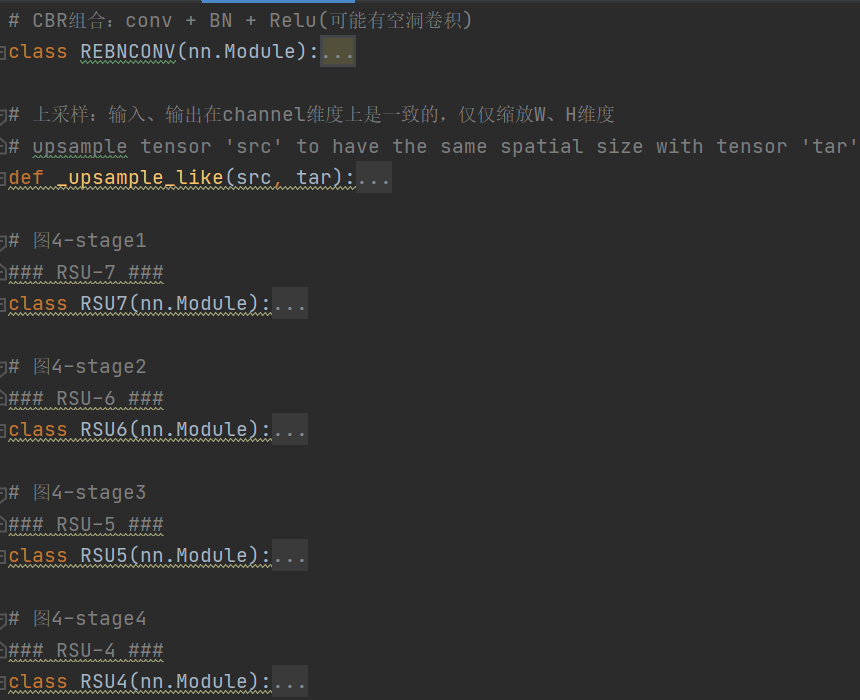
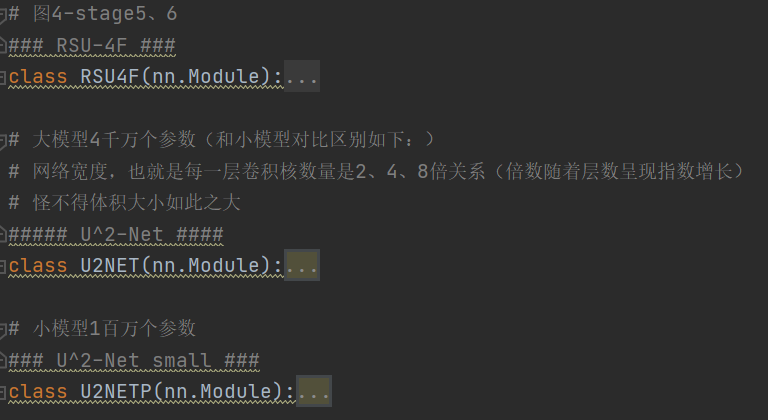
一定要对比图看,已经注释得很详细了
1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 5 # note:最新U2Net代码输入图像直接插值为320*320,后续没有进行截图 6 # 下文中,in_ch, mid_ch, out_ch分别表示初始、中间、末端特征图channels维度 7 # CBR组合:conv + BN + Relu(可能有空洞卷积) 8 class REBNCONV(nn.Module): 9 def __init__(self, in_ch=3, out_ch=3, dirate=1): 10 super(REBNCONV, self).__init__() 11 # dilation 空洞卷积参数 12 self.conv_s1 = nn.Conv2d(in_ch, out_ch, 3, padding=1 * dirate, dilation=1 * dirate) 13 self.bn_s1 = nn.BatchNorm2d(out_ch) 14 self.relu_s1 = nn.ReLU(inplace=True) 15 16 def forward(self, x): 17 hx = x 18 xout = self.relu_s1(self.bn_s1(self.conv_s1(hx))) 19 20 return xout 21 22 23 # 上采样:输入、输出在channel维度上是一致的,仅仅缩放W、H维度 24 # upsample tensor 'src' to have the same spatial size with tensor 'tar' 25 def _upsample_like(src, tar): 26 src = F.upsample(src, size=tar.shape[2:], mode='bilinear') 27 28 return src 29 30 31 # 图4-stage1 32 ### RSU-7 ### 33 class RSU7(nn.Module): # UNet07DRES(nn.Module): 34 35 def __init__(self, in_ch=3, mid_ch=12, out_ch=3): 36 super(RSU7, self).__init__() 37 38 self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) 39 40 self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1) 41 self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 42 43 self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1) 44 self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 45 46 self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1) 47 self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 48 49 self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1) 50 self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 51 52 self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1) 53 self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 54 55 self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=1) 56 57 self.rebnconv7 = REBNCONV(mid_ch, mid_ch, dirate=2) 58 59 self.rebnconv6d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 60 self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 61 self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 62 self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 63 self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 64 self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1) 65 66 def forward(self, x): 67 hx = x 68 hxin = self.rebnconvin(hx) 69 70 hx1 = self.rebnconv1(hxin) 71 hx = self.pool1(hx1) 72 73 hx2 = self.rebnconv2(hx) 74 hx = self.pool2(hx2) 75 76 hx3 = self.rebnconv3(hx) 77 hx = self.pool3(hx3) 78 79 hx4 = self.rebnconv4(hx) 80 hx = self.pool4(hx4) 81 82 hx5 = self.rebnconv5(hx) 83 hx = self.pool5(hx5) 84 85 hx6 = self.rebnconv6(hx) 86 # hx7:图4-stage1中最右边、最小的蓝色块 87 hx7 = self.rebnconv7(hx6) 88 # 下面有多个cat操作 89 # 对应图4-stage1中的符号“+” 90 hx6d = self.rebnconv6d(torch.cat((hx7, hx6), 1)) 91 hx6dup = _upsample_like(hx6d, hx5) 92 93 hx5d = self.rebnconv5d(torch.cat((hx6dup, hx5), 1)) 94 hx5dup = _upsample_like(hx5d, hx4) 95 96 hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1)) 97 hx4dup = _upsample_like(hx4d, hx3) 98 99 hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1)) 100 hx3dup = _upsample_like(hx3d, hx2) 101 102 hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1)) 103 hx2dup = _upsample_like(hx2d, hx1) 104 # hx1d:图4-stage1中最右边紫色块 105 hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1)) 106 107 return hx1d + hxin 108 109 110 # 图4-stage2 111 ### RSU-6 ### 112 class RSU6(nn.Module): # UNet06DRES(nn.Module): 113 114 def __init__(self, in_ch=3, mid_ch=12, out_ch=3): 115 super(RSU6, self).