原文《U 2 -Net: Going Deeper with Nested U-Structure for Salient Object Detection》
目录:
- 一、综述
- 二、EnCode编码器
- 三、DeCode解码器
- 四、特征图融合与目标函数
- 五、补充-空洞卷积
一、综述
U2-Net:基于堆叠U型结构的来加深网络,用于SOD(显著目标检测)。作者设计了一个简单而强大的深层网络架构,U2-Net,用于显著目标检测(SOD)。作者的U2-Net的体系结构是一个两层嵌套的U型结构。作者对所提出的架构U2- Net (176.3 MB, 30 FPS在GTX 1080Ti GPU上)和U2- Net+ (4.7 MB, 40 FPS)两个模型进行了实例化。这两种模型在6个SOD数据集上都具有竞争性能。
显著性检测:前景、背景分割。
有以下两点创新点:
1、提出RSU模块(就是ResBlock模块中常规卷积替换为U-Block,可ResU-Block),能够从上下文提取不同感受野信息
2、网络不需要类似于ResNet、VGG那样复杂得BackBone,仅采用RSU采集特征,所以速度快。(本身输入就只有288*288,然后中间还有很多降采样,最小特征图9*9,你说快不快!)

图1 RES-L的相关模块
从左到右,是一个网络改进过程:
- PLN:常规网络提取特征,三连:卷积+归一化+激活,CBR
- RES:增加残差连接
- DSE:特征图融合
- INC:特征图融合
- RES-L:本文改进,U-Net + ResNet,
如上图1-(e),RES-L大体上还是U型结构,下图4 U2-Net网络结构图中,编码、解码中很多模块出现过,可以和上图1-(e)对比下。
RSU-L结构图原理:
