1.1 YOLOV1概要
如下图,2015年的时候,Faster R-CNN的性能在目标检测算法中已是巅峰,但是FPS很低,部署硬件代价高(TITAN X级别的GPU),这是DL产品化的最大障碍之一。YOLO-V1的出现,能够有效解决这一难题(2020年YOLOV5已经完美解决这问题)。回顾历史,YOLO系列的更新迭代总是给业界带来惊喜(又准又快,模型越来越小,最小1Mb),这也是为什么工业界钟爱YOLO的原因。
回到2015年,如下图,相对Faster R-CNN,YOLOV1的mAP相对落后,但FPS却提升9倍,当时的R-CNN系列在目标检测领域,属于主流算法,备受好评。

YOLOV1核心思想:
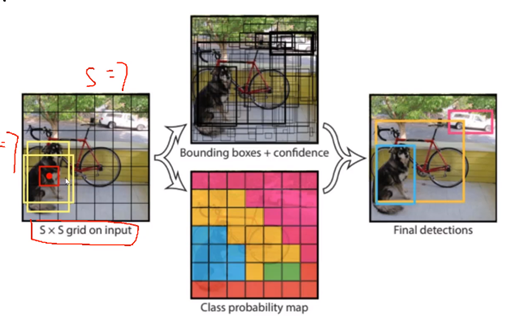
如下图,V1中在7×7的格子中,每个格子给出1个概率值,以格子中心点为起点,通过回归找到B个候选框(V1中,候选框数量B=2),通过对比候选框与标签间的差异(IOU, Confidence),筛选一个最佳目标区域。
1.2 网络架构
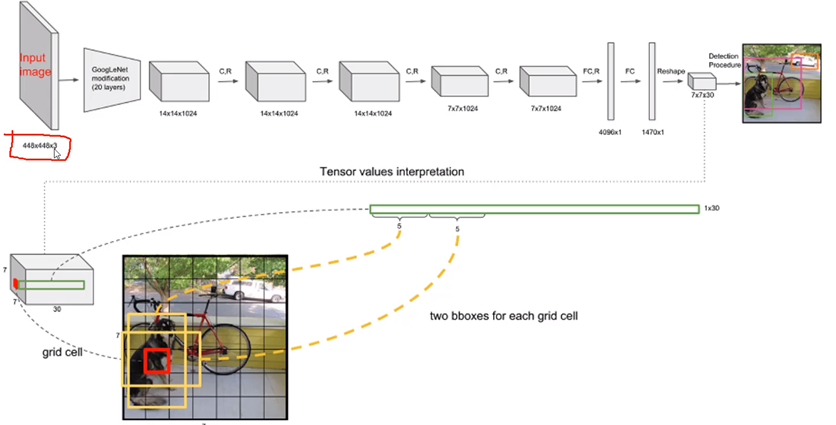
如下图,V1版本中,限制了输入图像只能是:448×448×3(网络只能接受固定大小图像,原因是:由于全连接层FC中的权重矩阵的size是固定的;相反ConV曾对于任何分辨率都能处理,V2中去除了FC层)。
下图中,卷积层:GoogleNet+4个C.R,得到7×7×1024的feature Map;后续经过全连接层,得到1470×1个特征,经过reshape,得到7×7×30。
对于7×7×30,其中7×7表示分割网格;每个格子有30个值,由于每个格子仅检测两个候选框,所以上述“30”表示:B1(x1 y1 w1 h1 c1), B2(x2 y2 w2 h2 c2),这就有10个值了;剩余20个值表示对20分类的概率值(例如:猪、狗、牛、羊等20个类别)。
(注:这里x、y、w、h都是相对原图进行了归一化)
小结下:再对7×7×30解释下,如下图:

YOLOV1中定义:S = 7, B = 2, C = 20
1.3 目标函数
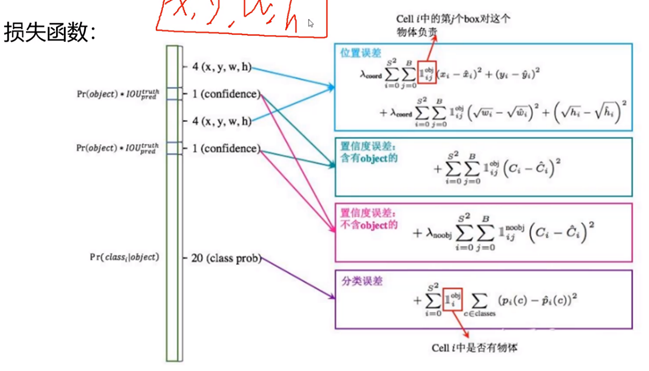
位置误差:其中S = 7, B = 2,后面w、h开根号是一种数据处理方式,使得损失函数更加注重小目标,因为相对于大目标(w、h值更大),小目标的w、h值太小,不易优化到一个好的结果。前面系数是一个权重项。
置信度误差::
下面计算是NMS过程所用到,后面两项:Pr(Obejc)*IOU才是置信度计算公式。(IOU两个功能:1、过滤重复框(预测);2、参与计算置信度(训练);V2中IOU还用在计算K-Means中的距离),(以下公式其实NMS得分计算公式)
![]()
在了解置信度误差之前,必须知道图像中主要有包含目标(前景)、不含目标(背景)。假定以下条件,求IOU得分
- 检测到2个候选区域B1、B2,与label框间的IOU分别为0.9,0.5;
- 设定NMS得分阈值为0.5;
- B1,B2对应的cell概率值(P(Classi|Object))为:0.8)
- B1,B2对应有目标的概率(P(Object))分别为:1、1
这时候,依据上图公式,B1、B2对应的NMS得分为:0.8 * 1 * 0.9 = 0.72; 0.8 * 1 * 0.5 = 0.4
由于B1的NMS得分大于阈值且最大,所以候选框B1就被判定为前景。其他情况NMS得分小于0.5的时候都是背景。在数值上,NMS得分 = IOU,所以很多地方在描述的是时候说的是:依据IOU值能够去除冗余框。
一般地,绝大多数格子不包含目标,即:背景数量远远大于前景数量,也就是:正负样本不均衡,所以如上图第三个公式(品红色),加了一个权重系数,以此来平衡两个置信度误差大小对整个目标函数的影响。在VOC数据集中有(这样设置可以解决正负样本(前景、背景)不均衡问题)
![]()
注:置信度仅针对BoudningBox,和后续20个概率值没有联系,20个概率值针对的是cell网格属于20个类别的可能性。
回到上图公式中,
Pr(Object):候选框(bounding box)存在对象的概率;
Pr(Classi|Object):如果当前网格(cell)存在对象,是类别i(i=1 2 …20,一共20个类别)的概率;
上述两个相乘就是条件概率了。
上式第3项:表示预测框(也就是两个候选框)与label框间的IOU。
上式左边第2、3项乘积(bounding box的置信度):是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该bounding box准确度的信息。对于没有目标时,Pr(Obejct)=0,上述整个都是0。
上述公式
分类误差:如上图,第五个公式(分类误差那一项)中的概率值,也就是上述公式左边第一项Pr(Classi|Object),仅仅针对cell。
最终的损失函数就是将上述四项加在一起进行梯度下降优化,后续V2、V3大体如此。
NMS:置信度大于阈值时,按大小排序,保留最大的框,其余删除,去除重复框。
上述涉及到的两个概率值怎么计算?
应该是经过FC层经过SoftMax和交叉熵得到各个类别概率,选择最大值作为其预测类别。(这一点在调试YOLOV5源码的时候,已经得到验证)
1.4 流程总结与归纳
1.4.1要点总结