__init__() 116 117 self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) 118 119 self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1) 120 self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 121 122 self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1) 123 self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 124 125 self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1) 126 self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 127 128 self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1) 129 self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 130 131 self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1) 132 133 self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=2) 134 135 self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 136 self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 137 self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 138 self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 139 self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1) 140 141 def forward(self, x): 142 hx = x 143 144 hxin = self.rebnconvin(hx) 145 146 hx1 = self.rebnconv1(hxin) 147 hx = self.pool1(hx1) 148 149 hx2 = self.rebnconv2(hx) 150 hx = self.pool2(hx2) 151 152 hx3 = self.rebnconv3(hx) 153 hx = self.pool3(hx3) 154 155 hx4 = self.rebnconv4(hx) 156 hx = self.pool4(hx4) 157 158 hx5 = self.rebnconv5(hx) 159 160 hx6 = self.rebnconv6(hx5) 161 162 hx5d = self.rebnconv5d(torch.cat((hx6, hx5), 1)) 163 hx5dup = _upsample_like(hx5d, hx4) 164 165 hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1)) 166 hx4dup = _upsample_like(hx4d, hx3) 167 168 hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1)) 169 hx3dup = _upsample_like(hx3d, hx2) 170 171 hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1)) 172 hx2dup = _upsample_like(hx2d, hx1) 173 174 hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1)) 175 176 return hx1d + hxin 177 178 179 # 图4-stage3 180 ### RSU-5 ### 181 class RSU5(nn.Module): # UNet05DRES(nn.Module): 182 183 def __init__(self, in_ch=3, mid_ch=12, out_ch=3): 184 super(RSU5, self).__init__() 185 186 self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) 187 188 self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1) 189 self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 190 191 self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1) 192 self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 193 194 self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1) 195 self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 196 197 self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1) 198 199 self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=2) 200 201 self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 202 self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 203 self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 204 self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1) 205 206 def forward(self, x): 207 hx = x 208 209 hxin = self.rebnconvin(hx) 210 211 hx1 = self.rebnconv1(hxin) 212 hx = self.pool1(hx1) 213 214 hx2 = self.rebnconv2(hx) 215 hx = self.pool2(hx2) 216 217 hx3 = self.rebnconv3(hx) 218 hx = self.pool3(hx3) 219 220 hx4 = self.rebnconv4(hx) 221 222 hx5 = self.rebnconv5(hx4) 223 224 hx4d = self.rebnconv4d(torch.cat((hx5, hx4), 1)) 225 hx4dup = _upsample_like(hx4d, hx3) 226 227 hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1)) 228 hx3dup = _upsample_like(hx3d, hx2) 229 230 hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1)) 231 hx2dup = _upsample_like(hx2d, hx1) 232 233 hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1)) 234 235 return hx1d + hxin 236 237 238 # 图4-stage4 239 ### RSU-4 ### 240 class RSU4(nn.Module): # UNet04DRES(nn.Module): 241 242 def __init__(self, in_ch=3, mid_ch=12, out_ch=3): 243 super(RSU4, self).