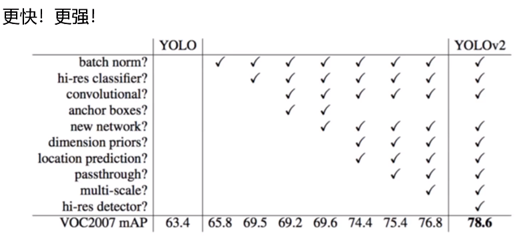
如下图,yolov2相对yolov1的改进点:
2.1 Batch-Normalization 归一化
在神经网络中,在全连接层中使用dropout能以降低过拟合风险,YOLOV2中舍弃了dropout。V2中没有全连接层,所有层都是一个卷积,每次卷积之后都加一个BN,即:每一层后面做一个归一化处理(使得mean=0,sigma比较小),这样做的好处是:容易收敛。舍弃dropout,改用BN,YOLOV2最终mAp提升了2.4%,如上图所示。站在今天的角度,BN已经成为网络必备处理。(V4中dropout改为了bropblock)
2.2 high-resolution classifier更高分辨率的分类器
V1训练时使用的是224*224(可能由于当时计算机性能有限,YOLO的出发点就是快),测试时使用的448*448。
V1中训练与推理时使用不同分辨率,可能导致“水土不服”。训练过程中,V2在V1的基础上额外加了10个epoch,进行448*448的微调,这种操作使得mAp提升了3.7%,如上图。
2.3 convolutional提出darknet
DarkNet≈VGG+ResNet
1) DarkNet实际输入为416*416
2) DarkNet没有FC层,5次降采样,(13*13)(FC层易过拟合;并且参数多导致训练慢)
3) 1*1卷积能够节省很多参数,可以调研下原理
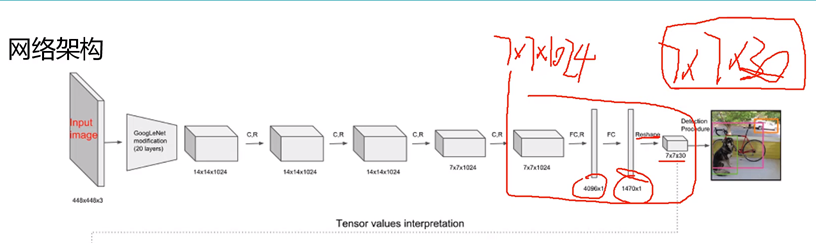
为什么V2选择删除FC层?
如下图V1的网络,红色框标注的是V1的FC层,它将7×7×1024的tensor变为7×7×30的tensor;注意到FC层中间数量优点恐怖;于是:V2采用卷积来代替V1中的FC层,一次性解决问题,参数大大减少
五次降采样:type列如下图(下面图有点错误,不影响说明问题哈)5个MaxPool降采样操作,每次降采样,featureMap的size为原来一半,所以五次就是缩小2^5=32倍,这样原图的输入尺寸必须被32整除。(输入416×416 = 32 * (输出13×13))
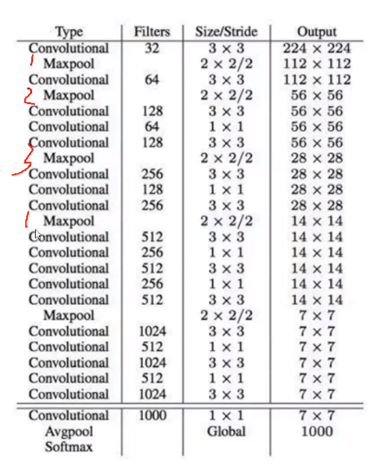
上图中,所有的卷积操作的卷积核size=3×3 or 1×1,其中3×3是借鉴VGG网络思想,认为小的卷积核(3×3)有参数少、感受野大的优点。
作者称上图为DarkNet-19,有19个卷积层;其中1×1卷积核仅仅改变网络特征图数量。观察上图Filters列,5次Maxpool之后,特征图数量翻倍(为什么翻倍?可参考Inception中1×1卷积的对FeatureMap的channel维度的升维、降维[1]),并且每次Maxpool之后都是多次卷积操作(特征浓缩),这些卷积中间夹杂着1×1的卷积核(而不全是3×3卷积),好处是:相对于3×3卷积,1×1卷积参数数量少,并对整体网络性能没有太大影响。