NMS计算公式:
![]()
置信度误差中的C计算公式:
Pr(Object)*IOU(针对bbox)
分类误差计算公式:
Pr(Classi|Object)(针对cell)
YOLOV1中,每个cell的B=2个先验框不是预设的,而是网络迭代优化自动计算的,框的位置信息的训练是一种"非监督学习"。
1.4.2 流程总结
以优化下图中自行车为例子,来总结下YOLOV1的前向传播算法流程:
- Step1:神经网络输入一张图。

输入图
- Setp2:图片经过网络的到7×7×30的tensor,30 = (4 + 1 + 4 + 1+ 20)。如下图30维度张量示意图。这一步,我们计算出了自行车对应的cell(通过中间计算P(object))、两个候选框(x、y、w、h、confidence)、20个类别条件概率。后续这个cell就负责附近的自行车,其他cell不会“插手”。
4表示:w、h、x、y;(两个候选框)
1表示:confidence( 公式:P(Object)*IOU;针对bbox);
20表示:对20个类别的概率(公式:P(Classi|Object),i = 1、2、3......20;针对Cell);
举个例子:在数据标注的时候,confidence定义为:假如先验框和候选框IOU大于阈值,那么P(Object) = 1,反之P(Object) = 0;容易知道,在数值上confidence = IOU,这一点容易混淆。
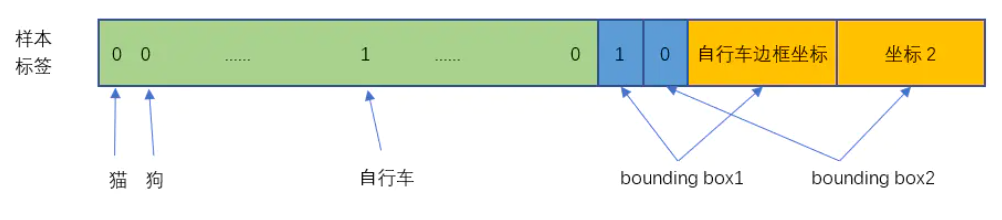
Label-自行车cell对应30维度张量
- Step3:在当前epoch中,计算两个候选框与标注框间的IOU,大的判定为前景(后续训练前景也都要通过IOU决定,所以后续epoch中,前景是依据IOU动态决定得的)。如下图,这里计算得出自行车的概率值最大为:0.6,两个候选框的置信度为0.7、0.2(她两对应的P(Object) = 1),显然选择候选框1为前景,所以下面损失函数公式中第一、二行对应的优化变量就是选侯选框1的数据。

第N个epoch网络输出-自行车cell对应30维度张量
- Step4:通过前面三个步骤,我们可以计算损失,loss公式如下:

上式中:意思是网格i中存在对象。
意思是网格i的第j个bounding box中存在对象。
意思是网格i的第j个bounding box中不存在对象。
pi(c) = P(Classi|Object),i:第i个cell
Ci = P(Object)
(小结:在计算loss的时候,先算上述公式1、2、5行,对于3、4行,根据置信度(也就是IOU)来决定要不要算。但在实际中,就算候选框没有目标,作者
也还是计算了,只不过将第4行前面个的系数λnoobj设置得很小(前面讲过)。)
- Step5:反向传播、更新网络参数、迭代优化,重复上述步骤。
1.4.3对YOLOV1的评价
优点:快速、简单。
缺点:
1、每个格子仅能预测一个物体,对遮挡、重叠效果不好;
2、小物体检测效果不好(由于只有两个先验框,仅对大物体较好),查高宽比可选,但是单一
3、多标签无法解决(例如:一条狗对应多个标签:狗、牧羊犬类、动物等
[2] https://www.jianshu.com/p/cad68ca85e27