__init__() 244 245 self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) 246 247 self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1) 248 self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 249 250 self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1) 251 self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 252 253 self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1) 254 255 self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=2) 256 257 self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 258 self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1) 259 self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1) 260 261 def forward(self, x): 262 hx = x 263 264 hxin = self.rebnconvin(hx) 265 266 hx1 = self.rebnconv1(hxin) 267 hx = self.pool1(hx1) 268 269 hx2 = self.rebnconv2(hx) 270 hx = self.pool2(hx2) 271 272 hx3 = self.rebnconv3(hx) 273 274 hx4 = self.rebnconv4(hx3) 275 276 hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1)) 277 hx3dup = _upsample_like(hx3d, hx2) 278 279 hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1)) 280 hx2dup = _upsample_like(hx2d, hx1) 281 282 hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1)) 283 284 return hx1d + hxin 285 286 287 # 图4-stage5、6 288 ### RSU-4F ### 289 class RSU4F(nn.Module): # UNet04FRES(nn.Module): 290 291 def __init__(self, in_ch=3, mid_ch=12, out_ch=3): 292 super(RSU4F, self).__init__() 293 294 self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1) 295 296 self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1) 297 self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=2) 298 self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=4) 299 300 self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=8) 301 302 self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=4) 303 self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=2) 304 self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1) 305 306 def forward(self, x): 307 hx = x 308 309 hxin = self.rebnconvin(hx) 310 311 hx1 = self.rebnconv1(hxin) 312 hx2 = self.rebnconv2(hx1) 313 hx3 = self.rebnconv3(hx2) 314 315 hx4 = self.rebnconv4(hx3) 316 317 hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1)) 318 hx2d = self.rebnconv2d(torch.cat((hx3d, hx2), 1)) 319 hx1d = self.rebnconv1d(torch.cat((hx2d, hx1), 1)) 320 321 return hx1d + hxin 322 323 324 # 大模型4千万个参数(和小模型对比区别如下:) 325 # 网络宽度,也就是每一层卷积核数量是2、4、8倍关系(倍数随着层数呈现指数增长) 326 # 怪不得体积大小如此之大 327 ##### U^2-Net #### 328 class U2NET(nn.Module): 329 def __init__(self, in_ch=3, out_ch=1): 330 super(U2NET, self).__init__() 331 332 self.stage1 = RSU7(in_ch, 32, 64) 333 self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 334 335 self.stage2 = RSU6(64, 32, 128) 336 self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 337 338 self.stage3 = RSU5(128, 64, 256) 339 self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 340 341 self.stage4 = RSU4(256, 128, 512) 342 self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 343 344 self.stage5 = RSU4F(512, 256, 512) 345 self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 346 347 self.stage6 = RSU4F(512, 256, 512) 348 349 # decoder 350 self.stage5d = RSU4F(1024, 256, 512) 351 self.stage4d = RSU4(1024, 128, 256) 352 self.stage3d = RSU5(512, 64, 128) 353 self.stage2d = RSU6(256, 32, 64) 354 self.stage1d = RSU7(128, 16, 64) 355 356 self.side1 = nn.Conv2d(64, out_ch, 3, padding=1) 357 self.side2 = nn.Conv2d(64, out_ch, 3, padding=1) 358 self.side3 = nn.Conv2d(128, out_ch, 3, padding=1) 359 self.side4 = nn.Conv2d(256, out_ch, 3, padding=1) 360 self.side5 = nn.Conv2d(512, out_ch, 3, padding=1) 361 self.side6 = nn.Conv2d(512, out_ch, 3, padding=1) 362 363 self.outconv = nn.Conv2d(6 * out_ch, out_ch, 1) 364 365 def forward(self, x): 366 hx = x # torch.Size([1, 3, 320, 320]) note:原图上输入是:1*3*288*288, 和下面是一样的懒得改了 367 # print('hx.shape = ', hx.shape) 368 369 # stage 1(En_1) 370 hx1 = self.stage1(hx) # torch.Size([1, 64, 320, 320]) 371 hx = self.pool12(hx1) # torch.Size([1, 64, 160, 160]) 372 373 # stage 2(En_2) 374 hx2 = self.stage2(hx) # torch.Size([1, 128, 160, 160]) 375 hx = self.pool23(hx2) # torch.Size([1, 128, 80, 80]) 376 377 # stage 3(En_3) 378 hx3 = self.stage3(hx) # torch.Size([1, 256, 80, 80]) 379 hx = self.pool34(hx3) # torch.Size([1, 256, 40, 40]) 380 381 # stage 4(En_4) 382 hx4 = self.stage4(hx) # torch.Size([1, 512, 40, 40]) 383 hx = self.pool45(hx4) # torch.Size([1, 512, 20, 20]) 384 385 # stage 5(En_5) 386 hx5 = self.stage5(hx) # torch.Size([1, 512, 20, 20]) 387 hx = self.pool56(hx5) # torch.Size([1, 512, 10, 10]) 388 389 # stage 6(En_6) 390 hx6 = self.stage6(hx) # torch.Size([1, 512, 10, 10]) 391 hx6up = _upsample_like(hx6, hx5) # torch.Size([1, 512, 20, 20]) 392 393 # -------------------- decoder -------------------- 394 # De_5 395 hx5d = self.stage5d(torch.cat((hx6up, hx5), 1)) # torch.Size([1, 512, 20, 20]) 396 hx5dup = _upsample_like(hx5d, hx4) # torch.Size([1, 512, 40, 40]) 397 # De_4 398 hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1)) # torch.Size([1, 256, 40, 40]) 399 hx4dup = _upsample_like(hx4d, hx3) # torch.Size([1, 256, 80, 80]) 400 # De_3 401 hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1)) # torch.Size([1, 128, 80, 80]) 402 hx3dup = _upsample_like(hx3d, hx2) # torch.Size([1, 128, 160, 160]) 403 # De_2 404 hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1)) # torch.Size([1, 64, 160, 160]) 405 hx2dup = _upsample_like(hx2d, hx1) # torch.Size([1, 64, 320, 320]) 406 # De_1 407 hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1)) # torch.Size([1, 64, 320, 320]) 408 409 # side output 410 # 0倍上采样 411 d1 = self.side1(hx1d) # torch.Size([1, 1, 320, 320]) 412 # 2倍上采样 413 d2 = self.side2(hx2d) # torch.Size([1, 1, 160, 160]) 414 d2 = _upsample_like(d2, d1) # torch.Size([1, 1, 320, 320]) 415 # 5倍上采样 416 d3 = self.side3(hx3d) # torch.Size([1, 1, 80, 80]) 417 d3 = _upsample_like(d3, d1) # torch.Size([1, 1, 320, 320]) 418 # 8倍上采样 419 d4 = self.side4(hx4d) # torch.Size([1, 1, 40, 40]) 420 d4 = _upsample_like(d4, d1) # torch.Size([1, 1, 320, 320]) 421 # 16倍上采样 422 d5 = self.side5(hx5d) # torch.Size([1, 1, 20, 20]) 423 d5 = _upsample_like(d5, d1) # torch.Size([1, 1, 320, 320]) 424 # 32倍上采样 425 d6 = self.side6(hx6) # torch.Size([1, 1, 10, 10]) 426 d6 = _upsample_like(d6, d1) # torch.Size([1, 1, 320, 320]) 427 # concat + 1×1卷积 428 d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1)) # torch.Size([1, 1, 320, 320]) 429 # torch.sigmoid() 430 return F.sigmoid(d0), F.sigmoid(d1), F.sigmoid(d2), F.sigmoid(d3), F.sigmoid(d4), F.sigmoid(d5), F.sigmoid(d6) 431 432 433 # 小模型1百万个参数 434 ### U^2-Net small ### 435 class U2NETP(nn.Module): 436 437 def __init__(self, in_ch=3, out_ch=1): 438 super(U2NETP, self).__init__() 439 440 self.stage1 = RSU7(in_ch, 16, 64) 441 self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 442 443 self.stage2 = RSU6(64, 16, 64) 444 self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 445 446 self.stage3 = RSU5(64, 16, 64) 447 self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 448 449 self.stage4 = RSU4(64, 16, 64) 450 self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 451 452 self.stage5 = RSU4F(64, 16, 64) 453 self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True) 454 455 self.stage6 = RSU4F(64, 16, 64) 456 457 # decoder 458 self.stage5d = RSU4F(128, 16, 64) 459 self.stage4d = RSU4(128, 16, 64) 460 self.stage3d = RSU5(128, 16, 64) 461 self.stage2d = RSU6(128, 16, 64) 462 self.stage1d = RSU7(128, 16, 64) 463 464 self.side1 = nn.Conv2d(64, out_ch, 3, padding=1) 465 self.side2 = nn.Conv2d(64, out_ch, 3, padding=1) 466 self.side3 = nn.Conv2d(64, out_ch, 3, padding=1) 467 self.side4 = nn.Conv2d(64, out_ch, 3, padding=1) 468 self.side5 = nn.Conv2d(64, out_ch, 3, padding=1) 469 self.side6 = nn.Conv2d(64, out_ch, 3, padding=1) 470 471 self.outconv = nn.Conv2d(6 * out_ch, out_ch, 1) 472 473 def forward(self, x): 474 hx = x 475 476 # stage 1 477 hx1 = self.stage1(hx) 478 hx = self.pool12(hx1) 479 480 # stage 2 481 hx2 = self.stage2(hx) 482 hx = self.pool23(hx2) 483 484 # stage 3 485 hx3 = self.stage3(hx) 486 hx = self.pool34(hx3) 487 488 # stage 4 489 hx4 = self.stage4(hx) 490 hx = self.pool45(hx4) 491 492 # stage 5 493 hx5 = self.stage5(hx) 494 hx = self.pool56(hx5) 495 496 # stage 6 497 hx6 = self.stage6(hx) 498 hx6up = _upsample_like(hx6, hx5) 499 500 # decoder 501 hx5d = self.stage5d(torch.cat((hx6up, hx5), 1)) 502 hx5dup = _upsample_like(hx5d, hx4) 503 504 hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1)) 505 hx4dup = _upsample_like(hx4d, hx3) 506 507 hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1)) 508 hx3dup = _upsample_like(hx3d, hx2) 509 510 hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1)) 511 hx2dup = _upsample_like(hx2d, hx1) 512 513 hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1)) 514 515 # side output 516 d1 = self.side1(hx1d) 517 518 d2 = self.side2(hx2d) 519 d2 = _upsample_like(d2, d1) 520 521 d3 = self.side3(hx3d) 522 d3 = _upsample_like(d3, d1) 523 524 d4 = self.side4(hx4d) 525 d4 = _upsample_like(d4, d1) 526 527 d5 = self.side5(hx5d) 528 d5 = _upsample_like(d5, d1) 529 530 d6 = self.side6(hx6) 531 d6 = _upsample_like(d6, d1) 532 533 d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1)) 534 535 return F.sigmoid(d0), F.sigmoid(d1), F.sigmoid(d2), F.sigmoid(d3), F.sigmoid(d4), F.sigmoid(d5), F.sigmoid(d6)
四、Libtorch部署
模型导出python脚本:
export_u2net.py
(这里只给出导出CPU版本,实际上,在libtorch中无论是CPU还是GPU都是可以用这个导出的CPU模型,因为模型、数据是可以导入GPU中)
1 import os 2 import torch 3 from model import U2NET # full size version 173.6 MB 4 5 6 def main(): 7 model_name = 'u2net' 8 model_dir = os.path.join(os.getcwd(), 'saved_models', model_name + '_human_seg', model_name + '_human_seg.pth') 9 10 if model_name == 'u2net': 11 print("...load U2NET---173.6 MB") 12 net = U2NET(3, 1) 13 14 net.load_state_dict(torch.load(model_dir, map_location=torch.device('cpu'))) 15 net.eval() 16 17 # --------- model 序列化 --------- 18 #example = torch.zeros(1, 3, 512, 512).to(device='cuda') 19 example = torch.zeros(1, 3, 512, 512) 20 torch_script_module = torch.jit.trace(net, example) 21 torch_script_module.save('human2-cpu.pt') 22 print('over') 23 24 25 if __name__ == "__main__": 26 main()
部署代码:
配置文件Config.yaml
1 %YAML:1.0 2 # note: 1、修改文件名时,记得保留符号 "",变量不需要该符号 3 # 2、图分辨率 > 4 # 3、本文件注释须单独一行 5 # 4、项目中所有读取、保存的本地数据都默认在dir: "D://Data//"下 6 7 # data目录 8 dir: "D:\Data\" 9 10 # 原图 11 srcImgFile: "img_1589.png" 12 13 14 # ****************************************************************** 深度学习 *********************************************************************** 15 # 风格转换模型文件名 16 styleModelFile: "D:\U-2-Net-master\human1-gpu.pt"
配置文件代码:Config.h、Config.cpp
1 #ifndef CONFIG_H 2 #define CONFIG_H 3 4 #include<opencv2/opencv.hpp> 5 #include<iostream> 6 7 class Config 8 { 9 public: 10 Config(const std::string& yamlFile); 11 ~Config(); 12 13 template<typename T> 14 T get(const std::string& key) 15 { 16 return T(this->m_fileStorage[key]); 17 } 18 19 private: 20 std::string m_yamlFile; 21 cv::FileStorage m_fileStorage; 22 }; 23 24 #endif // !Config_H
1 #include "Config.h" 2 3 Config::Config(const std::string& yamlFile): 4 m_yamlFile(yamlFile) 5 { 6 this->m_fileStorage.open(this->m_yamlFile, cv::FileStorage::READ); 7 if (!this->m_fileStorage.isOpened()) 8 { 9 std::cerr << "open default.yaml failurely!" << std::endl; 10 system("pause"); 11 } 12 } 13 14 Config::~Config() 15 { 16 }
人像语义分割:U2Net_Human.cpp,这里又报错(),请参考:《 libtorch在windows下场见错误整理总结》https://i.cnblogs.com/posts/edit-done;postId=14687275
1 #include<opencv2/opencv.hpp> 2 #include<torch/torch.h> 3 #include<torch/script.h> 4 #include"Config.h" 5 6 torch::Tensor normPRED(torch::Tensor d) 7 { 8 at::Tensor ma, mi; 9 torch::Tensor dn; 10 ma = torch::max(d); 11 mi = torch::min(d); 12 dn = (d - mi) / (ma - mi); 13 return dn; 14 } 15 16 void bgr_u2net(cv::Mat& image_src, cv::Mat& result, torch::jit::Module& model) 17 { 18 auto device = torch::Device("cuda"); 19 // auto image_bgr = cv::imread("bg11.png"); 20 // auto xt = cv::imread("xt2.jpg"); 21 cv::Mat image_src1 = image_src.clone(); 22 cv::resize(image_src, image_src, cv::Size(320, 320)); 23 cv::cvtColor(image_src, image_src, cv::COLOR_RGB2BGR); 24 // cv::cvtColor(image_src,image_src,cv::COLOR_BGR2RGB); 25 26 torch::Tensor tensor_image_src = torch::from_blob(image_src.data, { image_src.rows, image_src.cols,3 }, torch::kByte); 27 // torch::Tensor tensor_image_bgr = torch::from_blob(image_bgr.data, {image_bgr.rows, image_bgr.cols,3},torch::kByte); 28 torch::Tensor tensor_bgr = torch::from_blob(image_src1.data, { image_src1.rows, image_src1.cols,3 }, torch::kByte); 29 tensor_image_src = tensor_image_src.permute({ 2,0,1 }); 30 tensor_image_src = tensor_image_src.toType(torch::kFloat); 31 tensor_image_src = tensor_image_src.div(255); 32 tensor_image_src = tensor_image_src.unsqueeze(0); 33 // tensor_image_bgr = tensor_image_bgr.permute({2,0,1}); 34 // tensor_image_bgr = tensor_image_bgr.toType(torch::kFloat); 35 // tensor_image_bgr = tensor_image_bgr.div(255); 36 // tensor_image_bgr = tensor_image_bgr.unsqueeze(0); 37 tensor_bgr = tensor_bgr.permute({ 2,0,1 }); 38 tensor_bgr = tensor_bgr.toType(torch::kFloat); 39 tensor_bgr = tensor_bgr.div(255); 40 tensor_bgr = tensor_bgr.unsqueeze(0); 41 // cv::imshow("image",tensor_image_bgr) 42 43 auto src = tensor_image_src.to(device); 44 // auto bgr = tensor_image_bgr.to(device); 45 auto src_copy = tensor_bgr.to(device); 46 47 auto outputs = model.forward({ src }).toTuple()->elements(); 48 49 auto pred = outputs[0].toTensor(); 50 51 52 // pha = normPRED_(pha); 53 // auto fgr = outputs[1].toTensor(); 54 // auto res_tensor = (pred * src + (1-pred)* torch::ones_like(src)); 55 // double endtime=(double)(end-start)/CLOCKS_PER_SEC; 56 // std::cout<<"time:"<<endtime<<std::endl; 57 // auto res_tensor = (pred * src + (1-pred)*torch::tensor({120/255, 255/255, 155/255}).to(device).view({1,3,1,1})); 58 auto res_tensor = (pred * torch::ones_like(src)); 59 res_tensor = normPRED(res_tensor); 60 res_tensor = res_tensor.squeeze(0).detach(); 61 res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); 62 res_tensor = res_tensor.to(torch::kCPU); 63 // cv::Mat result( image_bgr.rows,image_bgr.cols, CV_32FC3,fgr.data_ptr()); 64 cv::Mat resultImg(res_tensor.size(1), res_tensor.size(2), CV_8UC3); 65 std::memcpy((void*)resultImg.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); 66 // result=resultImg.clone(); 67 // cv::cvtColor(result,result,cv::COLOR_BGR2RGB); 68 69 cv::resize(resultImg, resultImg, cv::Size(image_src1.cols, image_src1.rows), cv::INTER_LINEAR); 70 // cv:: Mat element = getStructuringElement(cv::MORPH_RECT, cv::Size(15,15)); 71 // cv::dilate(resultImg, resultImg, element); 72 // cv::threshold(resultImg, resultImg, 130, 255, cv::THRESH_BINARY); 73 // cv::imwrite("pha.jpg", resultImg); 74 torch::Tensor tensor_result = torch::from_blob(resultImg.data, { resultImg.rows, resultImg.cols,3 }, torch::kByte); 75 tensor_result = tensor_result.permute({ 2,0,1 }); 76 tensor_result = tensor_result.toType(torch::kFloat); 77 tensor_result = tensor_result.div(255); 78 tensor_result = tensor_result.unsqueeze(0); 79 // torch::Tensor c=(tensor_result>220/255); 80 81 // tensor_result>200/255; 82 ; 83 // tensor_result[tensor_result>=200/255]=1; 84 // res_tensor = (c * tensor_bgr -c* torch::ones_like(tensor_bgr)+torch::ones_like(tensor_bgr) ); 85 res_tensor = (tensor_result * tensor_bgr + (1 - tensor_result) * torch::ones_like(tensor_bgr)); 86 // res_tensor = (tensor_result * tensor_bgr +(1-tensor_result)* tensor_image_bgr ); 87 res_tensor = res_tensor.squeeze(0).detach(); 88 res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); 89 res_tensor = res_tensor.to(torch::kCPU); 90 // cv::Mat result( image_bgr.rows,image_bgr.cols, CV_32FC3,fgr.data_ptr()); 91 cv::Mat resultImg1(res_tensor.size(1), res_tensor.size(2), CV_8UC3); 92 std::memcpy((void*)resultImg1.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); 93 result = resultImg1.clone(); 94 95 96 } 97 98 int main() 99 { 100 // load srcImg 101 Config cfg("Config.yaml"); 102 cv::Mat srcImg = cv::imread(cfg.get<std::string>("srcImgFile"), -1); 103 cv::Mat srcImg_; 104 cv::resize(srcImg, srcImg_, cv::Size(512, 512)); 105 106 std::string str = cfg.get<std::string>("styleModelFile"); 107 108 // load model of cpu 109 torch::jit::script::Module styleModule; 110 // load style model 111 auto device_type = at::kCPU; 112 if (torch::cuda::is_available()) { 113 std::cout << "gpu" << std::endl; 114 device_type = at::kCUDA; 115 } 116 try 117 { 118 styleModule = torch::jit::load(str); 119 styleModule.to(device_type); 120 } 121 catch (const c10::Error& e) 122 { 123 std::cerr << "errir code: -2, error loading the model "; 124 return -1; 125 } 126 cv::Mat dstImg; 127 bgr_u2net(srcImg_, dstImg, styleModule); 128 129 cv::imshow("dstImg", dstImg); 130 cv::waitKey(0); 131 132 return 1; 133 }
更新下U2Net_Human.cpp,似乎对libtorch还不够纯熟。
1 #include<opencv2/opencv.hpp> 2 #include<torch/torch.h> 3 #include<torch/script.h> 4 #include"Config.h" 5 6 torch::Tensor normPRED(torch::Tensor d) 7 { 8 at::Tensor ma, mi; 9 torch::Tensor dn; 10 ma = torch::max(d); 11 mi = torch::min(d); 12 dn = (d - mi) / (ma - mi); 13 return dn; 14 } 15 16 void bgr_u2net(cv::Mat& image_src, cv::Mat& result, torch::jit::Module& model) 17 { 18 auto device = torch::Device("cuda"); 19 20 cv::Mat image_src1 = image_src.clone(); 21 cv::resize(image_src, image_src, cv::Size(320, 320)); 22 //cv::cvtColor(image_src, image_src, cv::COLOR_RGB2BGR); 23 cv::cvtColor(image_src,image_src,cv::COLOR_BGR2RGB); 24 25 torch::Tensor tensor_image_src = torch::from_blob(image_src.data, { image_src.rows, image_src.cols, 3 }, torch::kByte); 26 // torch::Tensor tensor_image_bgr = torch::from_blob(image_bgr.data, {image_bgr.rows, image_bgr.cols,3},torch::kByte); 27 torch::Tensor tensor_bgr = torch::from_blob(image_src1.data, { image_src1.rows, image_src1.cols,3 }, torch::kByte); 28 tensor_image_src = tensor_image_src.permute({ 2,0,1 }); // RGB -> BGR互换,有点多余 29 tensor_image_src = tensor_image_src.toType(torch::kFloat); 30 tensor_image_src = tensor_image_src.div(255); 31 // [3, 320, 320] 32 tensor_image_src = tensor_image_src.unsqueeze(0); // 拿掉第一个维度 33 // [1, 3, 320, 320] 34 std::cout << tensor_image_src.sizes() << std::endl; 35 36 tensor_bgr = tensor_bgr.permute({ 2,0,1 }); 37 tensor_bgr = tensor_bgr.toType(torch::kFloat); 38 tensor_bgr = tensor_bgr.div(255); 39 tensor_bgr = tensor_bgr.unsqueeze(0); 40 41 auto src = tensor_image_src.to(device); 42 // auto bgr = tensor_image_bgr.to(device); 43 //auto src_copy = tensor_bgr.to(device); 44 45 auto outputs = model.forward({ src }).toTuple()->elements(); 46 47 auto pred = outputs[0].toTensor(); 48 49 auto res_tensor = (pred * torch::ones_like(src)); 50 51 std::cout << torch::ones_like(src).sizes() << std::endl; 52 std::cout << src.sizes() << std::endl; 53 54 res_tensor = normPRED(res_tensor); 55 res_tensor = res_tensor.squeeze(0).detach(); 56 res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); 57 res_tensor = res_tensor.to(torch::kCPU); 58 // cv::Mat result( image_bgr.rows,image_bgr.cols, CV_32FC3,fgr.data_ptr()); 59 cv::Mat resultImg(res_tensor.size(1), res_tensor.size(2), CV_8UC3); 60 std::memcpy((void*)resultImg.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); 61 // result=resultImg.clone(); 62 // cv::cvtColor(result,result,cv::COLOR_BGR2RGB); 63 64 cv::resize(resultImg, resultImg, cv::Size(image_src1.cols, image_src1.rows), cv::INTER_LINEAR); 65 // cv:: Mat element = getStructuringElement(cv::MORPH_RECT, cv::Size(15,15)); 66 // cv::dilate(resultImg, resultImg, element); 67 // cv::threshold(resultImg, resultImg, 130, 255, cv::THRESH_BINARY); 68 // cv::imwrite("pha.jpg", resultImg); 69 torch::Tensor tensor_result = torch::from_blob(resultImg.data, { resultImg.rows, resultImg.cols,3 }, torch::kByte); 70 tensor_result = tensor_result.permute({ 2,0,1 }); 71 tensor_result = tensor_result.toType(torch::kFloat); 72 tensor_result = tensor_result.div(255); 73 tensor_result = tensor_result.unsqueeze(0); 74 // torch::Tensor c=(tensor_result>220/255); 75 76 // tensor_result>200/255; 77 ; 78 // tensor_result[tensor_result>=200/255]=1; 79 // res_tensor = (c * tensor_bgr -c* torch::ones_like(tensor_bgr)+torch::ones_like(tensor_bgr) ); 80 res_tensor = (tensor_result * tensor_bgr + (1 - tensor_result) * torch::ones_like(tensor_bgr)); 81 // res_tensor = (tensor_result * tensor_bgr +(1-tensor_result)* tensor_image_bgr ); 82 res_tensor = res_tensor.squeeze(0).detach(); 83 res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); 84 res_tensor = res_tensor.to(torch::kCPU); 85 // cv::Mat result( image_bgr.rows,image_bgr.cols, CV_32FC3,fgr.data_ptr()); 86 cv::Mat resultImg1(res_tensor.size(1), res_tensor.size(2), CV_8UC3); 87 std::memcpy((void*)resultImg1.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); 88 result = resultImg1.clone(); 89 90 91 } 92 93 int main() 94 { 95 // load srcImg 96 Config cfg("Config.yaml"); 97 cv::Mat srcImg = cv::imread(cfg.get<std::string>("srcImgFile"), -1); 98 cv::Mat srcImg_; 99 cv::resize(srcImg, srcImg_, cv::Size(512, 512)); 100 if (srcImg_.channels() == 4) 101 { 102 cv::cvtColor(srcImg_, srcImg_, cv::COLOR_BGRA2BGR); 103 } 104 105 std::string str = cfg.get<std::string>("styleModelFile"); 106 107 // load model of cpu 108 torch::jit::script::Module styleModule; 109 // load style model 110 auto device_type = at::kCPU; 111 if (torch::cuda::is_available()) { 112 std::cout << "gpu" << std::endl; 113 device_type = at::kCUDA; 114 } 115 try 116 { 117 styleModule = torch::jit::load(str); 118 styleModule.to(device_type); 119 } 120 catch (const c10::Error& e) 121 { 122 std::cerr << "errir code: -2, error loading the model "; 123 return -1; 124 } 125 cv::Mat dstImg; 126 bgr_u2net(srcImg_, dstImg, styleModule); 127 128 cv::imshow("dstImg", dstImg); 129 cv::waitKey(0); 130 131 return 1; 132 }
五、性能分析
六、问题记录
6.1、u2net_train.py报错问题:
1、 OMP:Error
解决:在文件第一行添加如下代码:
import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # OMP:Error
2、爆显存 error: RuntimeError: CUDA out of memory.
batch_size_train = 12 # 将12改为1
3、error:The "freeze_support()" line can be omitted if the progra
if __name__ == '__main__': # error:The "freeze_support()" line can be omitted if the progra for epoch in range(0, epoch_num): #在 这个for循环前面加上一行,如上所示
......
reference:
[1] 肖像绘画:https://www.cvpy.net/studio/cv/func/DeepLearning/sketch/sketch/page/