2.4 anchor boxes 先验框
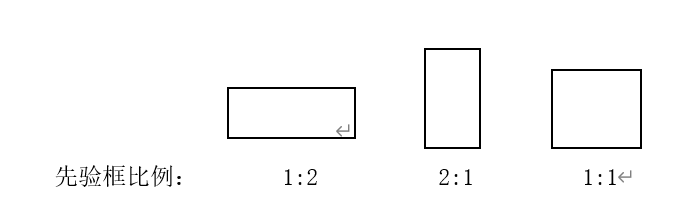
V1中指定每个cell中指定B=2个框,Faster-RCNN系列选者了9中先验框(三种分辨率的图中对应三种比例的框,比例为:1:2,2:1,1:1,分辨率越高,框越大),其长宽比例都是常规的,不一定适应于真实数据。
V2借鉴于此,进行改进;例如将coco数据集中所有目标对应框进行KMeans聚类(K=5),让算法自动生成目标框比例,而不是给出固定的比例,这样能够更加贴近客观情况。V2中聚类的时候,不是用的欧氏距离来定义差异(即:
((w1-w2)^2+(h1–h2)^2)^0.5)
而是用下式表示“距离”:
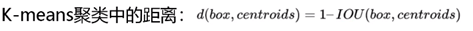
如果用上述欧氏距离公式,那么对于同一类目标,大物体和小物体将会和“几何中心”距离差异大,分在聚类不同类别。
如下图,作者进行了相关实验,随着聚类类别数量的增加,平均IOU值也会增加,类别间差异变化越来越慢;通俗讲:类别越多,IOU平均值越大(这是我们希望看到的,初始IOU越大,越有利于优化,网络更快收敛),收益越大;但是,随着聚类类别越多,IOU增长变慢,并且先验框也不可能无限增长下去,于是作者取了个折中,令K=5(取5也应该经过了严格测试)。
所以在V2中,一个cell中对应B=5个先验框。如下图是聚类结果:

V2相对于V1先验框多了3个,但是mAP降了一点点。因为先验框多了,能够得到的候选目标也多了,错误发生的可能性也变大,但rcall却极大地提升。通俗讲:先验框多了,能够召回更多目标,准确率几乎不变 。

2.5 Directed Location Prediction直接预测cell局部框
V1 中,先给出框的先验证值(xp yp wp hp),则有:
x = xp + wp*tx; y = yp + hp*ty;
上述式子中,x y tx ty都是待优化的变量,其中tx、ty表示框的偏移;在V1中先验框的初值给得不一定就很恰当,同时优化过程中,tx、ty也有跑偏的情况,导致最终框偏移目标太大,就是:跑偏了。
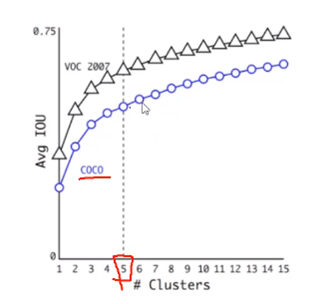
V2版本中,改进了上述缺陷,将上述tx ty相对中心点的偏移量修改为相对cell的偏移量,这样最终的检测框一定对包含cell。如下图,黑色虚线为先验框,蓝色实线为预测框。对于预测框的中心点(bx,by),我们定义目标函数为:
bx = sigma(tx)+cx
by = sigma(ty)+cy
其中sigma表示sigmod函数,可以将tx变化范围限制为(0,1),这样中心的预测永远不会超出如图cell,cx、cy为当前cell左上角在原图的偏移坐标。对于预测框的宽、高(bw,bh),V2通过聚类给出先验值(pw、ph),计算公式也很简单,如下图。
