转载请附原文链接:http://www.cnblogs.com/wingsless/p/5578727.html
上一篇中我简单的分析了一下InnoDB缓冲池LRU算法的相关源码,其实说不上是分析,应该是自己的笔记,不过我还是发扬大言不惭的精神写成分析好了。在此之后,我继续阅读了Buf0rea.c文件,因为这里写的就是如何将block读取到内存中的函数。
这个文件里很显眼的有这样一个函数:buf_read_page,这是一个高层的函数,它的作用就是:reads a page asynchronously from a file to the buffer buf_pool if it is not already there。采用异步的方式将文件中的页读入buf_pool。大体上看一眼这个函数,发现它主要搞了以下几个工作:
1 随机预读(buf_read_ahead_random)。随机预读是一个可以提高效率的策略,它的主要思想是:给定的space和offset确定的那页,可以计算出一个范围,如果这个范围内的页(pages)有一部分已经被访问(阈值:BUF_READ_AHEAD_RANDOM_THRESHOLD),那么这个范围内的页(pages)就会被预读。看一下函数内是怎么写的:
//确定一个边界,边界内的页,都要进行条件判断
low = (offset / BUF_READ_AHEAD_RANDOM_AREA) * BUF_READ_AHEAD_RANDOM_AREA; high = (offset / BUF_READ_AHEAD_RANDOM_AREA + 1) * BUF_READ_AHEAD_RANDOM_AREA; if (high > fil_space_get_size(space)) { high = fil_space_get_size(space); } 省略部分...
//对边界内的页进行条件判断 for (i = low; i < high; i++) { block = buf_page_hash_get(space, i); if ((block) && (block->LRU_position > LRU_recent_limit) && block->accessed) { recent_blocks++; } } mutex_exit(&(buf_pool->mutex)); if (recent_blocks < BUF_READ_AHEAD_RANDOM_THRESHOLD) { /* Do nothing */ return(0); } 省略部分...
//如果之前的判断都通过,则函数可以进行下面的步骤
//边界范围内的每一个页都会被预读:(buf_read_page_low),预读采用异步的方式 for (i = low; i < high; i++) { /* It is only sensible to do read-ahead in the non-sync aio mode: hence FALSE as the first parameter */ if (!ibuf_bitmap_page(i)) { count += buf_read_page_low( &err, FALSE, ibuf_mode | OS_AIO_SIMULATED_WAKE_LATER, space, tablespace_version, i); if (err == DB_TABLESPACE_DELETED) { ut_print_timestamp(stderr); fprintf(stderr, " InnoDB: Warning: in random" " readahead trying to access " "InnoDB: tablespace %lu page %lu, " "InnoDB: but the tablespace does not" " exist or is just being dropped. ", (ulong) space, (ulong) i); } } }
满足条件的页就会被预读,注意预读采用异步的方式,同时,(space,offset)指定的页,也会被预读。这里是一个我有点搞不明白的地方,这个页既然被异步预读了,后面还会在同步的读取一次,且听后话。
2 物理读取。预读结束之后,buf_read_page函数就会调度buf_read_page_low函数,进行数据的读取,注意这个函数刚才预读的时候也使用过,但是这次采用同步的方式,注释写的很明白:“ We do the i/o in the synchronous aio mode to save thread”。这个函数还会在给block->frame加x-lock锁,这个操作会在函数调度下一级函数buf_page_init_for_read的时候进行,代码:rw_lock_x_lock_gen(&(block->lock), BUF_IO_READ)。而buf_page_init_for_read函数的主要作用就是从LRU里分配一个buf_block_t*,并对这个buf_block_t*加x-lock锁。我主要看到了这几行:
//分配一个buffer block
block = buf_block_alloc();
//向buffer pool中初始化一个page buf_page_init(space, offset, block);
//将block插入LRU链表中,只能插入old链表 buf_LRU_add_block(block, TRUE); /* TRUE == to old blocks */ rw_lock_x_lock_gen(&(block->lock), BUF_IO_READ);
注意,buf_read_page_low函数中最后有这样一段:
if (sync) { /* The i/o is already completed when we arrive from fil_read */ buf_page_io_complete(block); }
如果是同步方式,那么就用buf_page_io_complete函数释放所有的x-lock:rw_lock_x_unlock_gen(&(block->lock), BUF_IO_READ);
3 物理读取结束之后,会调度buf_flush_free_margin函数,在需要的情况下,flush掉LRU链表的尾部。
总结一下上面的步骤,发现这是地地道道的物理读取,即从磁盘中将数据读取到内存中。在《MySQL内核--InnoDB存储引擎》一书的12章里还介绍了一种读取方式叫做逻辑读取,现在分析如下。
从书中的描述里看,我觉得这个叫做逻辑读取有点不好理解。个人觉得这个逻辑读取其实就是一个流程:
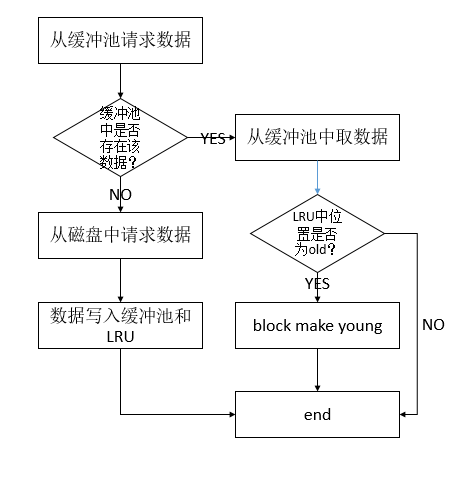
基于我的理解画的,可能有疏漏的地方。这里就需要看这个函数:buf_page_get_gen,它的注释也写得很明白:This is the general function used to get access to a database page。提供了一个访问数据库页的通用方法。
这个函数有个很有意思的地方就是它的入参里有很多的mode,这就给该函数带来了许多种可能的返回。我无心看这些,但是有一个地方却很吸引我,就是一个goto。学C的时候老师说,goto是C语言历史上臭名昭著的一个关键字,大家初学,千万别用。但是又有持不同意见的人认为善用goto能带来意想不到的效果,我相信MySQL的作者们goto用的非常好。
函数中有一个loop标记,也就是说函数是循环着读取block的,直到满足一些条件。首先会从缓冲池里寻找:block = buf_page_hash_get(space, offset),没有的话就会使用这个函数:buf_read_page(space, offset)将block读入,然后goto到开始的地方,将block置为NULL,重新开始,这次就能从缓冲池里找到block了。下面的代码是很多的判断,不过这里很显眼:
mutex_exit(&buf_pool->mutex); /* Check if this is the first access to the page*/ accessed = block->accessed; block->accessed = TRUE; mutex_exit(&block->mutex); buf_block_make_young(block); 省略部分... if (!accessed) { /* In the case of a first access, try to apply linear read-ahead */ buf_read_ahead_linear(space, offset); }
这里判断了block是不是第一次被访问,但是很奇怪,这个block立刻就被make young了,这和我以前的认知倒是不太一样了,不过这篇淘宝丁奇的博文(https://yq.aliyun.com/articles/8827)里写到了这一点,可以参考一下,经过我的分析发现,make young也不是那么笨的,它要判断这个block是不是需要被make young(if (buf_block_peek_if_too_old(block)))。如果是第一次被访问,就会触发线性预读函数的调用。
终于说到了线性预读。留着明天写吧。
看代码果然过瘾啊。