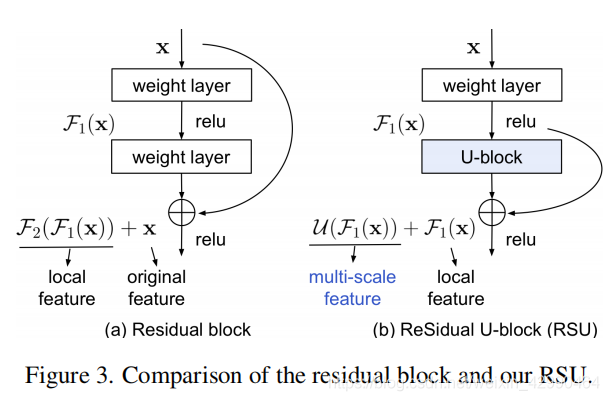
图2 残差模块与RSU模块
更值得注意的是,得益于 U 形结构,RSU 的计算开销相对较少,因为U-Block大多数运算在下采样特征图中应用。下图 展示了 RSU 与其他特征提取模块的计算成本曲线图:
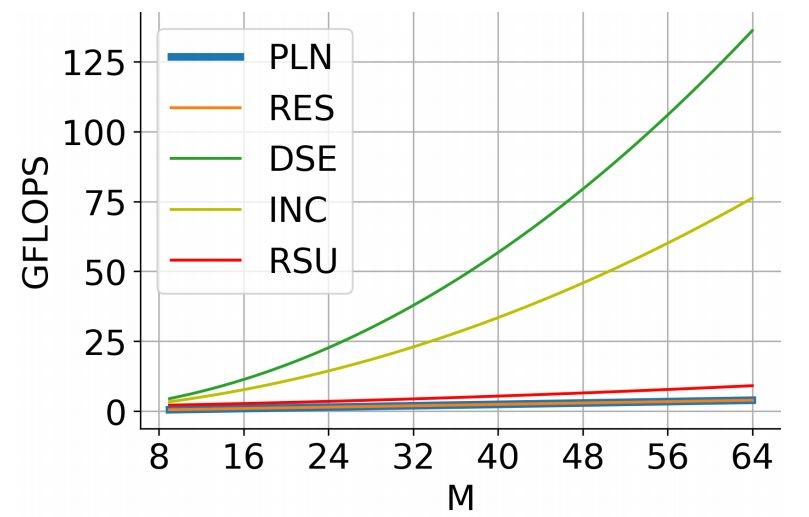
图3 性能对比
如下图,大体还是U型结构,左边6个编码器,右边5个解码器。为什么称为为U方-Net,那是因为,例如在小模块例如En_1中,还有一个U型结构,如下图。论文中:原图是3*320*320,截取之后为3*288*288,注:例如:En/De_1、2、3、4等模块就是本文创新模块RSU。

图4 U2-Net 网络结构图
二、EnCode编码器
如下图是图4中的Stage1:
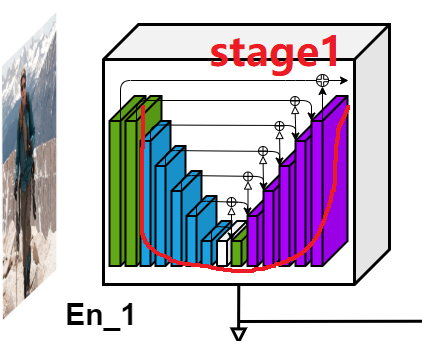
图5 编码块
如上图,U型结构,绿色、蓝色、白色、紫色块功能请参考图4 虚线框模块功能注释。U型结构左边是:绿色到白色是一个卷积等常规操作降采样。查虚线框,咱们看到一个白色块中有一个“dilation = 2 4 8”,这个和空洞卷积有关(在不改变特征图大小的时候,增大感受野,详情见第四小结)。U型结构右边是:从白色到紫色,可以看到有“+”符号,表示concat而已。接着看,绿色到中间第一个紫色块是一个特征图插值上采样,接着就是堆叠特征图stage1中输入大小是3*288*288,输出是64*288*288。
Stage2-6:如图4,为了加速,在stage1和stage2之间有个pooling下采样操作,3和4,4和5…编码器之间都有。如图4,注意到从stage1到stage6,之前前面1-4有蓝色下采样模块,5、6没有,那是因为到了stage5,特征图大小为18*18,已经非常小了,所以不需要下采样,并且空洞卷积“dalition= 4 8”能够提升感受野。