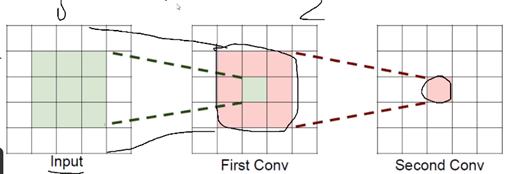
2.6 感受野
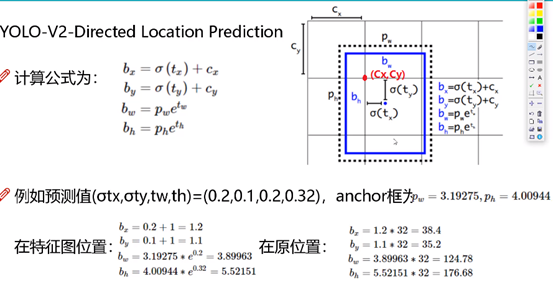
什么是感受野?对于输入一张图,我们做卷积、MaxPool等操作,特征图的size会越来越小,如下图最终特征图的一个单位u是由原图较大的一块区域(记为:r)经过“浓缩抽象”得到,那么区域r就是单位u的感受野。
在CV中,大的感受野关注大的目标,例如:DL中常有如下处理:
输入图像->conv1->conv2->conv3
conv1:关注纹理、色彩、线条等浅层特征;
conv2:关注高级特征
conv3:关注全局特征
为什么卷积过程中都是3×3,而不是5×5,甚至更大?
如下图:原图是5×5×1,经过2次conv得到最终特征图。同理,现在假定input原图为7×7×1,得到如下图最右边的最终特征图,我们有两种方式:
方法一:经过3次3×3卷积处理;
方法二:经过1次7×7卷积处理。
假定上述input原图size为:h×w×c,现在采用c个卷积核(得到c个特征图),上述方法一需要参数个数为:
3×c×(3×3×c)=27×c×c
(第一个3:卷积次数,注:现在卷积是立体空间操作,不是平面,且c个通道都是立体卷积)
上述方法二需要参数个数为:
1×c×(7×7×c)=49×c×c
显然,方法一参数要少。
3×3卷积好处:
1、节省参数
2、卷积次数多,特征提取也会越细致,加入的非线性变换也越多;这是VGG网络的思想:用小的卷积核完成体特征提取操作。
2.7 Fine-Grained Features特征图优化
上一节讲述了感受野,神经网络最后一层感受野太大,也即:对应着原图的大目标,小目标信息丢失,这时候需要融合之前的特征。我们说最后一层感受野很大,越往前,之前特征图对应感受野越小, 所以想要检测小目标,就要融合中间特征图的信息。
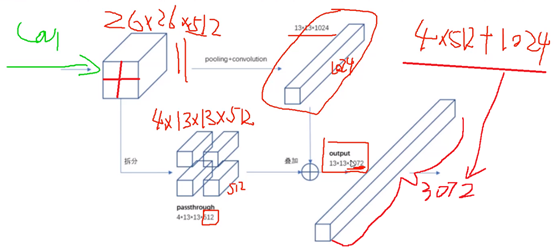
如下图,pooling+conv之后,得到13*13*1024的最终特征图;同时将其前一层特征图进行拆分,拆分为4个13*13*512的特征图和上述13*13*1024的特征都堆叠在一起,得到13*13*3072的特征图,其中3072 = 4*512 + 1024。
2.8 Muti-Scale
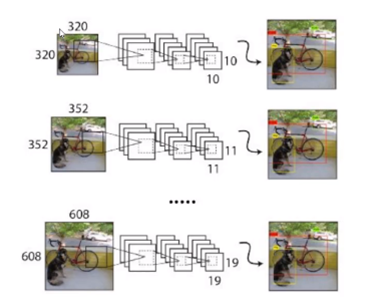
在V2的darknet中没有FC层,只有卷积层,所以对输入图像分辨率无限制(分辨率宽高必须是32倍数,原因是5次降采样),V2中,训练迭代过程中,会改变图像size,如下图三种分辨率,能够提升网络模型对尺度的适应性(尺度:距离近,目标大;距离远,目标小)。mAp值能够提升1.6%。
refence: