Abstract
dropout被广泛地用作全连接层的正则化技术,但是对于卷积层,通常不太有效。dropout在卷积层不work的原因可能是由于卷积层的特征图中相邻位置元素在空间上共享语义信息,所以尽管某个单元被dropout掉,但与其相邻的元素依然可以保有该位置的语义信息,信息仍然可以在卷积网络中流通。因此,针对卷积网络,我们需要一种结构形式的dropout来正则化,即按块来丢弃。在本文中,我们引入DropBlock,这是一种结构化的dropout形式,它将feature map相邻区域中的单元放在一起drop掉。我们发现,除了卷积层外,在跳跃连接中应用DropbBlock可以提高精确度。此外,在训练过程中,逐渐增加dropped unit的数量会导致更好的准确性和对超参数选择的鲁棒性。大量实验表明,DropBlock在卷积网络的正则化中比dropout有更好的性能。
简单来讲,就是避免过拟合,随机杀死一些神经元,类似随机森林剪枝。
Introduction
dropout的主要缺点是它随机drop特征。虽然这对于全连接层是有效的(YOLOV2版本开始,已经没有FC了,而是采用conv代替;原因是:FC参数多,不易收敛,计算量大,而conv参数少),但是对于卷积层则是无效的,因为卷积层的特征在空间上是相关的。当这些特性相互关联时,即使有dropout,有关输入的信息仍然可以发送到下一层,这会导致网络overfit。这种直觉表明,为了更好地规范卷积网络,需要一种更结构化的dropout形式。
在本文中,我们引入DropBlock,这是一种结构形式的dropout,它对卷积网络的正则化特别有效。在DropBlock中,一个block中的features,即feature map中的的一个相邻区域,被放在一起drop掉。如图1所示:
一、DropBlock(丢弃单元邻域的区块)
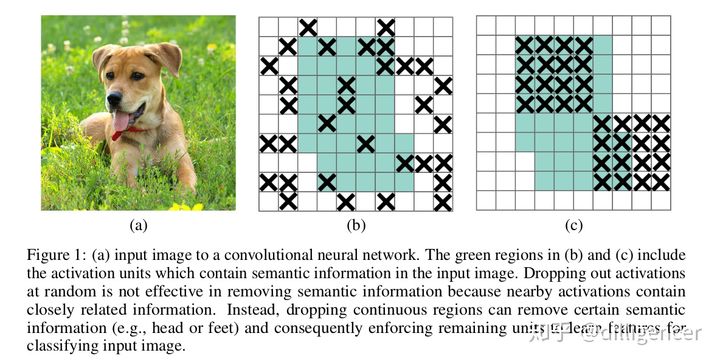
简单翻译一下:
如上图一:(a)是神经网络输入图片。(b)、(c)中的浅绿色区域包含激活层(这些激活层则包含输入图片的语义信息)。在删除语义信息的时候(类似于模型剪枝,以增强泛化精度),dropout采用的是随机删除激活层的像素值,
这种方法不一定有效,这是因为被随机选中的像素,其邻域保留了与其十分接近的信息,这些信息也会导致网络模型overfit。相反,随机删除一些连续的像素块,如图(c),是一种更好的策略(直接把狗头和狗腿删除),这种方法称为dropblock。
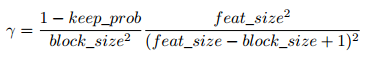
block_size:表示dropout的方块的大小(长,宽),当block_size=1,DropBlock 退化为传统的dropout,正常可以取3,5,7,如下图
γ:表示了随机drop的中间点的概率
feat_size:featureMap大小,如下图
keep_prob:设置阈值概率,所有低于这个值的元素都会去掉。
注:如下图,绿色部分就是要dropout的区域,为了防止dropblock的时候越界,在此给出,如右图一个像素dropblock的边长(也称为:有效种子区域的大小)计算公式:
(feat_size - block_size + 1)
例如:这里feat_size = 10,block_size = 6,dropblock一个像素邻域边长为(10 - 6 + 1)
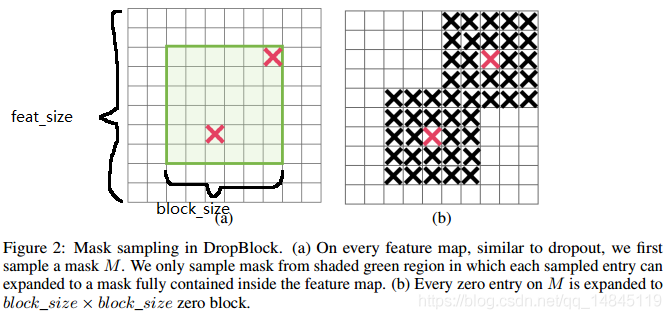
小结:绿色框表示GT box,简单来说就是使用伯努利分布在绿色框内随机生成一个mask,在mask中所有值为0的位置生成一个以其为中心的大小为 block_szie x block_size 的矩形区域,然后将这些区域丢弃。
对于上述公式的解释:
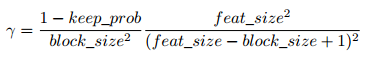
保证DropBlock drop的元素个数和传统dropout drop的元素个数相等;
传统dropout drop的元素个数为:(1-keep_prob)*(feat_size^2);
DropBlock drop的元素个数为:γ*(block_size^2) *(feat_size-block_size+1)^2;
DropBlock的主要细微差别在于,DropBlock中会有一些重叠,所以上面的方程只是一个近似值。
最后,来看看dropblock对推理过程的性能影响;
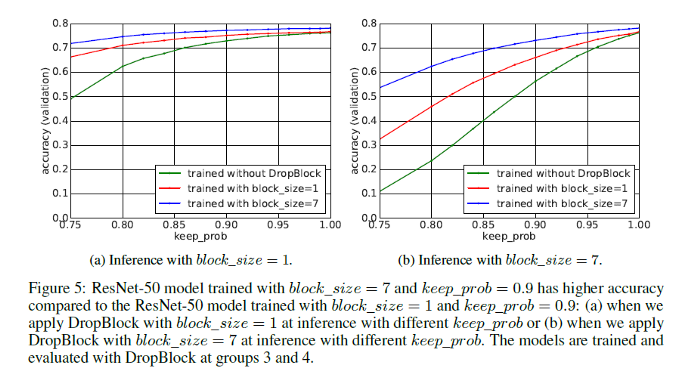
从上面的图中可以明显看出,与其他曲线相比,在绿色曲线(没有经过DropBlock训练的模型)的推理过程中,随着保持概率的降低,随着坡度越陡,验证精度会迅速下降。由于在block大小为1时,DropBlock与Dropout相似,因此,在block大小为1时,随着保持概率的降低,验证准确性迅速下降,DropBlock在删除语义信息方面更加有效。简单的理解:对于dropout中删除的单元,由于在邻域中可以“找回”,所以dropout对训练的影响“无关痛痒”;而dropblock恰好相反,即:影响较大。
另一方面,从上图得出结论:训练的时候,block_size相对大一点比较好,推理预测的时候,设置的小一点比较好。
Dropout已经被玩出花了。。。作者也很贴心的在文章里一个个说明跟比较。
一句话概括各种dropout方法:
Dropout [1]:完全随机扔
SpatialDropout [2]:按channel随机扔
Stochastic Depth [3]:按res block随机扔
DropBlock [4]:每个feature map上按spatial块随机扔
Cutout [5]:在input层按spatial块随机扔
DropConnect [6]:只在连接处扔,神经元不扔。
.........下一个在哪扔?
二、标签平滑方法
Label smoothing
在分类任务中,某个样本的one-hot(二进制串)标签为
即所属类别的置信度为1,其余类别都为0。比如在手写数字识别中,"7"的one-hot标签为:
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0]
Soft-Max与交叉熵:一般地,网络的经过FC层得到w、b等权重参数,在经过SoftMax就能得到一个多分类的概率分布(所有概率值之和为1),例如:
SoftMax预测值yi = [0.1, 0.8, 0.05, 0.05, 0];假定 label为:y_ = [0 1 0 0 0],将yi、y_代入交叉熵公式,便得到这两个分布的差异,交叉熵越小,表示yi、y_越接近,反之,你懂。在很多网络中,计算loss的时,采用的是交叉熵,
而不是MSE(交叉熵的loss形式便于求导);当然,在预测的时候,仅计算SoftMax。

回到正题:“当你认为绝对正确时,你可能就完全错了”——不知道谁说的。
比如:二分类,认为样本为正样本,标注为1,过于绝对,容易过拟合;好比一个人,过于自信,就是自负,一旦自负,迟早判断失误!
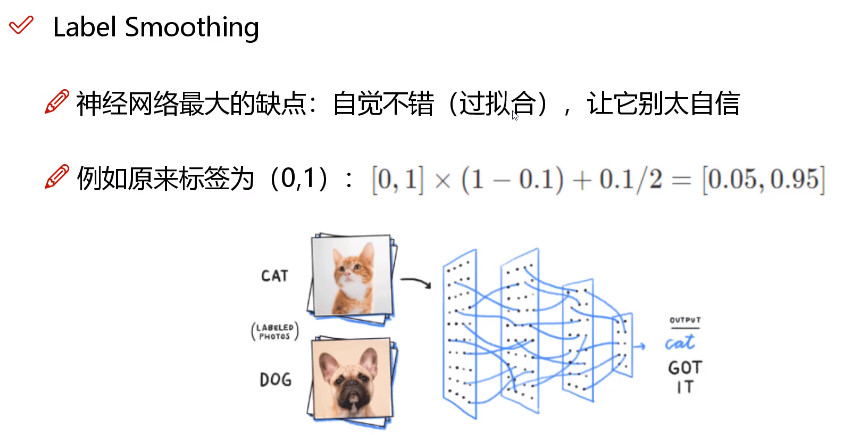
例如,将上述的(0, 1)定义为(0.05, 0.95),这样标签变得平滑,有种将离散变量转为连续变量的意思,类似于“像素插值”。
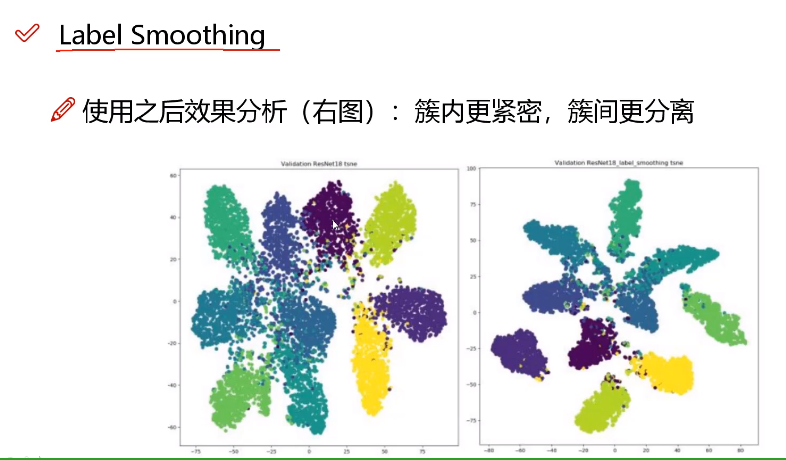
如上图,分别是标签平滑前后的样本分布图(聚类得到,仅为验证),左图,类别之间的“间隔”很小,靠近相邻空间的位置,可区分性小;模型容易过拟合,右边分类间隔大,可区分性大,类似与SVM中的“最大分类间隔”。
在训练过程中,模型习惯于对其预测结果“过于自信”,这会增加过拟合风险。另外,数据集中可能包含标注错误的数据,所以模型在训练过程中需要对标签持有怀疑态度。为此,可以在训练中引入一种标签平滑方法,将hard标签转换为soft标签(即1 → 1 - 平滑因子),来降低模型对标签的信心。soft标签为
其中 K 为类别数量, 为平滑因子它是一个很小的常数。假设平滑因子为0.09,则经过标签平滑后,"7"的one-hot标签变为:
# 平滑后各个置信度之和仍为1
[0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.91, 0.01, 0.01]标签平滑是一种正则化方法,可以防止模型在训练期间过于自信,降低过拟合风险。Label Smoothing参考代码:
1 class LabelSmoothingLoss(nn.Module): 2 def __init__(self, num_classes, smoothing=0.0, dim=-1): 3 super(LabelSmoothingLoss, self).__init__() 4 self.confidence = 1.0 - smoothing 5 self.smoothing = smoothing 6 self.num_classes = num_classes 7 self.dim = dim 8 9 def forward(self, pred, gt): 10 pred = pred.log_softmax(dim=self.dim) 11 with torch.no_grad(): 12 true_label = torch.zeros_like(pred) 13 true_label.fill_(self.smoothing / (self.num_classes - 1)) 14 true_label.scatter_(1, gt.unsqueeze(1), self.confidence) 15 return torch.mean(torch.sum(-true_label * pred, dim=self.dim))
reference:
dropblock:
https://zhuanlan.zhihu.com/p/142299442
https://my.oschina.net/u/1416903/blog/4537523
https://www.yuque.com/kjle6/feoy5e/qp2p4i
伯努利简单推导:
https://www.cnblogs.com/ehomeshasha/p/3820512.html
标签平滑:
https://zhuanlan.zhihu.com/p/239934468
dropout的综述总结:
https://www.zhihu.com/question/300940578/answer/523516718
SoftMax与交叉熵:
https://zhuanlan.zhihu.com/p/27223959