三、DeCode解码器
如下图,当U型结构左边编码部分走完,就到了右边解码结构。如下图Stage6输出512*9*9和stage5输出特征图叠加,得到512*18*18特征图,经过解码器De_5,输出特征图大小还是512*18*18,此时需要和左边stage4特征图进行concat,但是二者大小不一致,原文中是将512*18*18进行上采样,得到512*36*36,之后进行concat的,右边再往上操作是类似的。最终,如图4,网络输出特征图大小为64*288*288。
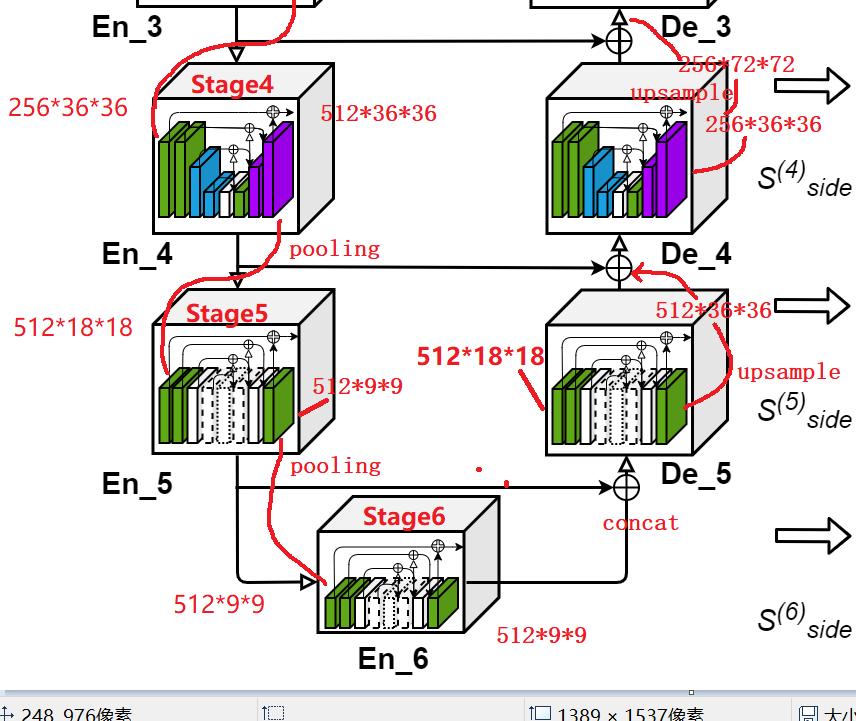
图5 解码快
四、特征图融合与目标函数
如下图6,最终U型结构右边解码器等输出6组特征图(我只截取部分,详细请看图4),经过处理(我猜应该是1×1卷积),输出6个Mask二值图,分辨率为:
- 1×288×288
- 1×144×144
- 1×72×72
- 1×36×36
- 1×18×18
- l 1×9×9
接着,分别进行上采样,采样倍率为1、2、4、8、16、32,得到6个1×288×288特征图,将他们concat一起得到6*288*288特征图,最后采用卷积转为1×288×288卷积。
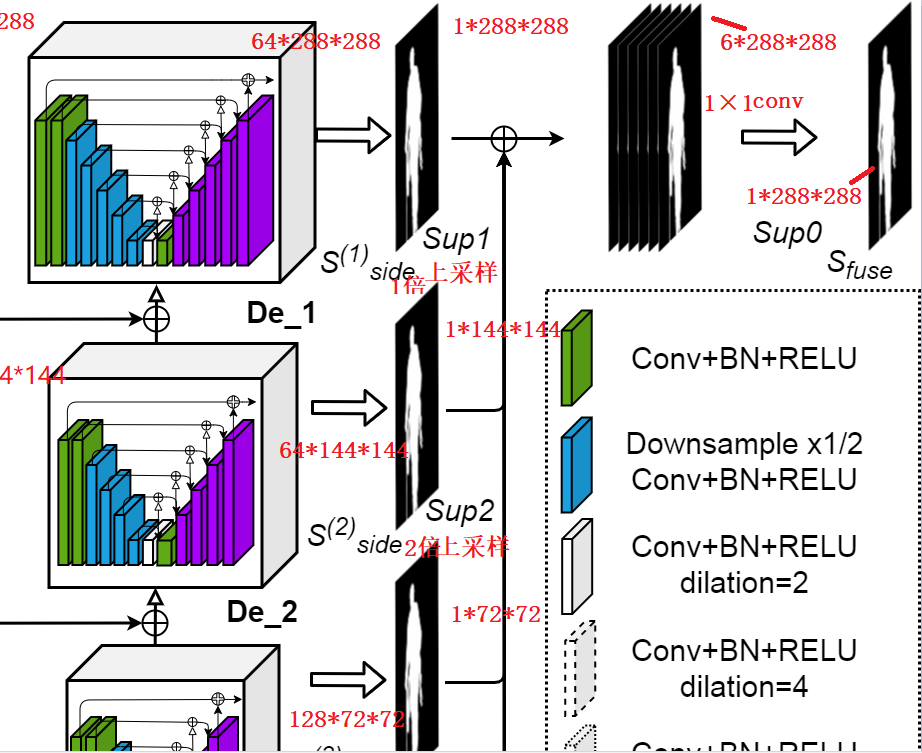
图6 输出mask层
目标函数:在这个过程咱们1×288×288特征图出现了6+1次(其6指的是通过上采样插值得到的1*288*288特征图,1就是最终融合特征图),本文采用多监督算法构建目标函数,意思就是说,网络输出不仅仅包含最终特征图,还包含前面6个不同尺度的特征图(每次迭代,输出7个loss);不仅要监督网络输出,还要监督中间融合特征图。
损失函数如下:
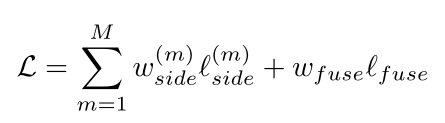
上式中,M = 1、2...6,表示Sup1、Sup2...Sup6,不懂就去看图4,L_side表示那6张图的loss,L_fuse表示最终特征图的loss,两个w表示两项loss的权重参数。loss计算方法采用的是:standard binary cross-entropy,(如下式,我就不管是什么类型交叉熵了):
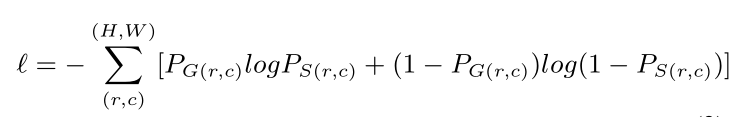
式中,(r,c)表示像素坐标值,(H,W)表示图像高、宽,PG(r,c)表示标签图像素灰度值,PS(r,c)表示预测...。
五、补充-空洞卷积
尽量不损失数据的前提下,增加感受野。
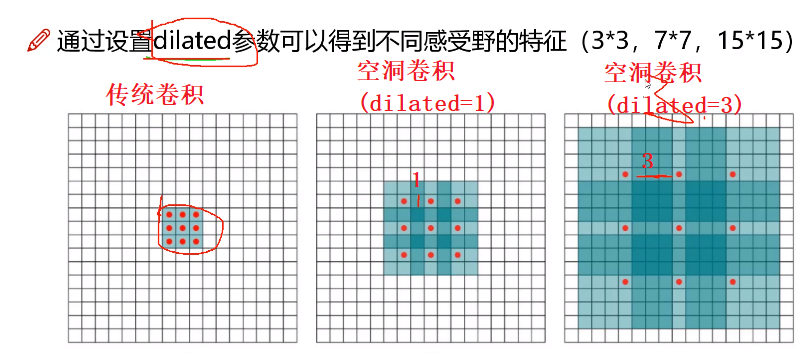
传统卷积:例如采用3*3卷积处理5*5特征图,输出特征大小为3*3,那么输出特征图一个元素对应原图3*3区域,即:感受野为3*3。
空洞卷积:当dilation = 1时,好比将3*3卷积膨胀一下,变为5*5新卷积核,中间用0填充,接着卷积就行了,注意卷积核元素是跳着和原图元素相乘(跳多远取决于dilation取值)!下图空洞卷积核没有画成5*5,还是3*3,也是对的,你看它适合原图对应元素位置!
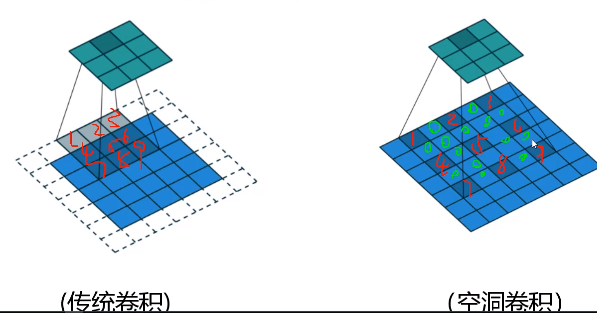
图7 传统卷积与空洞卷积
空洞卷积有个参数,就是dalited(膨胀)取多大,如下图,
- dilated = 1时,感受野由3*3增大到7*7
- dilated = 3时,感受野由3*3增大到15*15
标检测中,对于大目标都需要大感受野,空洞卷积优势:在不增加计算亮的前提下增加了感受野!